Semantic-oriented linguistic
processor for knowledge extraction from texts in Russian and English
Igor P. Kuznetsov
Institute
for Informatics Problems of the Russian Academy of Sciences, Moscow, Russia
Abstract The paper is
dedicated to one approach to the automatic extraction of the knowledge from
natural language texts (Russian and English) with forming the Knowledge Base.
It is used for the solution of the most complex problems of the linguistic
processors and logical-analytical systems.
For this purpose the means of knowledge representation (the extended semantic networks -
ESN) and the tools of their processing (the language of logical programming
DECL) have been designed. On this basis have been proposed universal
syntactical semantic rules and ontologies which are composed the universal
linguistic knowledge for knowledge extraction and which have been used for
construction of many intellectual systems for different applications.
Keywords semantics,
natural language, linguistic processor, knowledge extraction, named entities
1 Introduction
The existing Internet
largely consists of unstructured documents. Knowledge contained within these
documents can be made more accessible for machine processing by means of
transformation into form to be reasoned with. More prospective approach consists
of using Knowledge Base. It proposes the development of new technology including
the extraction of knowledge structures and organization of their processing in
Knowledge Base [1,2,4].
The distinctive
features of our technology are as follows:
1. Extraction from the texts of knowledge structures (not only separate named entities) that represent the links of named
entities and their participation in actions and events.
2. For the knowledge extraction the unique
semantic-oriented language processors (LP) are designed. Processor LP provides
the deep analysis of NL-texts and revealing set of entities together with their
structures.
3.
Processor LP is controlled by the linguistic knowledge, which are declarative
structures (on extended semantic networks - ESN) and which provides the quick
tuning of LP to subject area and language - Russian and English.
4.
Linguistic knowledge consists of the rules, which provide the high degree of
selectivity in the entities extraction and elimination of collisions during
their application. Rules provide the minimization of noise and losses, that is
the high degree of completeness and accuracy.
5. The knowledge structures and means of their
processing (intellectual language DEKL) were designed as the united tools, oriented at the tasks of linguistic analysis, semantic search,
logical-analytical processing and the expert solutions. Using this tools
considerably facilitates the development of applied intellectual systems.
Technology of knowledge structure extraction
and processing have been used for construction of new classes of analytical
systems [3,7,12,13]: “Criminal”, “Analytic”, “AntiTerror”, “Resume” etc.
[http://IpiranLogos.com/en/Systems/].
2 Tools for intellectual processing
2.1. Extended semantic
networks
For knowledge
representation was proposed the Extended semantic networks (ESN) [2,3,4]. Constructions of ESN is used
paradigm in which the model of the external world is quantized to the objects
and the relationships between them. At the same time the integration of objects
is allowed when from simple objects is possible to build more complex. The reverse process is the specification. In each
object can be selected parts connected by certain relationships. This is easily
expressed in the natural language (NL) and should be presented in knowledge.
Extended semantic networks have been designed on the base of this paradigm.
Extended semantic networks (ESN) are composed from fragments of following type:
<Relation
name> (<arg1 "," arg2>, ..., <argN> / <code of
fragment>)
where <arg1 "," arg2>, ..., <argN> are the argument
places, which may be occupied by constant, or the number of variables, which
may be corresponded the named entities (information objects). Code of fragment
corresponds to a complex object, i.e. arguments with their relationship, which
are considered as a whole. The "relationship" is considered in the
broad sense. Unary relation (with one argument) is a property. Binary relation
connects the two objects, and N-ary connects more objects. For example, N-ary
relation can be an action in which N objects took part (with different roles).
Codes of fragments are needed to represent the
level of integration. Code of fragment may be a constant, which must be
"unique", i.e. it cannot be a code of another fragment.
Code fragment may be missing in the record (the
internal representation it always is). Then the fragment will take the simpler
form <Relation name> (<arg1>,<arg2>,
...,<argN>).
Not difficult to see that the fragments have the
form of named predicates, where the code fragments are the unique name of a
predicate. Many fragments are composed the extended semantic network (ESN). The
order of the fragments in the ESN does not matter. It should be noted two
features.
