Методы и средства настройки морфо-лексического анализатора на
предметную область
Н. В. Сомин, И.П. Кузнецов, А.Г. Мацкевич, В.Г. Николаев (все ИПИ РАН).
Аннотация
Рассматривается класс семантико-ориентированных
лингвистических процессоров, выделяющих из текстов естественного языка
информационные объекты и связи между ними. Одной из важнейших компонент таких
систем является блок морфо-лексического анализа. Он выполняет множество
функций, которые выходят за рамки обычных блоков подобного типа: генерирует
семантические признаки лексических единиц, выявляет простейшие формы
естественного языка, имеет специальные средства настройки на особенности
текстов и на предметную область. В работе рассматриваются эти функции, а также
методы и инструменты упомянутой настойки.
Введение
Одна из наиболее перспективных областей информатики на
современном этапе связана с разработкой средств автоматического анализа текстов
на естественном языке. Такого рода программы – лингвистические процессоры (ЛП)
– не раз разрабатывались в прошлом и разрабатываются в настоящее время.
Настоящий авторский коллектив более 20 лет работает в этой области, создав значительный
научных задел [1] и разработав целый ряд ЛП – LOG [6], ЭССЕИСТ [7], ТЕРМИН, ТЕРМИН-2, ТЕРМИН-3,
ТЕРМИН-4 [8,9], ИКС, АНАЛИТИК («Криминал») [1,3], АНАЛИТИК-1, ПОТОК [4,10,11 ].
Особенность ЛП, разрабатываемых в ИПИ
РАН, заключается в их семантической или
объектной ориентации. Задачи таких ЛП – это выделение групп связанных слов, представляющих
собой «объекты» (ФИО лиц, даты, адреса и
др.) и связи между ними. В результате
формируются структуры, которые являются основой Баз Знаний, и соответственно,
различных видов объектных поисков [11,12]. Опыт разработки и эксплуатации этих
программных продуктов показал, что одной из важнейших компонент подобных систем
являются средства настройки на предметную область, с помощью которых
обеспечивается целевое назначение системы.
Настоящая работа посвящена методам и средствам настройки одной из важнейших компонент ЛП –
блока морфо-лексического анализа. От него
зависит качество работы всего ЛП. Этот блок имеет свои особенности,
которые определяются задачами ЛП – необходимостью выделения объектов. Он
выполняет множество функций, которые выходят за рамки обычных блоков
морфологического анализа, например, генерирует семантические признаки
лексических единиц, выявляет простейшие формы естественного языка и многое
другое. В связи с этим данный блок имеет не только практическую, но и
значительную научную составляющую.
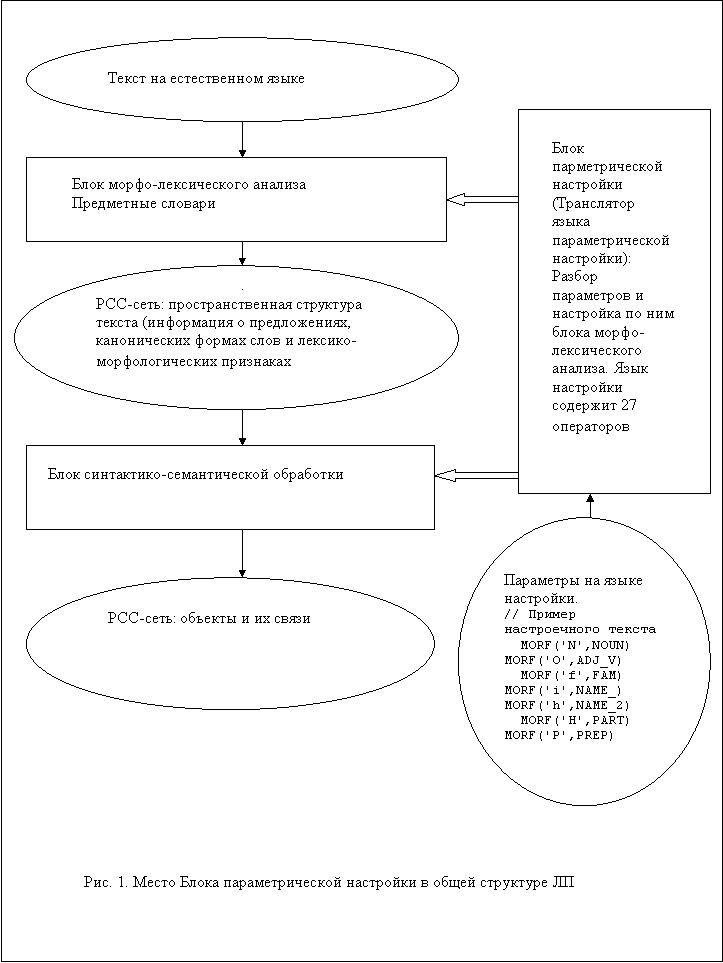
1. Общая структура лингвистического
процессора
Для облегчения понимания методов и средств настройки
дадим основные сведения о структуре и функциях основных компонент ЛП.
Лингвистический процессор
состоит из двух основных блоков - блока
комплексного морфо-лексического анализа (МЛБ) текстовой информации и
блока синтактико-семантической обработки (СБ) - семантического анализатора [3,5].
Блок морфо-лексического анализа преобразует текст в
семантическую сеть, представляющую пространственную структуру текста (ПС-текста).
В этой сети все русские слова нормализованы, т.е. преобразованы в каноническую
форму. При этом задается порядок слов и
их признаки.
Пространственная структура текста подается на вход блока
СБ, который преобразует его в семантическую структуру (СС-текста), которая
также называется содержательным портретом документа [1.5]. Семантическая
структура текста представляет собой объекты и связи между ними.
