Особенности
извлечения знаний из текстов
семантико-ориенированным лингвистическим процессором
Semantix
Кузнецов
Игорь Петрович (igor-kuz@mtu-net.ru), ИПИ РАН,
Ефимов Дмитрий Алексеевич (d.efimov@synsys.ru),
Кузнецов Константин ЗАО
Синергетические Системы.
Аннотация
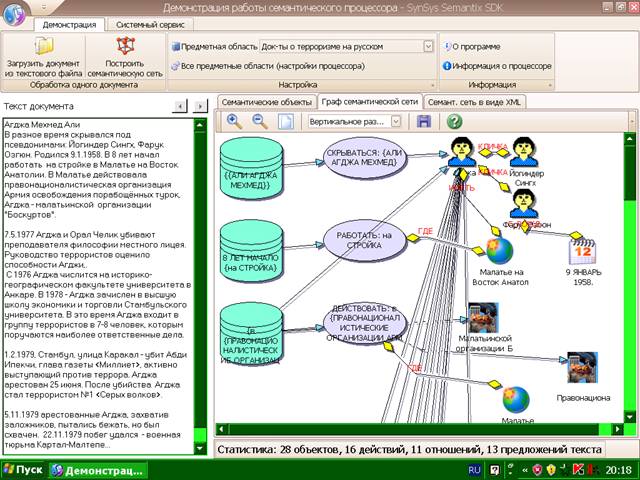
Лингвистический процессор Semantix
предназначен для областей, где требуется автоматическая формализация потоков
текстов на естественном языке: резюме, сообщения СМИ, информационно-рекламные
материалы, почтовые сообщения, сводки происшествий, справки по уголовным делам,
архивные материалы и др. Из текстов (документов) извлекаются интересующие
пользователя объекты, их свойства и связи. Представляются факты участия объектов в
действиях. Последние сами рассматриваются как комплексные объекты с их
свойствами и связями. В результате на основе каждого документа строится
специального вида семантическая сеть, отражающая его семантическую структуру.
Такие сети отображаются на XML-файлы,
которые служат для организации Баз Знаний, соответствующих семантических
поисков, для решения логико-аналитических задач, а также для автоматического заполнения
реляционнных БД.