Объектно-ориентированная система,
основанная на знаниях
в виде XML-представлений
Кузнецов Игорь Петрович (ИПИ
РАН)
Рассматривается особенности работы
клиент-серверной системы, предназначенной для сбора и логико-аналитичской
обработки неформализованной информации в достаточно широких областях
приложения. Ядром системы является
семантико-ориентированный лингвистический процессор для извлечения знаний из
текстовых документов, из которых выявляются объекты и связи между ними. Последние преобразуются в XML-файл, отражающий семантическую
структуру документа. Система включает в себя Базу знаний, которая является
основой организации различных видов семантического поиска информационных
объектов.
Введение
Развитие логико-аналитических систем и сети Интернет в значительной степени идет в
одном направлении, связанном с использованием семантической информации. В сети Интернет
все большее развитие получают семантические технологии - язык описания ресурсов
RDF (Resource Description Framework), язык отологий OWL (Web Ontology Language), язык запросов SPARQL. Последние
планируются как основа нового типа поисковых машин - Семантического WEB
(WEB-3), где предлагается учитывать, какого типа объекты необходимы
пользователю и их содержимое. Для этого разрабатываются новые технологии встраивания
семантики в существующие WEB-страницы, предлагаются новые языки запросов к
хранилищам знаний. В этом плане интересны работы Консорциума W3C – www.w3.org/2001/sw (программа «семантическая сеть»), www.w3.org/TR/rdf-schema
(спецификация языка DRF),
а также предложения других рабочих групп [5,6,7].
В тоже время в ИПИ РАН в рамках плановых
тем (ДИЕС, ИКС, Криминал, Аналитик, Поток) уже более 15 лет развиваются
направления, связанные с обработкой семантической информации. В рамках данных
направлений создана научная база: расширенные семантические сети
(РСС),
методики представления сложных видов знаний, инструментальная среда ДЕКЛ
обработки структур знаний, сетевые позиционные грамматики, онтологии в виде
РСС, морфологический анализ на основе обобщенных окончаний [2,7,8,10].
Эта база послужила основой создания нового
класса логико-аналитических систем. Одна из них - клиент-серверная система Analitix, разработанной
сотрудниками ИПИ РАН совместно с ЗАО «Синергетические системы». Эта система
основана на структурах знаний, представленых в виде XML-файлов, что дает дополнительные
возможности в плане выхода в Интернет и использования стандартных программ для
организации поиска и интерфейса. Другое перспективное направление приложений
связано с использованием упомянутых структур знаний для развития семантических WEB, где предполагается глубинный
анализ документов с выделением объектов и семантических связей. Данная статья
посвящена описанию возможностей системы Analitix и
перспектив ее развития. Отметим, что тематика данной статьи пересекается с
тематикой статьи [16], посвященной средствам настройки. Однако, здесь проблемы рассматриваются под углом конструктивных
особенностей системы Analitix и использования XML-представлений.
1. Процедуры извлечения знаний из текстов
Эти процедуры составляют семантико-ориентированный
лингвистический процессор, который осуществляет
автоматическую формализацию текстовых документов. На входе процессора – текст,
на выходе – его формальная (семантическая) структура. Такой процессор был
разработан в конце 90-х годов для систем Криминал и Аналитик. На выходе
процессора формировалась семантическая структура документа в виде РСС. В
системе Analitix
используется лингвистический процессор Semantix, который формирует на выходе
XML-файл, представляющий извлеченную из документа семантическую информацию.
Будем называть такой файл XML-представлением документа.
Рассмотрим основные компоненты
семантико-ориентированного лингвистического процессора Semantix:
1.1.
Блок лексико-морфологического анализа.
Выделяет из документа слова и предложения и выдает в виде
семантической сети (ПС-документа), представляющей последовательность компонент
(слов в нормальной форме, чисел, знаков) и их основные признаки, Использует набор
тематических словарей (словарь стран, регионов России, имен, видов оружия и
др.) для придания словам и словосочетаниям дополнительных семантических
признаков [13].
1.2.
Блок синтактико-семантического анализа. Путем анализа ПС-документа блок
выделяет объекты и связи [8,9]. На из основе строит другую
семантическую сеть, представляющую семантическую структуру (СС-документа).
Блок управляется лингвистическими знаниями (ЛЗ), за счет которых
обеспечивается:
- Извлечение информационных объектов (лиц,
организаций, событий, их места, времени,..., до 40 типов).
- Выявление связей объектов. Например, как
лица связаны с организациями, адресами и др.
- Анализ глагольных форм, причастных и
деепричастных оборотов с выявлением фактов участия объектов в соответствующих
действиях.
- Выявление связей действий с объектами
типа место или время (где и когда имело данное действие или событие).
- Анализ причино-следственных и временных
связей между действиями и событиями.
1.3.
Экспертные системы. На основе СС-документа формируют новые знания, которые
дополняют СС-документа [2,10]. Например, по автобиографии выявляют область
деятельности лица, его специальность и др. Осуществляют соотнесение
криминального происшествия к определенному типу (в соответствии с классификаторами
криминальной милиции).
1.4.
Процедура формирования
XML-представления (для процессора Semantix). Преобразует СС-документа в
XML-файл, где представлены все выявленные компоненты и связи. Преобразование
осуществляется без потери информации. В случае необходимости, обеспечивается
обратное преобразование XML-представления в
СС-документа.
1.5.
Блок построения каталогов описаний объектов.