Блок МЛБ, разработанный для русского языка, основан на
обобщенных окончаниях. В дальнейшем он был модифицирован для работы с
английским языком. Он способен обрабатывать
и новые слова, которые ранее не были введены в этот блок [5]. В этом его существенное отличие. Блок состоит
из двух компонент – лексической и морфологической.
Признаки, которые присваиваются каждому слову, делятся на
три группы:
- лексические признаки (слово с большой буквы, большими
буквами, с точкой на конце или это отдельная буква и др.)
- морфологические признаки (грамматическая категория
слова, число для существительных и т.д.);
- семантические признаки
(фамилия, имя, отчество и др.).
Предусмотренный лексикографический анализ обеспечивает
автоматическое выделение лексических единиц, определение начала и конца
предложения, а также начала и конца абзаца.
Разработанный терминологический анализ обеспечивает
выделение терминов и синонимичные
преобразования. В результате строится семантическая сеть, представляющая ПС-предложений
и всего текста документа. В этой сети слова представляются с их признаками
(фрагментами типа LR). Указываются места, где
заканчиваются предложения (фрагментами типа SENT). В ПС сохраняется
порядок слов.
За счет нормализации морфологический анализ помогает
избавиться от различных форм написания слов, что облегчает поиск.
Блок синтактико-семантического анализа (СБ) состоит из
«контекстных» правил, которые анализируют признаки слов и строят объекты и их
связи. Его основные функции:
- по признакам и контексту выделяет информационные или
значимые объекты (ФИО людей, адреса, организации, номера машин и др.);
- для каждого выявленного значимого объекта находит в
документе связанную информацию (для лиц это их год рождения, пол, адрес и др.);
- осуществляет идентификацию объектов (например, кратких
имен с ФИО и др.);
- анализирует глагольные формы (а также причастные, деепричастные
и другие обороты), по которым выделяются события и действия, связывающие
объекты.
В результате формируется СС-текста.
2. Предметные области и тексты
Предметные области, в которых требуется лингвистическая обработка текстов, чрезвычайно
разнообразны. Причем, это разнообразие заключается не только в различии объектов и действий, присущих той
или иной предметной области. Еще большие отличия можно наблюдать в «стиле»
текстовых сообщений, порождаемых предметными областями. В понятие «стиль» мы
включаем весь комплекс особенностей, присущих определенной группе текстов. Сюда
входят:
- лексика предметной области, включая всю совокупность
специфических терминов предметной области;
- коммуникативный тип текста: художественное
произведение, техническая или аналитическая статья, новостное сообщение,
приказ, PR- текст (например – реклама);
- структурный тип текста: связный текст, список, таблица,
математическая формула;
- инструмент создания текста – имеется в виду текстовый
редактор или генератор текста, с помощью которого получен текст;
- способ грамматического оформления текста, под
которым понимается следование
стандартным правилам орфографии языка: проставление необходимых знаков
препинания и разделителей, позволяющих структурировать текст;
- следование принятой в языке орфографии, что выражается
в количестве орфографических ошибок или нарочитого введения искаженной лексики.
Отметим, что резкое увеличение разнообразия текстовой
типологии инициировано бурным распространением Интернет. Порождением текстов
начинают заниматься люди, фактически к этому не готовые. Опишем, некоторые
характерные задачи и соответствующие трудности, с которыми приходится
сталкиваться разработчику ЛП уже на первой стадии лексического анализа текста.
Выделение
абзацев и предложений. Под абзацем
понимается часть текста, связанная единой темой. Под предложением мы понимаем грамматически оформленную часть
абзаца, описывающего некое единичное действие, ситуацию, символ или
коммуникативный акт. Разумеется, такие определения являются упрощенными и не
вполне соответствуют понятиям, выработанным в теории языка. Но для
семантического анализа членение текстового потока именно на такие фрагменты
является наиболее желательным. Однако конкретные тексты далеко не всегда
позволяют такое членение провести.
Трудности выделения абзацев главным образом связаны с
тем, что хорошо различимые разделители абзаца – пустые строки, отступы, границы
клеток таблицы – теряются или искажаются при преобразовании текстов. Но гораздо
большие трудности возникают при выделении предложений. Дело в том, что
современные пользователи Интернет вообще не считают необходимым ставить точки в
конце предложения. В то же время, точка активно используется в качестве
ограничителя сокращений, разделителя между частями таких компонент, как электронные адреса, дробные числа, банковские
номера и др. Кроме того, разделителем предложения может являться не только
точка, но и другие знаки («;», «:», «!», «?», «|»? и проч.). В результате
задача разбиения текста на предложения становится просто головоломной,
требующей учета массы разных частных правил и
исключений.
Выделение слов.
Эта задача также не является
тривиальной. Современный деловой текст содержит большое количество лексем,
являющихся техническим названиями, телефонами, шифрами, номерами автомобилей,
адресами электронной почты и Интернет и проч., содержащими цифры, буквы и
разделители практически в произвольной комбинации. Поэтому, такие знаки как
«-», «.» и «,» доставляют много хлопот
при их анализе, в одних случаях являясь разделителями лексем, а в других – нет.
Множественность
написания и грамматические ошибки. Очень часто одно и то же понятие выражается
несколько разными словами или разными написаниями одного и того же слова.