The first feature is the using so-called
intersystem constants. They are written in the form of numbers with a plus sign
(N +), where the constant is introduced, and a minus (N-), when used. For
example, two fragments NAME(IVAN, 1 +) STRONG (1 -) is presented that " a man named Ivan is strong." In
this case, if we again encountered a number 1 +, it introduce a new (different)
constant. For example, the fragments NAME(IVAN, 1 +) STRONG (1 -) NAME (PETER,
1 +) BRAVE (1 -) WEEK(1 -) are presented two people: "Ivan is strong, and Peter is brave and week." Instead of sign
1+ and 1- can be any integer (N), i.e. 2 +, 2 -, etc. Intersystem constants are
needed to refer to objects that are defined by their properties, relations or
presented implicitly. If the text has the two objects named Ivan, it can be different people and
they are presented in ESN by different constants. It is a difficulty procedure
to choose their different mnemonics.
Second feature is the following. The code of
fragments (usually intersystem constants) can stand on the argument places of
other fragments. This is necessary in the cases when some objects are
components of others. For example, the fragments NAME(IVAN, 1 +) BUY (1 -, BOOK
/ 2 +) DECIDE(1 -, 2 -) are presented "Ivan
decided to buy the book",
where there are two actions. In this one (DECIDE) includes another (BUY). Every
named entity (NE) may be the component of action or another objects. Because every NE is presented as fragment of
ESN with own code (see 3.3).
Described features (when some code fragments can
be on the other argument places) greatly increases the possibilities of
language ESN for representation of different types of information, including
the semantic components of NL-construction. They are widely used for describing
events and actions by forms with verbal nouns, participial and other
constructions. It’s significant that these features make the possibilities of
language ESN far beyond the classical language of predicate logic. For example,
it is possible by ESN the representation of the various types of paradoxes
which are typical for the NL, but impossible in the logic [1]. Constructions of
ESN are composed the United Knowledge Base which are used for subject and
linguistic knowledge and which determines the logical analytical decisions and
the work of linguistic processor.
2.2.
Logical programming language for knowledge processing
For processing the knowledge
structures, presented by ESN, the special language of logical programming
(DECL) has been constructed [2,3]. Language DECL was used as base for
programming the linguistic processor (LP) which transforms the surface (space)
structures of texts to deep (semantic) structures where presented named
entities and their relationships.
The language DECL consists of
the rules IF ... THEN ..., called productions. Productions are applied to the
knowledge base (KB) and have the form:
<Name products> (...): IF <LfP> THEN
<RgP>;
where LfP is left part of the production and RgP is right part. Both parts
consist of a set of fragments of ESN, which (in addition to constants) may
contain variables. Fragment <name products> (...) is necessary to call
the production application.
The left part (LfP) of production
sets the conditions for its application. If the conditions took place (analogical
structures are in KB) then production is considered to be applicable. As result
the variables in LP take the values and activated the right part.
The right side of (RgP) products determines
the actions concluded in transformation of structures in KB . If the products
was applicable then the actions are initiated. Values of the variables are transferred from the LfP to RgP and take into
account in actions.
Parts LfP and RgP contain not only
fragments, but also special operators to call productions (by name), and the
so-called special fragments (or build-in predicates) that define references to
external procedures, for example, the interface programs.
The condition of their application
consist in compare the fragments of LfP with fragments of KB. If the
corresponding structure in the KB is found, the product is considered to be
applicable and values of variables from LfP are transmitted to RgP and take
into account in the actions. If RgP has a fragment, then it is added to the KB
[http://IpiranLogos/en/Tools/].
3. Representation of semantic structures
3.1 Type of entities and links for
extraction
Named Entities (NE) are extracted from
the documents on Natural Language (NL) by linguistic processor (LP) and
presented in the Knowledge Base (KB) as the fragments of the extended semantic
network (ESN). The arguments of fragments are the collections of normalized
words, numbers and signs, which reflect essence of NE and indicate to its type.
In our systems more than 40 types of NE
are extracted from NL-texts [1,7,8]. Their quantity depends on the subject area
and the tasks of users. Let us note that in KB some NE can be constitutional components
of others. Connections between NE may be complicated [1,6,14 ]. We consider
that actions with their objects and components are the kind of NE, which are
connected by special relations (time, space, reason and so on) with other
actions. Apparatus ESN have been designed for the representation such
information on homogeneous base. It is necessary for deep computer processing
of NL-texts – Russian and English [1,10].