Выделяет из XML-представлений объекты определенного типа. На их основе строятся
описания, которые упорядочиваются по алфавиту и образуют каталог. Например,
таким способом создаются каталоги лиц (их ФИО), адресов и др. - толоько тех,
которы встретились в документах.
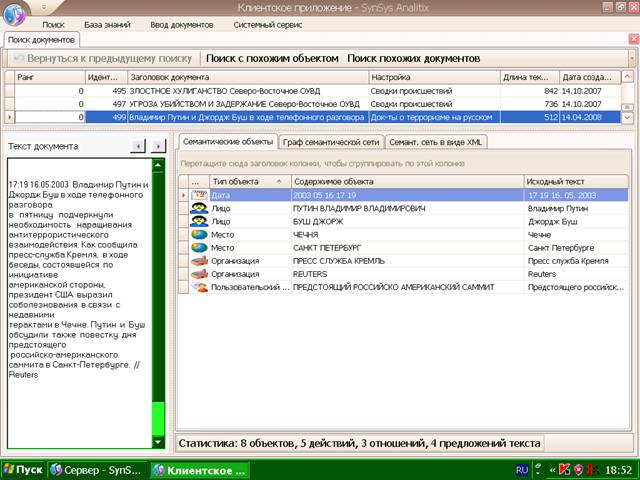
Рис. 1. Пример работы
лингвистического процессора Semantix.
На рис.1 изображены объекты, которые
выделяются лингвистическим процессором. Помимо этого, выделяются свойства,
отношения и факты участия объектов в действиях (они не изображены на рис.1, но
имеются в XML-представлении, см. приложение 1).
2. Выделяемые объекты и связи.
Набор выделяемых объектов зависит от
задач пользователя. В тоже время,
качество лингвистического процесора в значительной степени определяется
возможностями такого выделения. Ниже перечислены основные типы информационных объектов
и связей, извлекаемые Semantix:
- лица (по ФИО) с их особенностями
(потерпевший, террорист и др.);
- адреса, почтовые атрибуты;
- организации;
- должности;
- террористические группы, ОПГ;
- номера телефонов, факсов, электронных постовых
адресов с их стандартизацией;
- средства транспорта с выделением марки
машины, государственного
номера, цвета и других
атрибутов;
- количественные характеристики (сколько
лиц или других объектов принимали участие в том или ином событии);
-
паспортные данные и другие документы с их атрибутами;
- взрывчатые вещества;
- наркотические вещества;
- оружие с атрибутами;
- словесное описание лиц, их приметы;
- номера счетов, суммы денег с указанием
типа валюты;
- события (криминальные, террористические,
поломки изделий и др.) с указанием участия в них информационных объектов;
- время и место событий;
- связи между различными типами
информационных объектов, включая комплексные объекты (действия или события);
- другие объекты (опыт работы, знание
языков ... до 40 типов).
3. Структура
XML-представления.
Напомним, что XML-файл, в котором представлена СС-документа, образует XML-представление этого
документа. При этом выделенные объекты, отношения, действия и предложения
СС-документа отображаются на соответствующие компоненты XML-представления,
которые также будем называть объектами, отношениями, действиями и
предложениями.
Отметим, что XML-представления имеют определенный
научный интерес – как средства представления семантической структуры
предложений и текстов в языке XML. Рассмотрим
основные компоненты, из которых состоит XML-представление.
3.1. Константа - это простейшая
компонента СС, представляющая собой одно нормализованное слово или символ ЕЯ.
Константа задается в XML-представлении в виде:
<ARG TEXT="константа"/>
Например, костантами являются слова,
числа, спецзнаки и другие компоненты, встречающиеся в текстах ЕЯ.
3.2. Тип
элемента - это указатель класса, к которому относится константа
(например, это город или улица и др.).
3.3.
Типизированная константа - это
константа с указанием ее класса:
<ARG TEXT="константа" TYPE =
"тип элемента"/>
Например, если объектом является адрес, то
указывается, какое в нем слово - улица, какое число - номер дома и т.д.
3.4.
Атрибут - это константа,
характеризующая свойство объекта:
<ARG TYPE = "атрибут"/>
3.5. Cсылка на объект.
Каждый объект имеет свой уникальный номер, называемый идентификатором:
<ARG REF = "идентификатор
объекта"/>.
3.6.
Тип объекта - это выделенная
константа, определяющая его класс (FIO, DATE, ADDRESS и др.).
3.7.
Компонента XML-представления, называемая объектом, определяется
идентификатором, типом и содержит упорядоченное множество элементов, каждое из
которых есть или константа, или свойство, или ссылка на другой объект,
называемый дочерним. В конце дается описание объекта - текстовый фрагмент, на
основе которых был сформирован данный объект. Объект
задается в виде:
<OBJECT ID="идентификатор"
TYPE="тип объекта">
<ARG ... />
<ARG ...
/>
:
<SOURCE>описание объекта</SOURCE>
</OBJECT>
Здесь
<ARG ... /> - или константа, или свойство, или ссылка на другой объект.
Порядок элементов в объекте определяется порядком соответствующих слов или
фрагментов в тексте, на основе которых был сформирован объект. Объект
называется типизированным, если он содержит типизированные константы.
3.8.
Компонента XML-представления, называемая действием (или просто действие),
имеет такую же конструкцию, как и объект, только без описания:
<ACTION ID="идентификатор"
TYPE="тип действия">
<ARG ... />
<ARG ... />
:
</ACTION>
3.9.