Крайне желательно эти несовпадающие написания унифицировать. Но, во-первых,
таких написаний довольно много. А во-вторых, не так-то просто эти написания
выявить. К этой сложности примыкает проблема дезавуирования опечаток и
грамматических ошибок. В современных текстах их – громадное количество, и бороться
с ними – задача из сложнейших. Кроме того, в современных текстах, особенно из
Интернет, намечается тенденция нарочитого переделывания и перевирания слов,
типа «ацкий ужос» или «патстол». Начинает формироваться целая
интернетная «феня», причем дело доходит
до того, что «непосвященному» подчас просто невозможно разобрать смысл
сообщения. Если на настоящем этапе эти эффекты языка можно не учитывать, то в
будущем корректировка языковых словарей и правил составления предложений будет
необходима.
Выделение
характерных смысловых словосочетаний. Имеются
в виду такие словосочетания, как, например, географические адреса, наименования
стран и национальностей. Такие знания необходимы для понимания многих текстов и
потому могут рассматриваться как общие.
Кроме того, для каждой предметной области имеется свой набор характерных
терминов. Их необходимо четко распознавать, несмотря на вариации в написании. Особым случаем
являются сокращения, которых в современных текстах большое количество.
Универсальность
и вариативность морфологического анализа. Морфологический
анализ текста является основой его успешного понимания. Однако, к алгоритму
морфологического анализа русских слов предъявляются высокие и даже противоречивые требования. С
одной стороны, он должен иметь высокую
универсальность, правильно распознавая подавляющее большинство русских слов,
включая и современный «новодел». С
другой стороны, он должен обладать свойством избирательности к предметным
областям, оставляя только те варианты анализа, которые в этих областях имеют
смысл.
3. Методы настройки.
Идеология.
В настоящей работе преодолеть указанные выше трудности
предлагается с помощью специальных методов и инструментов настройки ЛП на
предметную область и тип текста. Суть методов и их возможностей следует
раскрыть более подробно.
Интересный вопрос, а есть ли альтернатива методу
настройки? Да, конечно есть. Это – реализация системы искусственного интеллекта, которая (подобно человеку) в
процессе освоения естественного языка
использует методы самообучения, обучения по примерам, связывает компоненты ЕЯ с картинами внешнего мира и много другое. Думается,
что такая постановка задачи преждевременна. Она требует моделирования если не
всего. то значительной части знаний человека, что пока не под силу не только нашей, но и мировой информатике.
Поэтому авторы метода ясно сознают, что получить практически значимые
результаты можно, если настройку на тип текста осуществляет человек.
Собственно, этот вывод очевиден. Другое дело – конструирование инструментов
настройки. Здесь возникает несколько вопросов.
Во-первых, какие уровни аналитической системы должны
подвернуться параметризации?
Во-вторых, насколько глубоко должен воздействовать аппарат настройки?
Иными словами, насколько система должна
быть параметризованной?
Наконец, в-третьих, каков должен быть инструмент
настройки? Соответственно, какова должна быть квалификация оператора, его
трудозатраты и финансовая рентабельность?
Эти вопросы требуют серьезного обсуждения.
Уровни
настройки. Исходя из многолетнего опыта
разработки систем анализа текстов, может быть предложена следующая схема. Как уже говорилось, семантико-ориентированные
ЛП состоят из двух основных блоков: морфо-лексического блока (МЛБ) и
семантического блока (СБ). Разумеется, настроечные механизмы, рассматриваемые в
этом отчете, предназначены для осуществления корректной работы СБ. Однако, для
этого необходимо параметризовать и работу МЛБ и работу СБ. При этом реализация
механизмов настройки возлагается на МЛБ. И это не удивительно – МЛБ вплотную
сталкивается с еще необработанным текстом. Конечно, СБ сам в своем составе
содержит механизмы настройки. Но они в значительной степени завязаны на
лингвистические знания (ЛЗ), которые описаны в [1,3,11] и в настоящей работе не
затрагиваются.
Морфо-лексический блок в свою очередь имеет три основных компоненты:
1.
Блок лексического
анализа. Он ответственен за правильное деление входного текстового потока на
абзацы, предложения и слова.
2.
Блок
морфологического анализа, осуществляющий морфологический анализ всех слов текста.
3.
Систему тематических
словарей, призванную распознать в тексте характерные термины.
Каждый из этих блоков представляет собой довольно сложную
подсистему, исполняющую важную функцию, результат которой существенно зависит
от текста. Поэтому настроечные функции должны влиять на все три блока: лексического анализа, морфологического анализа и системы тематических словарей.
Глубина
настройки. Чем больше глубина настройки,
тем более гибко оператор может
управлять процессом разбора и лучше приспосабливаться к особенностям текста.
Поэтому необходимо большое разнообразие инструментов настройки. Хотя в то же
время они должны образовывать непротиворечивую и (желательно) не избыточную
систему. Кроме того, для минимизации ошибок крайне желательно обеспечить легкость
и наглядность настроечных средств.
Язык
параметрической настройки. Критерии системности и наглядности требуют
выстроить все средства настройки в виде некоего языка настройки,
обрабатываемого специальным транслятором языка параметрической настройки. При
этом встает задача разработки такого
языка. Поскольку СБ выполнен на языке ДЕКЛ [1], в котором и программа и данные
кодируются на языке расширенных семантических сетей (РСС), то естественным
образом большинство результатов
настройки оформляется в виде РСС, и
таким образом, непосредственно доступны СБ. Отметим, что ряд операторов
настройки не производит никаких изменений в РСС, а служит для адаптации самого
МЛБ к особенностям текста.
Вопрос о входном языке
настройки более проблематичен. В принципе, его стиль зависит от знаний
оператора. Опыт разработки систем текстового анализа показал, что таким
«оператором», как правило, является сам разработчик прикладной аналитической
системы, хорошо владеющий языком ДЕКЛ. Поэтому было решено, что синтаксически
язык настройки будет представлять собой совокупность фрагментов РСС, где имя
фрагмента будет являться именем настроечного оператора. Язык настройки представляет собой подмножество языка
ДЕКЛ. Каждое запись представляет собой фрагмент ДЕКЛа (или РСС), в общем случае – произвольной местности.