The set of the entities to be extracted
depends on the tasks of a user. At the same time the quality of a linguistic
processor is determined by the possibilities for knowledge extraction. The linguistic processors of
systems “Criminal”, “Analytic” and ‘’Semantix” support more than 40 types of
semantic entities which can be extracted automatically.
Standard entities (names, dates,
addresses, types of weapons and others) are reduced to one standard form. The
identification of entities is performed taking into account brief designations
(for example, separate surnames, patronymics, Initials), anaphoric references
(indicative and personal pronouns, for example, this person, it...) definitions
and explanations (for example, the mayor
of Moscow Sabyanin is identified
with the subsequent words mayor, Sabyanin). An important task is the
identification of entities in the entire text, the use for these purposes of
indicative pronouns, brief names, anaphoric references.
Graph presentation of some extracted
entities is showed on fig 1.
Fig. 1 Some extracted
named entities
3.2. Connections
between the entities and participation in actions
Connections and relations between NE, extracted from the NL-texts, can be very diverse. They
depend on entity types. For example, one person can be connected with another
by relative and friendly relations, and also by the place of living, area of
interests and so on. Actions frequently are connected with the time and the
place. There can be reason-consequence and other connections between actions. In
such a way the complex structures are created. For their formalization special
tools of knowledge representation have been designed.
Actions usually
are expressed in NL-texts by the tensed verb forms, nonfinite verb forms, e.g.
verbal nouns, participial and adverbial constructions, gerunds. The actions are
also NE, components of which can be another NE. For example, there can be
those, who participate in action, or entities, on which the action is directed.
Moreover, some actions may be components of others. For many applications the
actions are also the significant information which requires formalization. Because
the system is oriented at the deep analysis of text constructions, it extracts all actions
and events with NE.
3.3. Meaningful portrait of a
document
It is the formal representation of
entities (NE), their properties and the connections, extracted from the text of
the document. Such portraits are the structures of knowledge. As means of
formalization in our technologies we use the extended semantic networks (ESN).
Formalization is achieved automatically by the semantics-oriented linguistic
processor, which analyzes the texts of NL-documents and transforms them into
knowledge structures [1,2,9].
A set
of meaningful portraits (together with
index files) comprise the Knowledge Base (KB) where various types are provided of
semantic search and logical-analytical functions by comparison and
transformation of knowledge structures. We design the technology which provides
the processing in the KB distributed within the net of computers.
The Example of text (with number 66 from file Terr_doc.txt) :
12:16
27.12.2002 One of leaders of insurgents - Arabian Abu-Tarik is
destroyed
in the Chechen Republic
In the Chechen Republic one of leaders of
bands the Arabian mercenary
Abu-Tarik
- assistant of Abu al-Valod, successor of Hattab, is
destroyed.
As have informed the Ministry of Foreign Affairs of the
Chechen
Republic, joint forces of Chechen special militia and
divisions
of federal forces destroy the insurgent in settlement Starye
Atagi of
Groznensky region.
Meaningful portrait of the text:
DOC_(66,TERR_DOC.TXT,"SUMMERY;"/0+) 0-(ENG)
DATE_(#27.12.2002,2002,DEC.,~27,12,HOUR,16,MINUTE/1+)
CRIM_GROUP(1,LEADER,OF,INSURGENT/2+)
FIO("ABU - TARIK"," "," ","
"/3+)
DESTROY(ARABIAN,3-/4+) 4-(66,ACT_)
PLACE_(CHECHEN,REPUBLIC/5+)
WHERE(4-,5-)
CRIM_GROUP(1,LEADER,OF,BAND,ARABIAN,MERCENARY/6+)
FIO(ABU,AL-VALOD," "," "/7+)
FIO(HATTAB,HASAN," "," "/8+)
SUCCESSOR(7-,8-/9+)
ASSISTANT(7-,3-/10+)
ORG_(MINISTRY,OF,FOREIGN,AFFAIRS,OF,CHECHEN,REPUBLIC/11+)
INFORM(11-/12+) 12-(66,ACT_)
FORCE_(JOINT,FORCE,OF,CHECHEN/13+)
FORCE_(SPECIAL,MILITIA/14+)
FORSE_(DIVISION,OF,FEDERAL,FORCES/15+)
DESTROY(13-,14-,15-,INSURGENT/16+)
16-(66,ACT_)
PLACE_(SETTLEMENT,STARYE,ATAGI,OF,GROZNENSKY,REGION/17+) WHERE(16-,17-)
SENTENCE_(66,1-,2-,4-/18+) 18-(1,1,107)
SENTENSE_(66,5-,6-,3-,10-,7-,9-,8-/19+) 19-(3,108,253)
SENTENSE_(66,12-,16-/20+) 20-(5,254,471)
A meaningful portrait consists of the elementary fragments, arguments of
which are words in the normal form (it is necessary for the search and
processing). Each elementary fragment has its unique code, which is written in
the form of the number with the sign + and is separated by a slash line. For
example, in the fragment FIO("ABU - TARIK"," "," ","
"/3+) the sign “3+” is its code (but “3-” is the reference to it).