Компонента XML-представления, называемая отношением (или просто отношение),
определяется типом (именем отношения) и содержит два элемента, каждый из
которых это ссылка на объект, действие или константа. Отношение задается в
виде:
<RELATION
TYPE="тип отношения">
<ARG REF="идентификатор 1-го
объекта или действия"/>
<ARG REF="идентификатор 2-го
объекта или действия"/>
</RELATION>
Вместо идентификаторов могут быть
константы. Фактически отношение - это важный частный случай двух элементного
действия, у которого отсутствуют идентификатор и свойства.
3.10.
Компонента XML-представления, называемая предложением (или просто
предложение) состоит из упорядоченного набора констант и ссылок на объекты или
действия, которые были сформированы на основе соответствующего предложения ЕЯ.
В конце дается текст самого предложения, взятого из исходного текста:
<SENTENCE>
<ARG ... />
<ARG ... />
:
<SOURCE>исходное предложение ЕЯ-текста</SOURCE>
</SENTENCE>
3.11. Выходной XML-файл, представляющий документ (его XML-представление),
состоит из вышеперечисленных компонент, которые ставятся (...) в следующем порядке:
объекты, действия, отношения, предложения:
<?xml version="1.0"
encoding="windows-1251" ?>
<DOCUMENT
DOC_NUM="номер документа">
...
</DOCUMENT>
Порядок предложений в XML-представлении
соответствует их порядку в исходном документе. Пример XML-представления
изображен на Рис.2.
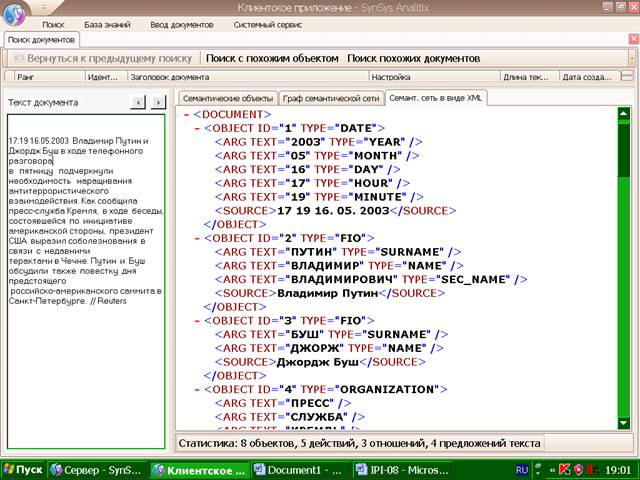
Рис.
2. Пример XML-представления.
Полный текст документа и его XML-представления приведен в
Приложении 1.
В процессе построение
XML-представления процессор Semantix выделил из текста объекты типа DATE
(дата), FIO (ФИО лиц), ORGANIZATION (организации), PLACE (место) и USER_OBJECT
(пользовательский объект). Все компоненты у них нормализованы. За счет ЛЗ
процессор дополняет и расшифровывает некоторые объекты. Например, для Путина указано, что это Путин Владимир Владимирович, а Президент США – это Джорж Буш.
Объекты DATE и FIO - типизированные, так
как указаны классы их компонент. С помощью конструкций ACTION предсталены
действия:
<ACTION ID="9" TYPE="ПОДЧЕРКНУТЬ">
<ARG
REF="2"/>
<ARG
REF="3"/>
....
</ACTION>
Здесь представлено
действие ПОДЧЕРКНУТЬ двух лиц (Путина и Буша) с идентификаторами
ID="2" и ID="3". Остальные слова даны перечнем, так как они
не вошли ни в какие объекты.
Временное отношение:
<RELATION TYPE="КОГДА">
<ARG REF="9"/>
<ARG
TEXT="ПЯТНИЦА"/>
</RELATION>
представляет, что предыдущее
действие имело место в пятницу.
Вместо пятницы может быть ссылка на
какую-либо дату, указанную в документе.
В компонентах XML-файла <SENTENCE>
... </SENTENCE>, представляющих предложения,
имеются ссылки на объекты, действия, а также имеются слова (в нормальной
форме), которые не вошли ни в объекты, ни в действия.
Отметим, что в XML-представлениях имеются все
компоненты, необходимые для различных приложений. Нормализованные элементы
являются основой организации различных видов объектного или семантического
поиска. Описания служат для построения различного рода досье, отчетов, форм и т.д
4. Организация базы
знаний
Под Базой Знаний (БЗ) понимается
хранилище объектов и связей, которое организовано таким образом, чтобы обеспечивать,
во-первых, хранение больших объемов информации, и
во-вторых, эфективные (семантиченские) поиски объектов. БЗ может быть организована по-разному. Ниже будет рассмотрено несколько
способов такой организации.
4.1.
База знаний в виде XML-представлений
База знаний в виде XML-представлений рганизуется
таким же образом, как БЗ на семантических сетях (РСС), которая была разработана
для системы Криминал [8]. Различается внешняя и внутренняя БЗ. Во
внешней БЗ хранятся структуры знаний (в виде
XML-представлений) и сами документы, а также индексные файлы, связывающие слова
с номерами документов, в которых эти слова встретились. Вся эта информация
имеет вид плоских файлов. Для ее хранения используется обычная База Данных
(БД), которую будем называть внешней БЗ. Выбор БД зависит от
количества документов, пользовательской БД, т.е. определяется областью
приложений. Поиск осуществляется следующим образом.
На вход поступает запрос. Все его слова
нормализуются. Каждому слову присваивается вес - в зависимости от степени его
информативности при поиска объектов. При этом
общезачимые слова не учитывается - им присваивается вес 0. Далее, за счет
индексных файлов находятся документы, в которых встретились слова запроса.