Записи могут следовать в произвольном порядке. Возможно указание
примечаний. Всего реализовано 27 типов фрагментов, каждый из которых ответственен за определенный вид настройки.
Из них 18 параметризует блок лексического анализа, 5 – блок морфологического
анализа и 4 – словарную систему.
В виду синтаксической простоты
языка РСС, такое решение дает
возможность сделать транслятор
параметрической настройки относительно
простым. В то же время гибкость языка РСС высока, позволяя представлять сложные
параметрические структуры. Взаимодействие МЛБ и упомянутого транслятора иллюстрируется
рис. 1.
Система предметных словарей. Ее идеология требует особого рассмотрения.
Как указывалось, система тематических словарей
предназначена для распознавания в тексте характерных словосочетаний и тем самым
присвоения им признака принадлежности к определенной семантической категории.
Система состоит из совокупности словарей, в каждом из которых записаны термины
(в общем случае – многословные), относящиеся к определенному классу вещей или
предметов. Например, предметный словарь «Города» содержит названия городов (как
в России, так и за рубежом), словарь «Улицы Москвы» содержит названия всех улиц
г. Москвы. Всего к моменту написания отчета (осень
Касаясь идеологии метода настройки, укажем, что сама
словарная система является мощным инструментом настройки. Подключение новых
словарей дает новые семантические признаки слов для блока СБ и таким образом значительно усиливает аналитическую мощь всего
ЛП. Однако, чтобы словари в самом деле стали действенным и удобным механизмом,
необходимо, чтобы они обладали рядом нетривиальных возможностей. В нашей версии
словарной системы реализованы следующие из них.
1. Идентификация термина в любом числе и падеже.
Например, если в словаре есть термин «программный продукт», то в тексте будут
распознаваться и соответствующим образом идентифицироваться термины
«программного продукта», «программных продуктов» и т.д. Распознавание выполняет
программное обеспечение системы тематических словарей, использующее блок
морфологического анализа.
2. Допускается несколько вариантов написания одного и
того же термина. Например, в словаре может иметь место запись:
Меркель Ангела
= Ангела Меркель
= А. Меркель
= Меркель
Тут основной термин Меркель
Ангела. К нему будут приводиться все остальные написания этого имени,
записанные после символа «=». Эта возможность особенно эффективна при вводе ФИО
известных деятелей, названий организаций (включая их сокращения) и
географических названий. Такая запись значительно облегчает работу блока СБ по
выделению лиц, но и ставит дополнительные задачи фильтрации. Например, если в
тексте встретилось слово Меркель, но
с другим именем или инициалами, то это значит, что появилось другое лицо и
замена отдельных слов Меркель на Меркель Ангела
временно блокируется.
3. Имеется возможность описания множества терминов, у
которого лишь первое слово фиксировано, а остальные могут быть описаны с
помощью совокупности признаков (лексических и морфологических). Например, в словаре допустима строка:
заведующий
{NOUN,КЕМ}

Такая запись означает, что подходящими под этот шаблон
терминами могут быть все, начинающиеся со слова «заведующий», за которым идет существительное (NOUN) в винительном падеже (КЕМ): «заведующий складом», «заведующий библиотеками» и т.д.
4.
Имеется возможность
управлять лексическим и морфологическим анализами в процессе распознавания
терминов словарей. Так, например, в словаре
может быть указано:
Организация эта\
= ЭТА\!
Это означает, что, благодаря признаку «\», слово «эта» в процессе идентификации
морфологическому анализу не подвергается (т.е. его каноническая форма совпадает
с написанием). И, кроме того, благодаря признаку «!» идентификация совершается,
если в одиночном написании «ЭТА» (название
террористической организации) записана прописными буквами. Эти возможности
позволяют повысить точность распознавания, отсеивая ложные вхождения.
5. Язык записи терминов чрезвычайно прост: термин пишется
в своей канонической форме на отдельной строке (включая, разумеется, указанные
в пп. 3 и 4. дополнительные
возможности). Поэтому ввод новых терминов или даже заведение новых словарей
может быть выполнено пользователем или оператором-лингвистом, не знакомым с
особенностями работы аналитической системы. В п. 8 приводится описание
специальных программных средств,
предназначенных для пополнения тематических словарей.
Помимо указанных возможностей, встроенных в язык ввода
терминов, имеется еще ряд специальных операторов настройки, позволяющих
управлять идентификацией терминов для тех или иных словарей, см. п. 5.
4. Лексический блок и его операторы
настройки
В данном параграфе основное
внимание уделяется описанию РСС-фрагментов, генерируемых блоком МЛБ в выходной
текстовых поток. От этих фрагментов зависит работа блока СБ, который должен
получать полный набор признаков, необходимых для выделения семантических
компонент и связей.
Лексический блок, как
указывалось ранее, выполняет разбиение входного текстового потока на абзацы,
предложения и слова, выдавая в виде РСС-фрагментов соответствующую информацию.
Информация об абзацах и предложениях отображается в виде фрагментов SENT, имеющих
вид:
SENT(1-,A,B,C,1+/2+) 1-(D)
где:
A – позиция
первого слова предложения относительно начала входного потока;
B – 0, 1 или 2 – признак начала абзаца (1 или 2);
C – номер
первого слова предложения относительно начала входного потока;
D – номер
строки входного потока, на которой расположено первое слово предложения.