Fragments DOC_(22, TERR_DOC.TXT”, “SUMMARY; ” /0+) 0-(ENG) indicate that the
meaningful portrait is built on the basis of the English-language text of
document with number 66 of the file of TERR_DOC.TXT”, which was processed as
the summary of the incidents (linguistic knowledge depends on this). The
following fragments present date DATE_(…/1+), criminal group CRIM_GROUP(…/2+),
person’s surname (name and patronymic) FIO(… /3+) and so on. The signs “1+”, “1-”
and “2+”, “2-” and “3+”, “3-”, … are the
codes of the fragments, corresponding the NE.
With the aid of the codes the connections and relations of NE are
assigned. Actions are represented in the form of fragments of the type DESTROY(ARABIAN,3-/4+) 4-(66,ACT_), where it
is represented as “ arabian person
(FIO with code “3+”), are destroyed”. Fragment 4-(66, ACT_)
indicates that the first fragment DESTROY(…./4+) presents the action and
relates to the document with the number 66. Fragments PLACE_(CHECHEN,REPUBLIC/5+)
WHERE(4-,5-) indicate the place of this action (WHERE). Fragments ORG_(…/6+) INFORM(6-/7+)
7-(66,ACT_) represent that “organization
… was informed”.
The fragments PREDL_(...),
which correspond to the sentences play the special role. They are filled up
with the words, which did not enter into the named entities (in this example
they are absent), or with the codes of entities themselves. To these fragments
the indicators of their position in the text are added. For example, the
fragment SENTENSE_(66,12-,16-/20+) 20-(5,254,471) represents the fact that the entities
with codes “12-” (corresponding to the action “inform”), “16-” (corresponding the action “destroy”) are located in the sentence, which begins from the 5th
line of the text of the document and they occupy the place from the 254-th to
the 471-th byte. These means of positioning are necessary for the work of the
reverse linguistic processor.
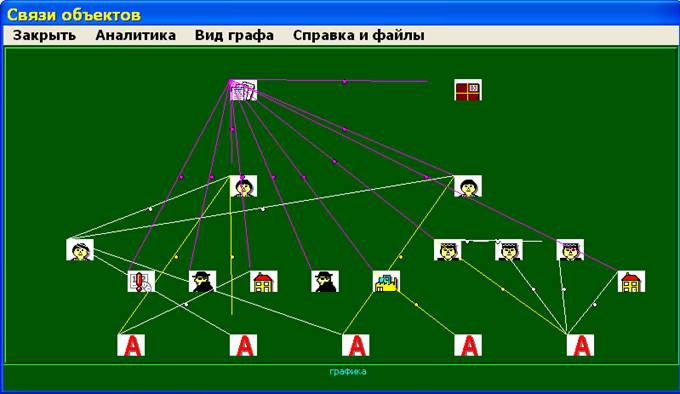
Fig. 2 Graph of meaningful
portrait (in system “Criminal”)
On
this graph the upper node corresponds to the document. Central node presents
the document. Criminal groups are presented by figures with black clothes. Figurants
are presented by faces without caps and
forces – with caps. Nodes with letter A correspond to the actions. The arcs present connection
and relation between named entities (NE). Color of arcs indicates on the type
of links. Arcs, connected nodes (corresponding named entities) with nodes A,
present that the actions includes the named entities .