Подсчитыается вес документа - как сумма весов упомянутых слов. Документы
ранжируются по весам и выделяются такие из них, вес которых выше заданного
порога. Отметим, что порог зависит от множества факторов:
количества значимых слов запроса, количества найденных документов с относительно
высокими весами и др. Для каждого выделенного документа находится XML-представление,
которое преобразуется в СС-документа и подкачивается в оперативную память.
В результате образуется оперативная или внутренняя БЗ, в которой на уровне структур знаний (с помощью программ на
языке ДЕКЛ) ищется запрашиваемая информация.
На основе БЗ, организованной описанным
способом (как показывает опыт работы с системой Криминал), можно добиться
результатов достаточно высокого качества. При этом настройка обеспечивается за
счет умелого выбора упомянутых выше весов и порогов.
4.2.
База знаний в рамках реляционных БД.
Из XML-представлений документов выделяются
объекты, которые помещаются в соответствующие реляционные таблицы БД. Для
отношений, связывающих объекты, строятся свои таблицы. Поиск организуется на
базе типовых средств БД. Ответ на запрос сводится к его формалации, выделению
типа запрашиваемого объекта, преобразованию его нормализованных элементов в
SQL-запрос для поиска адекватных объектов в соответствующих реляционных таблицах
БД.
Организация подобных БЗ представляется как
наиболее простой вариант. Этот вариант использован в ДЕМО-версии системы
Analitix.
Современная БД позволяет снять многие
ограничения на объемы информации в БЗ и использовать ее поисковую машину. Но
при этом возникают существенные трудности, когда необходимо учитывать связи, заданные в виде отношений и
действий. В перспективе, БЗ должна иметь свое хранилище большого объема и свою
поисковую машину, ориентированную на
сложные виды поиска с учетом связей объектов.
4.3.
Организация БЗ в сети Интернет.
Это направление исследований имеет большую
перспективу в плане создания новых поколений Семантических WEB. В одном из вариантов
организации БЗ предполагается автоматически преобразовывать XML-представление в
формат RDF, а для поиска объектов использовать язык запросов типа SPARQL. Здесь
следует учитывать большое различие между XML-представлениями и языком RDF. В
XML-представлениях содержится больше семантической информации, имеющей место в
рамках одного документа. Язык RDF в этом плане беднее. В нем факты выражаются тройками:
подлежащее-сказуемое-дополнение. Поэтому возможны большие потери семантической
информации. Более того, предполагается постоянное участие человека, создающего
эти тройки и связывающего их с объектами других документов (используя
глобальные имена в виде ссылок URI). На основе XML-представления конструкции
языка RDF могут строиться автоматически, что особенно важно в связи с наличием
громадных потоков текстов в сети Интернет.
В другом варианте представляется
перспективным сделать XML-представления базовыми конструкциями для хранения
семантической информации. На основе таких конструкций создать свой язык
запросов, и соответственно, его поддержку в плане обеспечения различных видов поиска.
Тогда можно использовать лингвистический процессор для отображения ЕЯ-запросов в XML-представления. При этом упрощается сопоставление
конструкций XML-представлений с поиском нужных объектов. По найденным объектам
(в перспективе) можно автоматически строить ссылки в виде URI, которые могу
дополнять XML-представления, создавая таким образом
глобальную сеть семантических связей.
5. Критерии
поиска.
При объектном поиске роль запроса играет
исходный объект – его компоненты, свойства и связи. Требуется найти объекты с
такими же компонентами, свойствами и связями. Поиск идет на уровне XML-представлений,
где учитываются различные виды связей. Такой поиск относится к классу семантических. Ниже будут рассматриваться типовые виды
семантиеских поисков, реализованные в системе Analitix.
Исходный объект, по которому
осуществляется поиск, берется из XML-представления, которое строится
лингвистическим процессором путем анализа текста документа (или запроса, или
описания, взятого из каталога объектов). Элементам объекта придается
определенная степень значимости, которая учитывается при поиске. Только
после этого осуществляется сам поиск по объекту. Если из документа (запроса) выделено
несколько объектов, то пользователь должен выбрать один из них.
Отметим, что объектные поиски не
эффективны, когда исходный объект состоит из малого количества часто
встречающихся элементов (слов). Например, поиск адресов по слову "Москва" или "Россия Москва". Или поиск лиц по
слову "Иван". Тогда лучше
работают обычные поиски - контекстный поиск и др. Поэтому вводится понятие
полноты объекта. Если исходный объект удовлетворяет критерию полноты, то следует
включать объектный поиск. Этот критерий можно не учитывать в том случае, если
удается быстро оценить другими средствами возможное количество найденных
объектов и это количество не превышает заданной границы.
Рассмотрим более подробно категории, от
которых зависит эфеективность объектного поиска, - степени значимости элементов
и критерия полноты исходного объекта.
Исходный объект (как и любой объект
XML-представления, см. п.2.7.) определяется
идентификатором, типом и содержит упорядоченное множество элементов, каждое из
которых есть или константа, или свойство, или ссылка на другой объект. Будем
различать следующие константы: элемент-слово (у него TEXT='некоторое слово'), элемент-число, элемент-символ и элемент-инициалы (буква с точкой в конце).
Для
всех объектов задается множество незначимых слов, которые встречаются
в объектах, но не должны учитываться при объектном поиске. К ним относятся
общезначимые слова, указательные местоимения и др. Помимо этого, в тексте могут
быть незначимые слова (частицы, междометия и др.), которые удаляются перед
анализом текста.