Для каждого слова (и для
каждого варианта его разбора) блок выдает в виде РСС-фрагментов следующие
лексические признаки (при их наличии):
2-(NAME0) – слово начинается с
прописной буквы;
2-(HEAD_) – слово полностью
состоит из прописных букв;
2-(NAME1) – И. или О. – т.е. сокращение имени или
отчества (прописная буква, за которой идет точка);
2-(POINT) – сокращение;
2-(HEAD_1) – слово из букв, среди
которых более одной прописной;
2-(NUM) – целое число;
2-(NUM_F) – число с дробной
частью;
2-(ENGL) – слово из букв
латинского алфавита;
2-(WEB_C) – URL (адрес
Интернет);
2-(MAIL_E) – адрес электронной
почты;
2-(FIRST_) – признак первого
слова на новой строке;
2-(LETT) – слово состоит из одной
буквы.
Информация по настроечным
операторам лексического блока для наглядности сведена в Табл. 1. Под N понимается местность оператора, а прочерк
означает произвольную местность.
Таблица 1. Настроечные
операторы лексического блока.
|
Имя оператора |
N |
Назначение |
Прагматика использования |
Пример оператора |
Пример генерируемых фрагментов или
действий |
|
MORF |
2 |
Определение лексических признаков
слова |
используется для более удобного
использования лексических и морфологических признаков слова |
MORF ('0',HEAD_) |
2-(HEAD_) |
|
LETTER_CH |
2 |
Замена отдельных знаков в тексте |
Замена нежелательных знаков на
приемлемые |
LETTER_CH ('<',
'A') |
Символ
‘<’ заменяется на ‘A’ |
|
SEPARATOR |
- |
Указание символов, которые всегда
являются разделителями |
|
SEPARATOR ('+', ':') |
|
|
WORD_BAD |
2 |
Замена слова |
Замена запрещенных (по техническим причинам)
слов на приемлемые |
WORD_BAD('*', '
') |
Слово «*»
заменяется на пробел |
|
SYNON |
- |
Замена слова на указанное в первой
позиции |
Удобен для унификации написания слов |
SYNON(ДЕР., ДЕР, ДЕРЕВНЯ) |
Слова «дер»
и «деревня» заменяются на «дер.» |
|
TERMIN_ |
- |
Термин, записанный на второй и далее позициях,
заменяется на слово в первой позиции |
Удобен для унификации терминов и
словосочетаний |
TERMIN_( МИКРОРАЙОН, М,\,РН) |
Словосочетание
«м / рн» заменяется на «микрорайон» |
|
NEW_SENT |
- |
Если указанное во фрагменте слово записано
с прописной буквы и находится в начале строки текста, то оно рассматривается
как начало нового предложения. |
Определение начала предложения в
нестандартных случаях. Допустимы знаки * заменяющие окончание или указание
части речи, типа *V,*T |
NEW_SENT( ANALYSIS, ASSUR*) |
Если слово Analisis
или Assurance стоит в начале строки, то оно рассматривается как
начало предложения |
|
ABBR_ |
- |
Все слова должны содержать символ
'-'(минус); тогда данное слово рассматривается как целое ('-' не служит
разделителем между словами) |
|
ABBR_(ГР-Н, ГР-НЕ,ГР-НА, ГР-КА) |
Словосочетания
ГР-Н,ГР-НЕ,ГР-НА, ГР-КА рассматриваются
как цельные слова |
|
ABBR |
- |
Список сокращений с точками на конце,
которые считаются цельными словами и точки не рассматриваются как конец
предложения |
Корректное опознание конца
предложения |
ABBR (Inc.,Ltd.) |
Словосочетания
«Inc.» и «Ltd.»
рассматриваются как сокращения |
|
END_SENT |
- |
Если в тексте встречается одно из
указанных слов (символов, знаков), то оно считается концом предложения |
|
END_SENT(';') |
Точка с
запятой рассматривается как конец предложения |
|
WORD_NEW_S |
- |
Если перед словом, которое
удовлетворяет критериям фрагмента NEW_SENT стоит символ или слово (из одной
буквы), указанное в данном фрагменте, то этот символ рассматривается как
начало предложения, причем этот символ из предложения удаляется |
Корректное определение начала
предложения |
WORD_ NEW_S( *,№) и указано NEW_SENT (КОРРЕКТОР) |
Словосочетание
№ Корректор рассматривается
как начало предложения (без №). |
|
BEG_SYMB |
- |
Отделяемые знаки в начале слова |
Отсев шумовых символов |
BEG_SYMB($) |
|
|
END_SYMB |
- |
Отделяемые знаки в конце слова |
Отсев шумовых символов |
END_SYMB($) |
|
|
B_SENT |
4 |
Определение начала предложения, когда
в начале строки стоит слово или символ в первой позиции |
Корректное определение начала
предложения. Имеет ряд модификаций |
B_SENT('?',, NAME0,) |
Символ '?' (вначале строки)
определяет начало предложения, если за ним слово с прописной буквы |
|
SIGN_MANY |
1 |
Указанный символ, если он повторяется
более 3-х раз, образует одно слово |
Для определения разделительных линий
в тексте |
SIGN_MANY ('-') |
Линия "------"
рассматривается как одно слово |
|
BEG_SENT |
|
Устаревшая форма B_SENT |
|
|
|
5. Морфологический блок и
его операторы настройки
Задачей морфологического блока является определение
морфологических характеристик и канонической формы каждого слова. Этой
информация поступает на вход блока СБ. Описание механизмов морфологического
разбора и структуры морфологических словарей дано в [2] и потому в настоящей работе
не приводится. Отметим лишь некоторые важные особенности рассматриваемого блока
морфологического анализа.
1.
Блок дает точный и
полный морфологический анализ всех русских и английских слов, заложенных в
морфологический словарь. Объем словарей: русского - около 90 тыс. основ,
английского – около 85 тыс. основ.