A set of meaningful portraits of documents are organized in the Knowledge
Base. Logical reference is provided with
the aid of the rules IF… THEN (productions) of the language DECL, which are the
basis for decision of logical-analytical tasks.
4 Semantic-oriented
linguistic processor
Semantics-oriented linguistic processor consist of the following
components [9,14].
4.1 The component of lexical and morphological analysis (LMA)
It extracts words and sentences from the text, performs lemmatization of
words (normal form establishment) and constructs the semantic network
presenting the space structure of text (SpST), which reflects the sequence of
words, their basic features, beginnings of sentences and the presence of space character
lines. The component LMA uses a two-level general ontology and a special
collection of subject dictionaries (the dictionary of countries, regions of
Russia, names, forms of weapons, and other items specific for the supported
domains). The component performs semantic grouping of the words and assigns them
additional semantic attributes [10].
4.2 The component of syntactic-semantic analysis (SSA)
It converts one semantic network (SN) into another which represents the semantic
structure of text (SemST), i.e., the relevant semantic entities and their
connections [3,8,9]. The SemST is called the meaningful portrait of document. It comprises knowledge structures of the knowledge base which serves
the basis for implementing different forms of semantic search : the search
by features and connections, the search for the entities connected at different
levels, the search for similar persons and incidents, the search by distinctive
characteristics (with the use of ontology).
The component SSA is controlled by the linguistic knowledge (LK), which
determines the process of text analysis. LK includes the special contextual
rules which ensure the high degree of selectivity with the extraction of
entities and connections [http://www.ipiranlogos.com/english/topics/topic3-e.htm].
The functions of this component are the following:
- Extraction of entities from the
flow of NL documents: persons, organizations, actions, their place and time,
and many other relevant types of entities.
- The establishment of connections
between entities. For example, persons are connected with organizations
(PLACE_OF_WORK), by addresses (LIVES, REGISTERED). Or figurants of criminal events
are connected with such entities as the type of weapon, drugs (TO HAVE).
- The analysis of finite and nonfinite verbal forms with the
identification of the participation of entities in the appropriate actions. For
example, one figurant gave the drugs to another figurant, and this is the fact
linking them.
- The establishment of the connections of actions with the place and
time (where and when some action or event occurred).
- The analysis of the reason-consequence and temporary connections
between actions and events.
3.3 Expert system component
(ES)
On the
basis of semantic networks the new knowledge pieces are constructed in the form
of additional fragments (ESN). For example, the component ES extracts the field
of a person’s activity (in accordance with the assigned classifier) from the
text of resume for each autobiography. The person’s experience in his field is
evaluated. The correlation of a criminal incident to the specific type is
accomplished with the analysis of the criminal actions of ES: the following
facts are revealed - the nature of crime, the method of its accomplishment, the
instrument of crime, and so forth (in accordance with the classifiers of the
criminal police) [3,12,13].
3.4 Base of linguistic and expert knowledge
(KB)
It contains the rules of the text
analysis and expert solutions in the internal representation. They determine
the work of the linguistic processor. Our logical-analytical systems have
several such bases, which are activated depending on subject areas and user
tasks.
4. Linguistic knowledge
Linguistic knowledge
has same structures for various language that give possibilities to tune the
processor LP on the text collection in this language, for example, Russian and
English. Linguistic knowledge is written in language SSN which has declarative
structures. It provide the tuning to new subject field and language for
comparative short time. Procedures part of
LP is not changed (excluded blocks of
lexical morphological analysis).
4.1.
Terminological analysis and transformations
Terminological
analysis has as a goal - synonymous transformations, the
interpretation of abbreviations and the selection of terms. The fragments of
the following form are used for this:
TERMIN
(<resulting word>,<word1>,<word2>) or
TERMIN
(<resulting word>,<word1>,<word2>,<word3>),
where <word1>,… may be
normalized word (in canonical form), or sign, or AND-OR graphs. These graphs
are represented as fragments STR_OR (...), where facultative words or their
signs are on argument places. For example, fragment
TERMIN
(UNEMPLOY,NO,WORK)
indicates the conversion: NO
WORK - > UNEMPLOY. Another example: fragments
TERMIN
(MO,MOSCOW,3+) STR_OR(REGION,REG.,DISTRICT,…/3-)
carry out many conversions: MOSCOW REGION - > MO, MOSCOW REG. - >
MO, MOSCOW DISTRICT - > MO… For these fragments can be assigned the
permissible context (words, which can stand to the left and to the right). Can
be also indicated the inadmissible context - word or their signs, which there
must not be to the left or to the right. As a result it is possible to extract
terms and word combinations, whose values depend on context.