Для объекта каждого типа задаются малозначимые
слова, которые в малой степени (с малыми весами) должны учитываться при
объектном поиске по исходному объекту данного типа. Это слова, которые часто встречаются
в объектах или которые играют роль типизаторов или указателей.
Значимым называется элемент
исходного объекта, который не относится к множеству незначимых и малозначимых
слов. При наличии ссылки на другой объект все значимые элементы последнего
пополняют множество значимых элементов исходного объекта. Степень значимости элементов
зависит от его уникальности и характеристических свойств. Такая степень задается
весами. При точном поиске значимым элементам придается статус обязательности –
все они должны быть в найденных документах.
Критерий полноты исходного объекта
определяет эффективность выполнния для него семантических (объектных) поисковых
процедур. Критерий полноты объекта зависит от его типа и задается шаблоном.
Например, шаблон <слово><слово><число>
означает, что в объект должен содержать два значимых элемента-слова и один элемент-число.
Порядок не играет роли (в простейшем случае).
Для объектов каждого типа задается свой
шаблон или несколько шаблонов. Если исходный объект определенного типа
удовлетворяет одному из его шаблонов, то это означает, что он обладает
критерием полноты и для него следует включать объектный поиск. Например, если
ввести следующий шаблон для адресов - <число><число><слово>,
то это означает, что адрес будет полным при наличии в нем двух чисел и
значимого слова.
В системе Analitix
(на первом этапе) реализованы следующие виды объектных поисков:
- Точный
поиск объектов. Требует полноты исходного объекта и наличия всех
обязательных элементов у найденных объектов.
- Точный
поиск лиц. Требует полного ФИО (или инициалов вместо имени и отчества) и
наличия всех элементов у найденных объектов. Допускается совпадение имен,
отчеств и инициалов - по первым буквам.
- Поиск
похожих объектов. Не требуется наличия всех значимых элементов у найденных
объектов. По совпавшим элементам подсчитывается вес, который определяет степень
"похожести" (адекватность) исходного и найденного объектов..
- Поиск
связанных объектов.
Отметим, что тип исходного объекта во-многом определяет эффективные поиски. Например, при
поиске телефонов, сайтов, дат, документов, номерных вещей, статей УК и др. (где
есть числовые данные) работают только точные поиски. Онтологии, в основном, требуются
при поиске похожих примет, действий (реже - автотранспорт, оружие). Поиск
похожих объектов с учетом связей - в основном для лиц без ФИО.
Будем называть объекты, полученные в
результате точного поиска - аналогичными, иначе - похожими.
При поиске объектов используются онтологии,
которые служат для размножения значимых элементов исходного объекта. Все
элементы полученного множества участвуют в поиске и подсчете весов. Это
необходимо для расширения пространства поиска с целью учесть различные способы
и средства описания того, что есть в исходном объекте. В результате повышается
точность и надежность результатов, обеспечивается достаточная свобода
использования слов и терминов в запросах и заданиях системе.
С помощью онтологий на базе значимых
элементов исходного объекта порождаются вторичные элементы:
- близкие по смыслу элементы (на основе
фрагментов NEAR);
- поясняющие элементы (на основе
фрагментов SUB);
- противоречивые элементы (на основе
фрагментов OR_OR).
Порожденные элементы также
участвуют в поиске и подсчете весов.
6. Процедуры поиска объектов
При поиске объектов вначале обеспечивается
выделение значимых элементов исходного объекта с присвоением им статуса
обязательности. Отсеиваются незначимые слова. Значимым элементам присваиваются
веса. Типизированным элементам присваивается больший вес, чем простым.
Малозначимые элементы остаются без статуса обязательности. Им присваивается
наименьший вес. Если есть ссылка на объект, то выделяются и его элементы,
которые они дополняют имеющиеся. Им также присваивается статус и вес.
Далее ищутся объекты такого же типа,
содержащие все обязательные элементы. Будем называть такие элементы совпавшими.
У них может быть больше элементов, чем у исходного объекта.
Для каждого из найденных объектов подсчитывается
его вес:
- При совпадении обязательных
типизированных элементов к весу объекта добавляется наибольшая величина (вес,
присвоенный элементу).
- При совпадении обязательных простых
элементов (в том числе, с типизированными) добавляется
меньший вес.
- При совпадении малозначимых слов
добавляется малый вес.
Вес
объекта равен суммме весов совпавших элементов. Объекты упорядочиваются
(ранжируются по весам) и выдаются в порядке весов. Ясно, что при точном поиске у
всех этих объектов должны присутствовать обязательные элементы исходного
объекта. При поиске похожих такого присутствия не требуется.
Более того, при наличии противоречивых элементов вес документа уменьшается на
определенную величину.
Отметим, что веса, которые присваиваются
элементам (и при совпадении элементов добавляются к документам), вводятся через
специальные настройки, с помощью которых пользователь может увеличивать
значимость тех или других типов элементов – смещать акценты поиска.
Пример, иллюстрирующий результаты поиска
по объекту (лицу) Джорж Буш, приведен
на Рис.3.
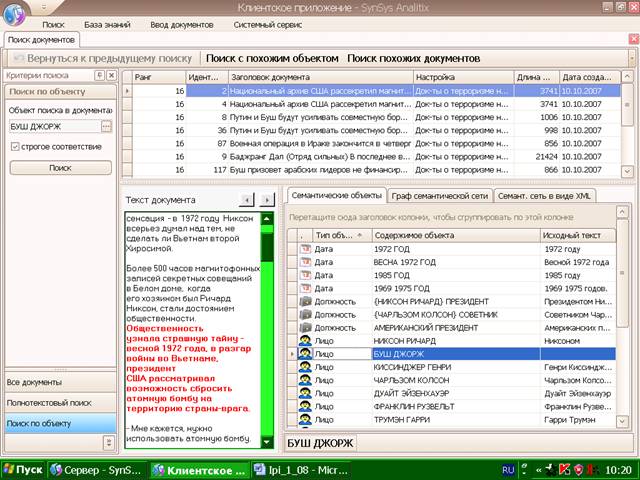
Рис.3. Пример точного поиска лиц по ФИО.
