Особенности настройки
объектно-ориентированного лингвистического процессора на тексты предметной области
Кузнецов Игорь Петрович (igor-kuz@mtu-net.ru),
Сомин Николай Владимирович (somin@post.ru)
Институт
проблем информатики РАН
Аннотация
Рассматривается
лингвистический процессор, выделяющий
информационные объекты и связи из
текстов естественного языка (ЕЯ) с формированием структур знаний.
Анализируется
опыт построение таких процессоров в различных предметных областях. В силу
высокого разнообразия форм, которые используются в ЕЯ
для описания различных объектов и явлений, построить сколь-нибудь полную
«модель языка» - неразрешимая задача. Поэтому важной компонентой
лингвистического процессора, осуществляющего формализацию потока текстов, являются средства настройки на неучтенные конструктивные
особенности различных компонент входных текстов. В статье рассматриваются такие
средства на уровне синтактико-семантического анализа.
Введение
Проблема
автоматического извлечения знаний (Knowledge Extraction) из текстов
естественного языка (ЕЯ) является одной из важнейших в области когнитивных
технологий. Ее актуальность постоянно растет в связи с увеличивающимися
потоками текстов (в том числе, через Internet), из которых требуется выбирать компоненты, интересующие
пользователя. В идеале они должны быть
представлены пользователю в наиболее сжатом и понятном виде. Для этого
требуется разработка специальных лингвистических процессоров (ЛП),
осуществляющих формализацию текстов, их преобразование в структуры знаний.
Помимо этого, требуется разработка обратных ЛП, использующих эти структуры для
формирования конструкция ЕЯ, предоставляемых пользователю. Это могут быть
краткие описания, аннотации, табличные формы и др.
Построение
таких ЛП – сложнейшая задача. Наш опыт показывает, что
при наличии потока документов, требующих обработки, учесть все формы и
особенности ЕЯ, используемые при описании многих объектов и связей, не
представляется возможным. Построение сколь-нибудь полной «модели языка» -
неразрешимая задача. Требуется постоянное совершенствование ЛП. В связи с
этим рамках проектов ИПИ РАН развивается
направление, когда программа ЛП отделяется от лингвистических знаний
(ЛЗ). Последние
определяют всю процедуру анализа. Знания ЛЗ имеют вид декларативных
структур, которые легко менять и настраивать. Задача ЛП - поддерживать ЛЗ. При
использовании подобных ЛП облегчается настройка на корпуса текстов, особенности
предметной области. Корректировать ЛЗ может человек, знакомый с элементами
математической лингвистики
и обученный формализму записи ЛЗ. Ему не нужно уметь
программировать. Тогда возникает вариант, когда один человек может настраивать
лингвистический процессор - находить ошибки и устранять их.
1. Проекты
ИПИ РАН, связанные с извлечением знаний
На протяжении последних 20 лет в ИПИ РАН активно
развивается область, связанная с анализом текстов естественного языка (ЕЯ) с
целью извлечения полезной информации, формирования структур знаний и их использования для
решения прикладных задач – поисковых, логико-аналитических. Были разработаны
различные классы таких систем, представляющих научный и практический интерес. Рассмотрим
этапы их построения.
1.1.
Системы естественно-языкового общения
В 90-х годах установка была сделана на
системы фактографического поиска и принятия решений с широкими возможностями
логического вывода. Для них требовались лингвистические процессоры нового типа
- с акцентом на семантическую компоненту, которая отсутствовали в традиционных
блоках лексико-морфологического анализа. В связи с этим были разработаны методики и
средства обучения языку. В систему можно было вводить новые формы и конструкции, обеспечивая
из использование для
формализации текстов ЕЯ с формированием структур знаний. Был создан класс
экспериментальных систем ДИЕС [6,12], LOG [3],
ЭССЕИСТ [4], ИКС[5]. Эти системы
создавались в рамках соответствующих пионерных проектов ИПИ РАН, поддерживаемых
госбюджетом. Для обучения языку был
разработан специальный интерфейс, с помощью которого вводились не только
морфологические признаки, но и семантическая компонента каждого нового слова [12].
Для существительных нужно было указать, к какому классу они относятся. Для
глаголов – модель управления и т.д. Для
ввода новых слов не требовалось каких-либо специальных знаний. В системе ДИЕС
это мог делать практически любой грамотный носитель языка – русского (для ИКС – и английского). Соответствующим образом была организована
интерфейсная компонента. В результате
формировалась база лингвистических знаний слов и словосочетаний (с их семантикой),
которая использовалась для лексико-морфологического и синтактико-семантического
анализа предложений ЕЯ с их отображением на структуры знаний, составляющие базу
предметных знаний (БЗ). Система
осуществляла полный разбор предложений с выделением семантической компоненты.