2.
Блок дает предполагаемый
морфологический анализ слов, не входящих в морфологический словарь. При этом
алгоритм анализа построен на аналогии со словом, которое распознается точно.
Практика показала, что в подавляющем
большинстве случаев предполагаемый морфологический анализ оказывается
верным.
3.
В общем случае
выдается несколько вариантов морфологического анализа. Эта ситуация, известная
в лингвистике под названием омонимия является весьма частой. Например, слово «стекло» является и существительным и глаголом. Чтобы зафиксировать множественность вариантов
морфологического разбора, во входном потоке генерируется фрагмент LR для первого варианта разбора и фрагменты LD для прочих вариантов. Например, для слова «что» выдается
следующий набор РСС-фрагментов:
LR(1-,'ЧТО','M4?ив',1869,1+/2+) 2-('ЧТО') 2-(PRON)
LD(1-,'ЧТО','R',1869,1-/2+) 2-('ЧТО') 2-(ADV)
LD(1-,'ЧТО','Ss',1869,1-/2+) 2-('ЧТО') 2-(CONJ)
Каждый из
фрагментов LR и LD – пятиместные.
Первая и пятая позиции (а также поле после разделителя «/») служат для связи
данных фрагментов со всей остальной семантической сетью. Четвертая позиция –
номер слова в тексте. Во второй позиции записана каноническая форма слова. В
третьей позиции записаны морфологические признаки, причем каждый из них
закодирован одним символом. В нашем случае первый вариант разбора определяет
«что» как вопросительное местоимение в именительном или винительном падеже.
Второй вариант разбора рассматривает «что» как наречие. Наконец. третий вариант
разбора представляет это слово как союз.
Выбор одного из вариантов осуществляется
блоком СБ в процессе синтактико-семантического анализа с использованием контекстных
правил, с помощью которых осуществляется разбор предложений с выделением
объектов и связей.
4.
Морфологический блок
выдает каноническую форму каждого слова. Опционально, каноническая форма может
быть выдана для слов женского или среднего рода (причастия и прилагательные) и
для слов множественного числа (существительные, причастия и прилагательные). В
нашем примере каноническая форма слова дублируется с помощью фрагмента 2-('ЧТО').
Настроечные операторы морфологического блока представлены
в Табл. 2.
Таблица 2.
|
Имя оператора |
N |
Назначение |
Прагматика использования |
Пример оператора |
Пример генерируемых фрагментов или
действий |
|
MORF |
2 |
Определение морфологических признаков
слова |
используется для более удобного
использования лексических и морфологических признаков слова |
MORF('R',ADV) |
2-(ADV) |
|
NOMO |
- |
запрет на морфологический анализ
слова |
Необходим для случаев, когда
морфологический анализ нежелателен или дает неверный результат |
NOMO('Абу', 'Ибн', 'Усама','тем', 'Шайгу','Чавес') |
Третья
позиция фрагментов LR и LD для указанных слов остается
незаполненной |
|
NOMOE |
2 |
Для английского языка; указание
совокупности морфологических признаков |
Корректировка результатов
автоматического морф. анализа |
NOMOE(BAYER, ' ') |
для “bayer”
морфологические признаки не формируются |
|
WORD_ENG |
|
|
|
|
|
6.
Генерация «терминологических» фрагментов
Передача информации из системы предметных словарей о найденном термине осуществляется
с помощью «терминологических» фрагментов.
Таких фрагментов несколько:
1) «каноническая форма термина», например
1-('программный','продукт')
В данном фрагменте пословно содержится первое (без «=»)
написание термина.
2) фрагмент CONT_K, служащий для связи LR (или LD) фрагментов,
относящихся к одному словарному термину;
3) фрагмент <имя_словаря>, служащий для указания
принадлежности термина к указанному в имени фрагмента словарю. Например,
фрагмент
OBJ_K(2-,CONT_K)
указывает, что это первое слово многословного термина из словаря OBJ_K. О том, что термин многословный (т.е.
имеются слова, являющиеся его продолжением) говорит вторая позиция CONT_K.
4) фрагмент 2-(<имя_словаря>), употребляемый в
случае однословных терминов.
Чтобы уяснить взаимосвязь данных фрагментов, рассмотрим
разбор предложения: «Внедрение программного продукта в МГУ»:
LR(1-,'ВНЕДРЕНИЕ','NсXФви7',1,1+/2+) 2-('ВНЕДРЕНИЕ')
2-(NOUN) 2-(NAME0) 2-(FIRST_)
LD(1-,'ВНЕДРИТЬ','Tш~Ш(ЭTbк<7',1,1-/2+) 2-('ВНЕДРИТЬ') 2-(PRICH) 2-(SHORT_) 2-(NAME0) 2-(FIRST_)
LR(1-,'ПРОГРАММНЫЙ','Aрвмс.',2,1+/2+) 2-('ПРОГРАММНЫЙ') OBJ_K(2-,CONT_K) 1-('программный','продукт') 2-(ADJ) 2-(КОГО)
LR(1-,'ПРОДУКТ','NмXФр',3,1+/2+) 2-('ПРОДУКТ') CONT_K(2-,OBJ_K)
2-(NOUN) 2-(КОГО)
LR(1-,'В','Pпв',4,1+/2+) 2-('В') 2-(LETT) 2-(PREP)
LR(1-,'МГУ','0',5,1+/2+) 2-('МГУ') 2-(ORG_K) 1-('МГУ') 2-(HEAD_) 2-('МГУ',WORD) 2-(RUS)
LR(1-,'.','',6,1+/2+) 2-('.')