Особенности поиска лиц по ФИО:
- для имен и отчеств считаются
частично совпавшими имена с инициалами, инициалы с именами и инициалы с
инициалами (тогда вес найденного лица увеличивается на небольшую величину).
- нет малозначимых слов;
- нет ссылок на другие объекты;
- противоречивыми могут быть только имена,
отчества, и соответственно, инициалы (тогда вес найденного лица уменьшается
значительно).
7. Поиск связанных объектов.
Вассмотрим выявление связей одного
объекта.
Вначале выдаются каталоги описаний
объектов, из которых пользователь должен выбрать интересующий его объект. На
базе последнего (лингвистическим процессором) строится его XML-представление.
Ищутся аналогичные объекты. Используется точный поиск. Они образуют один или
множество исходных (аналогичных) объектов. Рассмотрим вначале простейший
выриант, когда исходный объект - один.
Для исходного объекта находятся связи с
другими объектами - прямые и косвенные. Прямые связи - связи с другими
объектами в рамках одного документа (поисшествия). Например, для фигуранта -
это адес проживания, владение оружием и др. Это связи 1-го уровня.
Косвенные связи - это связь через другие
объекты. Например, связанными считаются фигуранты, если они входят в
происшествия, в которых встретился один и тот же телефон (или какой-либо другой
объект). Это связи 2-го уровня.
Объекты, представляющие связи 1-го уровня,
находятся с исходным объектом в одном документе в определенных отношениях. Это
должны быть объекты определенного типа, которые задает пользователь. Они должны
удовлетворять критерию полноты. Объекты выделяются по отношениям, которые могут
иметь различную степень общности:
- Связь при наличии ссылок на объект;
- Связь через конкретные отношения;
- Связь за счет частия в одном действии;
- Объекты находятся в одном предложении;
- Объекты находятся в одном документе.
Выбор отношений также определяется
пользователем. Будем называть их допустимыми.
Если для исходного объекта найдено
множество аналогичных объектов, то для каждого из них ищутся связи 1-го уровня.
На рис.4 приведен пример поиска по связям 1-го уровня для объекта – человека с
ФИО Джорж Буш, который многократно упоминаеттся
в различных документах.
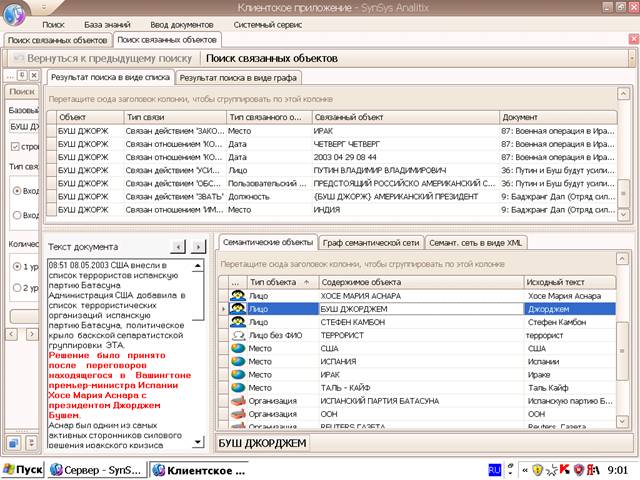
Рис.4.
Пример поиска по связям 1-го уровня.
Объекты, представляющие связи 2-го уровня,
находятся следующим образом. Выделяется интересующий пользователя объект,
найденный на 1-ом уровне. Для него ищутся аналогичные объекты – точный поиск
(для некоторых типов объектов допускается поиск похожих). Для них выделяются
связанные объекты (допустимыми отношениями). Те из них, которые удовлетворяют
критерию полноты, и образуют множество объектов, представляющих связи 2-го
уровня. Для найденных объектов также может осуществляться поиск связей. Это
связи 3-го и более высоких уровней.
Результат
может быть выдан в виде графа связей, где вершины – это объекты, а дуги - связи
между объектами (они метятся связывающим отношением). При этом вначале строится
граф связей 1-го уровня. Пользователь может сказать системе "Перейти на
поиск связей 2-го уровня" и т.д. Система решает задачу поиска связей любой
глубины. Для каждого объекта на графе пользователь может посмотреть, в какие
документы он входит, посмотреть текст документа, удалить объект или же искать
только его связи.
Отметим, что исходный объект может быть
получен другими способами, например, на базе запроса или документа. Поиск связей
будет таким же.
Заключение
В настоящее время разработан базис
комплексной клиент-серверной системы SynSys Analitix. Последняя
состоит из двух основных компонент: сервер Analitix Server и клиент Analitix Client. Система
предназначена для сбора и логико-аналитичской обработки неформализованной
информации в достаточно широких областях приложения.
Компонента Analitix Server включает базу
знаний (для хранения документов и XML-представлений), реализованную в рамках типовой БД, и поисковые
машины. Загрузка документов управляется из клиентской части Analitix Client и осуществляется в
серверной части, где автоматически формируется единая база знаний, которая
используется для различных клиентских приложений, в том числе, для выполнения
различных видов поиска по запросам клиентов.