Synonyms are presented by fragments:
SYNON (<resulting
word>,<word1>,<word2).
For example,
SYNONIM (UKRAINIAN,HOHOL) - word HOHOL (specific name of Ukrainian persons)
must be substituted on UKRAINIAN. Many synonyms have conditional nature. The
permissible or inadmissible context is indicated for them. For example, in the
case given above are not admitted replacements for the words - surnames, the
nicknames, names streets and others
Ontology is
presented by fragments of ESN with
name SUB (class – subclass), NEAR
(nearness of meaning) and OR_OR (separate “or”).
For example:
SUB(MAN,TERRORIST)
SUB(TERRORIST,SEPARATIST)
SUB(TERRORIST,REBEL)
SUB(TERRORIST,INSURGENT)
SUB(TERRORIST,MERCENARY) . . .
NEAR(ALCOGOL,DRUNK,TIPSY,VODKA) . . .
OR_OR(MALE,FEMALE,CHILD) . . .
4.2. Contextual rules
The block of
syntactical-semantic
analysis on the basis of context are extracted the named entities (NE)
and the connected information (for the persons their beard day, sex, address
and other) [2,15]. For this are used contextual rules.
Syntactical-semantic analysis is necessary for the extraction of addresses, attributes
of machines, organizations and other. Usually the entities are the collections
of the words, which grammatically aren’t connected. For example, address can be considered as the
collection of letter combinations st. (street), h. (house),.:., words from the
capital letter and the numbers. Each such collection can have its boundaries
and inadmissible components. For example, in the addresses it cannot be FIO,
verbs and so on. The extraction of such word collections (descriptions of NE)
is based on the use of contextual rules of the following form:
CONTEXT
(<word1>,<word2>,<word3>,…) - > <resulting fragment>
where <word1>,… - are
the normalized word or sign or AND-OR graphs. For every rules the special
fragment indicate the position to begin application, and also permissible or
inadmissible context. This ensures the differentiated application of
rules. These rules analyze word group, which describe any entities, and
substitute them (in case of application) by one word, with which is connected
the resulting fragment.
Contextual
rules are applied in the determined sequence. At first they extracted the
separated entities, then their properties, word combination, and finally,
verbal forms. In process of rules application the meaningful portrait of
document will be build.
For example,
let us examine rule GG~1:
MUSTBE
(GG~1,1) STR_OR(ADJ,PRON/2+)
CONTEXT (2-,
NOUN/GG~1) P_P (GG~1,3+) WORD_C (1,2/3-)
3-(2,MORF)
NOTBE (GG~1,2,LETT)
This rule provides the conversions:
ADJECTIVE + NOUN -- > <word
combination> and
PRONOUN + NOUN -- > <word
combination>.
Fragment
MUSTBE indicates that application of rule GG~1 must be began from the first
position, i.e., from search for words with the signs ADJECTIVE (ADJ) and
PRONOUN (PRON), since them it is less than NOUN (NOUN). Fragment P_P separates
left side of the right (- > ), and WORD_C - indicates that the words on the
first and second positions must be united into the combination of words, which
subsequently will be considered as one word with the morphological signs of the
second word. Fragment NOTBE indicates that on the second position cannot be the
separate letters (sign LETT).
This is an
example of the simplest rule. The fragments, which indicate the context, are
added to such rules, to the possibility of any symbols inside and other special
rules is achieved the identification of entities and objects, for example, on
the basis of pronouns or brief descriptions (on the name surname is restored,
if they were somewhere mentioned together). And much other, which is necessary
for the work with the natural language.
Each
contextual rule is semantic network (ESN). All linguistic knowledge is written
in language ESN. Application of rules is provided the productions of language
DEKL. These productions are organized as program, which play the role of the
empty linguistic shell, which supports the language of the record of linguistic
knowledge - ESN. As shows experience, this shell can be tuned into different
subject fields and languages. Such way different linguistic processors are
designed.
4.3.