В этом предложении система предметных словарей распознала
два термина: «Программный продукт» из
словаря OBJ_K и 2) «МГУ» из словаря ORG_K. Для первого термина был сформирован фрагмент 1-('программный','продукт'), фрагмент OBJ_K(2-,CONT_K) и (для второго слова) фрагмент CONT_K(2-,OBJ_K), говорящий о том, что
слово «продукт» является
продолжением термина из словаря OBJ_K. Для второго термина был сформирован «канонический»
фрагмент 1-('МГУ') и фрагмент 2-(ORG_K), говорящий о том, что данное слово является однословным
термином из предметного словаря ORG_K.
Такая запись многословных терминов объясняется
особенностью работы блока СБ, который осуществляет дополнительную фильтрацию,
используя одни термины для построения объектов и блокируя другие.
Например, если термин взят из словаря
имен собственных Name_k.slv, то делается
дополнительная проверка, что слово с большой буквы. Отдельно анализируются
слова типа Владимир (это может быть
город или имя), Николаев, Лев и др.
Часто города (столицы) используются в другом смысле – как правительства: Вашингтон предложил Москве … Одна из
задач блока СБ – уточнение семантической компоненты.
Настроечные фрагменты для системы предметных словарей
приведены в Табл. 3.
Таблица 3
|
Имя оператора |
N |
Назначение |
Прагматика использования |
Пример оператора |
Пример генерируемых фрагментов или
действий |
|
MAKE_FR |
- |
Указать на особую форму генерации
выходных фрагментов для указанных словарей |
Для удобства обработки |
MAKE_FR( TERROR_K, WORK_K, ORG_K) |
|
|
BAD_DIC |
- |
Указать слова, игнорируемые при
идентификации термина |
такие слова можно привязать к
конкретным словарям |
BAD_DIC( 'TERROR_K','-') |
|
7. Средства корректировки
предметных словарей
7. Интерфейсная компонента предметных словарей
Для корректировки и пополнения предметных словарей
разработан комплекс программных средств, обеспечивающих необходимый интерфейс
для пользователя.
Пользователь имеет возможность выбрать нужный словарь (см. рис 2), ввести новый термин или скорректировать уже
имеющийся (см. рис.3).
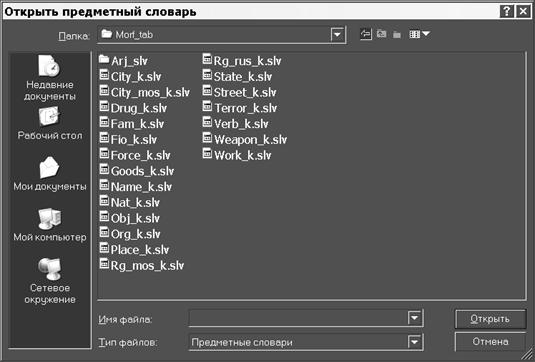
Рис. 2. Выбор словаря.
Эти словари являются основой выделения объектов.
Например, словарь имен собственных Name_k.slv является основой для выделения
лиц, словарь Org_k.slv – основой для выделения организаций и т,д,
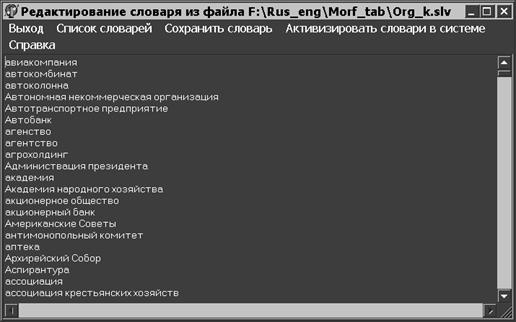
Рис. 3. Ввод/корректировка термина в словарь.
8. Правила настройки предметных словарей
Напомним, что основой лингвистического процессора (ЛП)
являются правила выделения информационных объектов и установления связей между
ними. Такие правила образуют лингвистические знания системы. В процессе
выделения большую роль играют ключевые слова и словосочетания (ядерные
конструкции). Если система находит такое слово в тексте, то делается попытка
выделения соответствующего информационного объекта. Часть ключевых слов и
словосочетаний (в том числе, неоднозначных по смыслу) находится в ЛЗ, другая
часть вынесена в предметные словари.
Итак, словари соответствуют информационным объектам -
участвуют в их выделении. Информационные объекты делятся на классы. Каждый
класс находится в своем файле *.slv.
Предметные словари являются общими для русского и
английского языков. В каждом из них вначале идут (желательно в алфавитном
порядке) слова и словосочетания русского языка, а затем - английского. Эти
слова выявляются из текстов в процессе морфологического анализа, где им
присваиваются соответствующие признаки.
Правило 1. Для
русского слова или словосочетания, входящего в какой-либо словарь, в анализируемом
тексте выявляются все его словоформы, а для английского - только слова,
совпадающие по всем буквам.
Например, если в словаре Field_k.slv
имеется слово семантика, то в
предложениях будут выявляться слова семантики,
семантикой и др. Для слова semantics будет выявляться только это слово. Слово semantic не
будет замечено.
Правило 2. Каждый
пункт словаря (слово, набор слов) должен находиться в своей строке. Переносы
недопустимы. Не имеет значения, какими буквами (большими, маленькими или с ББ)
написаны слова.
Правило 3. В словарь
(по возможности) следует вносить слова или словосочетания, которые не могут
существовать вне соответствующего информационного объекта. Такие слова не
должны входить в другие информационные объекты или быть часто встречающимися
словами русского (английского) языка, употребляемыми в другом смысле. Например,
в словарь Org_k.slv может входить слово институт, но не должно быть слова Центр или Группа (они
могут обозначать совсем другое). Правильнее – торговый центр или группа
компаний.