Система реализована как набор SDK-модулей, которые работают
в среде .NET. Организация системы
предполагает быструю разработку новых семантических приложений – по заказу
пользователя. Предусмотрены широкие возможности по использованию в системе
различных БД – по требованию заказчика. Реализованы основные виды объектного
(семантического) поиска, которые могут быть дополнены более сложными процедурами
– поиска по связям, поиска похожих происшествий и др. Помимо этого, имеется
полнотекстовый поиск – для простых запросов.
С развитием сети Интернет тематика,
связанная с построением объектно-ориентированных систем и поисковых машин,
приобретает особую степень важности. Предлагаемые в данной статье подходы могут
быть основой новых поколений объектно-семантических WEB, где семантические связи
выявляются и формируются автоматически (на базе XML-представлений) и за счет этого обеспечивается
более точный и качественный поиск.
Литература
1. Кузнецов И.П. Семантические
представления // М. Наука. 1986г. 290 с.
2. Кузнецов И.П., Мацкевич А.Г.
Семантико-ориентированные системы на основе баз знаний. Монография. М.Связьиздат. 2007. 173 с.
3. Han
J. and Kamber, M. Data Mining:
Concepts and Techniques // Morgan Kaufmann, 2006.
4. FASTUS:a Cascaded Finite-State Trasducerfor Extracting Information from Natural-Language
Text. // AIC, SRI International. Menlo
Park. California, 1996.
5. Dong G. and J. Li. Efficient mining of emerging patterns: Discovering
trends and differences // Proceedings of the Fifth ACM SIGKDD
International Conference on Knowledge Discovery and DataMining,
S. Chaudhui and D. Madigan, editors, ACM Press, San Diego, CA, 1999, pp.
43–52.
6. Добров Б.В., Лукашевич Н.В. Онтологии для автоматической обработки текстов:
Описание понятий и лексических значений // Компьютерная лингвистика и
интеллектуальные технологии: Тр. междунар. конференции Диалог’06, Бекасово, 31
мая – 4 июня
7. Cunningham, H.
Automatic Information Extraction // Encyclopedia
of Language and Linguistics, 2cnd ed. Elsevier, 2005.
8.
Кузнецов И.П. Методы обработки сводок с выделением особенностей фигурантов и
происшествий // Труды международного семинара Диалог-1999 по компьютерной
лингвистике и ее приложениям. Том 2. Тарусса 1999.
9. Кузнецов И.П., Мацкевич А.Г. Система
извлечения семантической информации из текстов естественного языка // Труды межд.
Семинара Диалог 2001 по комп. лингвистике и её приложениям: Т.2. Москва, Наука
2002.
10. Кузнецов И.П., Особенности обработки
текстов естественного языка на основе технологии баз знаний // Сб. ИПИ РАН,
Вып.13, 2003 г. стр. 241-250.
11. Igor Kuznetsov, Elena Kozerenko.
The system for extracting semantic information from natural language texts //
Proceeding of International Conference on Machine Learning. MLMTA-03,
Las Vegas US, 23-26 June 2003, p. 75-80.
12. Кузнецов И.П., Мацкевич А.Г.
Англоязычная версия системы автоматического выявления значимой информации из
текстов естественного языка // Труды международной конференции по компьютерной
лингвистике и интеллектуальным технологиям "Диалог 2005", Звенигород,
2005.
13. Кузнецов И.П., Сомин Н.В. Англо-русская система
извлечения знаний из потоков информации в Интернет-среде. // Сб. ИПИ РАН, Вып.17, 2007, стр. 236-253.
14. Кузнецов И.П., Мацкевич А.Г. Лингвистические и алгоритмические
аспекты выделения объектов и связей из предметно-ориентированных текстов //
Труды международной конференции по компьютерной лингвистике и интеллектуальным
технологиям "Диалог 2007", Бекасово, 2007, стр. 333-342.
15. ДЕМО-версия лингвистического
процессора Semantix: www.semantix4you.com
16. Кузнецов И.П., Сомин Н.В. Средства настройки
семантико-ориентированной системы на выделение и поиск объектов. // В печати –
в данном Сб. ИПИ РАН,
2008.
Приложение 1.
Текстовый
документ на входе лингвистического процессора Semantix:
17:19
16.05.2003 Владимир Путин и Джордж Буш в ходе телефонного разговора в пятницу
подчеркнули необходимость наращивания антитеррористического взаимодействия. Как
сообщила пресс-служба Кремля, в ходе беседы, состоявшейся по инициативе
американской стороны, президент США выразил соболезнование в связи с недавними
терактами в Чечне. Путин и Буш обсудили также повестку дня предстоящего российско-американского
саммита в Санкт-Петербурге.