Application of the rules
Application of contextual rules is fulfilled
in the strictly defined sequence - each at their level. For example, in system
“Criminal” the linguistic processor at first extracts the following named
entities - police department, the police mans and others. They can contain
surnames, names, which are not the figurants (criminal mans). This is necessary
to facilitate the subsequent analysis. Otherwise the words, which compose these
entities, can be captured by other rules and create noise. Further figurants
are extracted and so on. The set of rules is introduced for this. Some begin
their application from the search of names, surnames (MUSTBE), others - from
the search for the birthday, the third - from the initials. Such way we
minimizes losses in cases when the block of morphological analysis not give the
necessary signs for any words. Then word combinations are analyzed, and
finally, verbal forms. In process of application of these rules semantic
network (meaningful portrait of document) is be building. Example of the
levels, which determine the order of the rule application, is given below.
{== levels
==}
LEVEL
(LEVEL_E1, LEVEL_E2, LEVEL_E3, LEVEL_E4,…)
LEVEL_E1
(CATALOG) {= extraction of word combinations from the catalogs =}
LEVEL_E2
(MIL~~1, ST~~1) {= extraction of police departments,… =}
LEVEL_E3
(FF~~1, FF~~2) {= extraction of figurants =}
{==
grammatical analysis, the extraction of word combinations =}
{== AA~~… -
uniform terms, GG~~… - words combination ==}
LEVEL_E4
(AA~~1, AA~~3, AA~~4, GG~~1, GG~~2,…)
{= GG~~1:
word combination ADJECTIVE – ADJ or PRONOUNCE - NOUN=}
MUSTBE
(GG~~1,1) STR_OR (ADJ, PRON/2+) CONTEXT (2-, OBJ/GG~~1)
P_P (GG~~1,3-)
WORD_C (1,2/3+) 3- (2, MORF) NOTBE (GG~~1,2, LETT)
. . .
In the curly
braces the commentaries are given. It is example of the rule GG~1, which
reveals word combinations with signs ADJ or PRON and OBJ (i.e. NOUN etc.).
System has full set of contextual rules, which provide the complete analysis of
sentences and building meaningful portrait of documents. But in contrast to the
standard grammars our LP provide the extraction of all significant
(information) entities, including of such, in which the words aren’t
coordinated between themselves, for example, addresses, machines with the
indication of their numbers and so on. Described processor LP is
semantics-oriented, because it provides the extraction of entities and various
kind connections between them. These are semantic components. Such LP found
their use in the systems of new class – “Analytic”, “Criminal”, “AntiTerror”
and other.
On Fig.3 the process of rule application is shown. System is working in
special regime (with comfortable interface), which indicates the place of
mistakes and give possibilities for user quickly to correct rules.
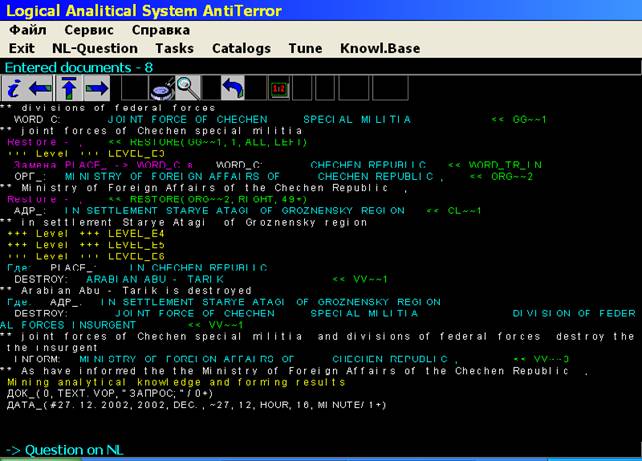
Fig.3 Process of rule
application
DEMO-version
of semantic-oriented LP is on cite [http://ipiranlogos.com/en/Demo/].
5 Conclusion
The proposed semantic-oriented linguistic processor have been used for
construction of intellectual analytical systems: “Criminal”, “Analytic”,
“AntiTerror”, “Monument” and others. The
distinctive features of these systems are the high degree universal of the
processor. It provide automatic extraction of knowledge structures from texts in various language. Now it’s good Russian and experimental
English. In prospective the processor for short time (by linguistic knowledge)
may be tuned on others language - Slavonic and European. As result the
processor are forming the Knowledge Base which has common structure for all
language and which is used for realization of logical-analytical functions. The
ESN apparatus provides powerful representational possibilities for describing
all levels of natural language, including the level of deep semantic
structures, and cross-lingual correspondences [http://Ipiranlogos.com/english/].