При необходимости в словарь может быть включен весь
информационный объект, например, МГУ им.
М.В.Ломоносова. Тогда захватывается ФИО, которое система не будет пробовать
распознавать как другой объект - человек.
Правило 4. В
каждом словаре имеется базовый набор, отлаженный на тестовых документах
(анкетах). В этом наборе могут быть пункты, которые завязаны на ЛЗ. Поэтому
менять базовый набор не желательно.
Правило 5. Если
система распознает какой-либо информационный объект не полностью или не может
распознать его вовсе, то нужно ввести его в соответствующий словарь.
Например, в тексте встретилось sales manager, а
распознано лишь manager (из раздела «занимаемая должность»). Тогда в словарь Work_k.slv следует ввести все словосочетание – sales manager. Аналогичное
нужно сделать, если в разделе «занимаемая должность» вообще ничего не
оказалось. Сказанное относится к другим информационным объектам.
Правило 6. Если
система неправильно соотнесла какой-либо набор слов к информационному объекту
(а этот набор таковым не является), то следует это набор (или его ядерную
конструкцию) ввести в словарь «других объектов» - Obj_k.slv.
Тогда они будут рассматриваться как словосочетания, не относящиеся к
информационным объектам.
Правило 7. Следует
помнить, что ЛП (его блок СБ) содержит множество контекстных правил анализа
текста, позволяющих формировать и дополнять информационные объекты в
соответствии с грамматикой русского (английского) языка.
Например, для русского языка работают типовые правила:
<прилагательное><существительное, согласованное с ним по р.ч.п.>
или <существительное><существительное в род.п.> и множество других
правил. Поэтому нет необходимости вводить в словари все встретившиеся в текстах
информационные объекты, а только ключевые слова или их ядерные конструкции.
Правило 8. В ЛП
(его лингвистических знаниях) имеются правила распознавания ключевых слов и
ядерных конструкций по контексту.
Например, если после даты стоит слово, написанное
большими буквами (не более 6 букв) и заканчивающееся на ГУ, ТУ и др., то этому слову присваивается признак организации,
например, МВТУ, МГУ и т.д. Поэтому
нет необходимости вводить в словари названия всех высших учебных заведений или
организаций (их очень много и их количество постоянно растет).
Заключение
Описанный в
данной статье блок морфо-лексического анализа использован в различных
прикладных системах, ориентируемых на автоматическую формализацию текстов
естественного языка (русского и английского), т.е. на выделение информационных
объектов и связей. На этой основе может осуществляться автоматическое формирование
Баз Знаний или заполнение Баз Данных. Функционал блока делает возможным его
использование для различных классов аналитических и логико-аналитических
систем. Настроечные механизмы позволяют достаточно быстро настраивать
прикладные системы на предметную область
пользователя.
Литература
1. Кузнецов И.П., Мацкевич А.Г. Семантико-ориентированные
системы на основе баз знаний (монография). М. МТУСИ,
2. Сомин Н.В., Соловьева Н.С.., Шарнин М.М. Система
морфологического анализа: опыт эксплуатации и модификации. Системы и средства
информатики, Вып. 15, 2005, стр. 20-30.
3. Igor Kuznetsov, Elena
Kozerenko. The system for extracting semantic information from natural language
texts // Proceeding of International Conference on Machine Learning. MLMTA-03, Las Vegas US, 23-26 June 2003, – С. 75-80.
4. Кузнецов И.П.
Сомин Н.В. Англо-русская система извлечения знаний из потоков информации в интернет-среде.
Сб. Системы и средства информатики, Вып. 17., -М.: Наука. 2007. – С.236-253.
5. Сомин Н.В., Соловьева Н.С.., Шарнин М.М. Система
морфологического анализа: опыт эксплуатации и модификации. Системы и средства
информатики, Вып. 15, 2005, с. 20-30.
6. Любушкина Л.А.,
Михеев А.С., Соловьева Н.С., Сомин Н.В., Фрейдлин И.Я. LOG - программа, ведущая диалог на
естественном языке.//Вторая всесоюзная конференция по искусственному интеллекту
"ВКИИ-90"./ Всесоюзная выставка интеллектуальных систем
"Программное обеспечение и прикладные системы ИИ", Минск:
Центрпрограммсистем, 1990.
7. Карунин
А.Б., Соловьева Н.С., Сомин Н.В. ЭССЕИСТ – программа, ведущая диалог
с базой
знаний на естественном языке. // В кн.: Социальная
информатика-93 / Сб. научн. трудов под ред. Колина К.К. и Суслакова Б.А. -М.,
1993. -С. 168-174.
8. Соловьева Н.С.,
Сомин Н.В. ТЕРМИН-3 - система динамического
гипертекста.// Системы и средства
информатики. Вып.7. -М.:Наука, 1995. -С.95-104.
9. Сомин
Н.В., Соловьева Н.С., Соловьев С.В. Система рубрикации текстовых
сообщений. //Труды Междунар. семинара Диалог'98 по компьютерной лингвистике и
ее приложениям: В 2-х т. Т. 2./Под ред. А.С. Нариньяни. - Казань: ООО
"Хэтер", 1998. - С. 574-581.
10. Кузнецов
И.П. Особенности организации семантико-ориентированных систем обработки неформализованных
документов. Сб. ИПИ РАН, Спец.вып. под ред. Колина К.К.
11..
Кузнецов И.П., Сомин Н.В. Средства настройки семантико-ориентированного
лингвистического процессора на выделение и поиск объектов ИПИ РАН, Вып.18.
12. Кузнецов И.П. Объектно-ориентированная
система, основанная на знаниях в виде XML-представлений.
Сб. ИПИ РАН, Вып.18. 2008 г., стр. 96-118