// Reuters
XML-представление
данного документа (на входе лингвистического процессора Semantix):
<?xml version="1.0"
encoding="windows-1251"?>
<DOCUMENT DOC_NUM="0">
<OBJECT
ID="1" TYPE="DATE">
<ARG
TEXT="2003" TYPE="YEAR"/>
<ARG
TEXT="05" TYPE="MONTH"/>
<ARG
TEXT="16" TYPE="DAY"/>
<ARG
TEXT="17" TYPE="HOUR"/>
<ARG
TEXT="19" TYPE="MINUTE"/>
<SOURCE> 17 19 16. 05. 2003</SOURCE>
</OBJECT>
<OBJECT
ID="2" TYPE="FIO">
<ARG
TEXT="ПУТИН"
TYPE="SURNAME"/>
<ARG
TEXT="ВЛАДИМИР"
TYPE="NAME"/>
<ARG
TEXT="ВЛАДИМИРОВИЧ"
TYPE="SEC_NAME"/>
<SOURCE> Владимир Путин</SOURCE>
</OBJECT>
<OBJECT
ID="3" TYPE="FIO">
<ARG
TEXT="БУШ"
TYPE="SURNAME"/>
<ARG
TEXT="ДЖОРЖ"
TYPE="NAME"/>
<SOURCE> Джордж Буш </SOURCE>
</OBJECT>
<OBJECT
ID="4" TYPE="ORGANIZATION">
<ARG
TEXT="ПРЕСС"/>
<ARG
TEXT="СЛУЖБА"/>
<ARG
TEXT="КРЕМЛЬ"/>
<SOURCE> пресс-служба Кремля</SOURCE>
</OBJECT>
<OBJECT
ID="5" TYPE="PLACE">
<ARG
TEXT="ЧЕЧНЯ"/>
<SOURCE> Чечня</SOURCE>
</OBJECT>
<OBJECT
ID="6" TYPE="USER_OBJECT">
<ARG
TEXT="ПРЕДСТОЯЩИЙ"/>
<ARG TEXT="РОССИЙСКО"/>
<ARG
TEXT="АМЕРИКАНСКИЙ"/>
<ARG TEXT="САММИТ"/>
<SOURCE> предстоящего российско-американского саммита</SOURCE>
</OBJECT>
<OBJECT
ID="7" TYPE="PLACE">
<ARG
TEXT="САНКТ"
TYPE="CITY"/>
<ARG
TEXT="ПЕТЕРБУРГ"/>
<SOURCE> Санкт-Петербурге</SOURCE>
</OBJECT>
<OBJECT
ID="8" TYPE="ORGANIZATION">
<ARG
TEXT="REUTERS"/>
<SOURCE> Reuters</SOURCE>
</OBJECT>
<ACTION
ID="9" TYPE="ПОДЧЕРКНУТЬ">
<ARG
REF="2"/>
<ARG
REF="3"/>
<ARG
TEXT="В"/>
<ARG
TEXT="ХОД"/>
<ARG
TEXT="ТЕЛЕФОННЫЙ"/>
<ARG
TEXT="РАЗГОВОР"/>
<ARG
TEXT="НЕОБХОДИМОСТЬ"/>
<ARG TEXT="НАРАЩИВАНИЕ"/>
<ARG
TEXT="АНТИТЕРРОРИСТИЧЕСКИЙ"/>
<ARG
TEXT="ВЗАИМОДЕЙСТВИЕ"/>
</ACTION>
<RELATION
TYPE="КОГДА">
<ARG
REF="9"/>
<ARG
TEXT="ПЯТНИЦА"/>
</RELATION>
<ACTION
ID="10" TYPE="СООБЩИТЬ">
<ARG
REF="4"/>
</ACTION>
<ACTION
ID="11" TYPE="СОСТОЯТЬСЯ">
<ARG
TEXT="ХОД"/>
<ARG
TEXT="БЕСЕДА"/>
<ARG
TEXT="ПО"/>
<ARG
TEXT="ИНИЦИАТИВА"/>
<ARG
TEXT="АМЕРИКАНСКИЙ"/>
<ARG TEXT="СТОРОНА"/>
</ACTION>
<ACTION
ID="12" TYPE="ВЫРАЗИТЬ">
<ARG
REF="3"/>
<ARG
TEXT="СОБОЛЕЗНОВАНИЕ"/>
<ARG TEXT="В"/>
<ARG
TEXT="СВЯЗИ"/>
<ARG
TEXT="С"/>
<ARG TEXT="НЕДАВНИЙ"/>
<ARG
TEXT="ТЕРАКТ"/>
</ACTION>
<RELATION
TYPE="ГДЕ">
<ARG
REF="12"/>
<ARG
REF="5"/>
</RELATION>
<ACTION
ID="13" TYPE="ОБСУДИТЬ">
<ARG
REF="2"/>
<ARG
REF="3"/>
<ARG
TEXT="ПОВЕСТКА"/>
<ARG
TEXT="ДЕНЬ"/>
<ARG
REF="6"/>
</ACTION>
<RELATION
TYPE="ГДЕ">
<ARG
REF="13"/>
<ARG
REF="7"/>
</RELATION>
<SENTENCE>
<ARG
REF="1"/>
<ARG
REF="9"/>
<SOURCE> 17:19 16.05.2003 Владимир Путин и Джордж Буш
в ходе телефонного разговора в пятницу подчеркнули необходимость наращивания
антитеррористического взаимодействия.</SOURCE>
</SENTENCE>
<SENTENCE>
<ARG
REF="10"/>
<ARG
TEXT="ХОД"/>
<ARG
TEXT="БЕСЕДА"/>
<ARG
REF="11"/>
<ARG
REF="12"/>
<SOURCE>Как сообщила пресс-служба Кремля, в ходе
беседы, состоявшейся по инициативе
американской стороны, президент США выразил соболезнование в связи с недавними
терактами в Чечне.</SOURCE>
</SENTENCE>
<SENTENCE>
<ARG REF="13"/>
<SOURCE>Путин и Буш обсудили также повестку дня
предстоящего российско-американского саммита в Санкт-Петербурге.</SOURCE>
</SENTENCE>
<SENTENCE>
<ARG
REF="8"/>
<SOURCE>// Reuter</SOURCE>
</SENTENCE>
</DOCUMENT>