The
implemented linguistic processors were created on the basis of this approach which
made it possible to manufacture design solutions for the basic problems of extracting meaningful knowledge from the
texts in natural languages.
References
[1] Kuznetsov, I.P. Elena
B. Kozerenko, Mikhail M. Sharnin.
Technological peculiarity of knowledge extraction for logical-analytical
systems // Proceedings of ICAI’12, WORLDCOMP’12, July 18-21, 2012, Las Vegas,
Nevada, USA. - CRSEA Press, USA, 2012.
[2] Kuznetsov I.P. Matskrvich A.G. Semantic
oriented systems controlled by knowledge base // University of communications
and informatics, Moscow, 2007,173 p.
[3] Kuznetsov I.P. Methods
of Processing Reports with the Extraction of Figurants and Events Features //
In Dialogue'99: Proceedings of the International Workshop "Computational
Linguistics and its Applications", Vol.2, Tarusa, 1999.
[4] Kuznetsov I.P. Semantic Representations //
Moscow: "Nauka", 1986. 290p.
[5] Kozerenko, E.B. Multilingual Processors: a
Unified Approach to Semantic and Syntactic Knowledge Presentation. In
Proceedings of the International Conference on Artificial Intelligence
IC-AI'2001 25-28, 2001. CSREA Press, 2001, pp.1277-1282.
[6] Byrd, R. and Ravin, Y. Identifying and
Extracting Relations in Text // 4th International Conference on Applications of
Natural Language to Information Systems (NLDB). Klagenfurt, Austria, 1999.
[7] Kuznetsov I.P. Natural
Language Texts Processing Employing the Knowledge Base Technology // Sistemy i
Sredstva Informatiki, Vol.13, Moscow: Nauka, 2003, pp. 241-250.
[8] Kuznetsov I.P., Matskevich A.G. The System
for Extracting Semantic Information from Natural Language Texts // Proceedings
of the Dialog International Workshop "Computational Linguistics and its
Applications", Vol.2, Moscow: Nauka, 2002.
[9]
Kuznetsov, I., Kozerenko, E. The system for extracting semantic
information from natural language texts // Proceeding of International
Conference on Machine Learning. MLMTA-03, Las Vegas US, 23-26 June 2003, p.
75-80.
[10]
Somin N.V., Solovyova N.S., Charnine M.M The System for Morphological Analysis:
the Experience of Employment and Modification // Sistemy i Sredstva
Informatiki, Vol. 15 Moscow: Nauka, 2005, pp. 20-30.
[10] Kuznetsov I.P., Matskevich A.G. The English
Language Version of Automatic Extraction of Meaningful Information from Natural
Language Texts // Proceedings of the Dialog-2005 International Conference
"Computational Linguistics and Intelligent Technologies", Zvenigorod,
2005pp. 303-311.
[11] Cunningham, H. Automatic Information
Extraction // Encyclopedia of Language and Linguistics, 2cnd ed. Elsevier,
2005.
[12] Kuznetsov I.P., Matskevich A.G. Semantics
Oriented Linguistic Processor for Automatic Formalization of Autobiographical
Data // Proceedings of the Dialog-2006 International Conference
"Computational Linguistics and Intelligent Technologies", Bekasovo,
2006, pp. 317-322.
[13] Web site “Knowledge extraction for
Analytical Systems”: http://Ipiranlogos.com/english/
[14] Kuznetsov I.P., Kozerenko
E.B., Matskevich A.G. Deep and Shallow Semantic presentations in
Intelligent Fact Extractors // Proceedings of ICAI’2010 Las Vegas, USA,
June 14-17, 2010, CRSEA Press, 2010.
[15] Kuznetsov, I.P.,
Kozerenko E.B. Semantic Approach
to Explicit and Implicit Knowledge Extraction
// Proceedings of ICAI’11, WORLDCOMP’11, July 18-21, 2011, Las Vegas, Nevada,
USA. - CRSEA Press, USA, 2011.