При этом учитывались случаи полисемии глаголов, восстанавливалась информация,
заданная в неявном виде, и многое другое.
Фактографический поиск и другие приложения
осуществлялись на уровне структур знаний. На уровне таких структур
обеспечивался логический вывод, преобразование представлений. Системы обладали
возможностями «рассуждения» (т.е. порождения из одних фактов других), используя
знания, которые вводились пользователем. Для выдачи результатов разрабатывались
обратные лингвистические процессоры, отображающие структуры знаний на формы ЕЯ.
Для создания подобных систем требовались
специальные языки представления знаний и инструментальные средства их
обработки. Язык – это структурный объект на всех его уровнях, – от поверхностного до семантического. Для обработки конструкций языка были созданы:
язык
расширенных семантических сетей (РСС), обеспечивающий представление
текстов ЕЯ на уровне структур знаний с любой требуемой точностью, и язык
ДЕКЛ для преобразования структур в виде РСС [1,2,13]. Основой языка ДЕКЛ являются правила ЕСЛИ...ТО…, где
левую и правую часть составляют семантические сети – РСС. Фактически РСС – это
типы данных для ДЕКЛ. Эти
инструментальные средства явились необходимой основой для успешного выполнения
проектов.
В тоже время, развитие подобных систем
требовало, во-первых, достаточно
трудоемкой работы по вводу новых слов. Во-вторых, реализация в системе многих
человеческих рассуждений требовали постоянной разработки все новых ДЕКЛ-программ. Более того, требовались значительные
компьютерные ресурсы для того, чтобы поддерживать вновь создаваемые
лингвистические, предметные знания и связанные с ними рассуждения. Сказывалось
несовершенство компьютеров того времени. В связи с этим возможности систем в
плане обработки (формализации) текстов ЕЯ были ограничены. Были и
принципиальные ограничения, влияющие на возможность приложений. Системы не
могли работать с предложениями, где было много незнакомых слов. Для доведения
систем до многих приложений, ориентированных на работу с реальными текстами ЕЯ,
требовалось ввести в них знания практически о всех
словах, которые могут встретиться в соответствующих корпусах текстов. В связи с этим системы
типа ДИЕС нашли применение для
создания языков экспертных систем, содержащих ограниченное количество слов и форм, достаточных для ввода
экспертных знаний.
Отметим еще одно интересное приложение. В
рамках системы ДИЕС была создана система СПРУТ, предназначенная для выявления
организованных преступных групп. Она
основана на иерархии организаций,
работающих в них людей, их признаков и связей, которые вводились в БЗ с
помощью специальной интерфейсной компоненты (по типу Norton Comander), или же из частично формализованного текста. Далее с
помощью программ на языке ДЕКЛ, реализующих модели организованных преступных групп,
осуществлялся поиск связанных групп людей с определенными признаками.
1.2.
Объектно-ориентированные процессоры.
В связи со сказанным в конце 90-х годов в
рамках проектов ИПИ РАН начало развиваться другое направление, при котором не
требовалось отображения семантики всех предложений на структуры знаний в БЗ
[8,9,10]. Учитывался тот факт, что определенные категории пользователей
интересуются конкретной информацией,
которая встречается в текстах ЕЯ. Нужно извлекать из текстов только эту
информацию. Данное направление возникло в связи с прикладными разработками для
ГУВД г. Москвы. Их проблемы заключались в наличии
потоков документов на ЕЯ
(сводок происшествий, справок по уголовным делам, обвинительных заключений и
др.), в которых было много полезной информации. Это фигуранты, их адреса,
телефоны, оружие, автотранспорт и др. Следователей и аналитиков интересовали
именно такого сорта объекты и связи между ними. Использование типовых БД требовало
громадной работы для их заполнения. Использование полнотекстовых БД (типа «Кронус») тоже затрудняло решение многих аналитических
задач.
В связи с этим в ИПИ РАН была инициирована
работа по созданию лингвистических процессоров (ЛП), обеспечивающих
автоматическое выделение их текстов ЕЯ интересующих пользователя объектов и
связей с формированием структур знаний в БЗ. Такие ЛП были названы объектно-ориентированными
(в некоторых работах – семантико-ориентированными). Для успешного создания подобных ЛП у
разработчиков уже имелась достаточная база: опыт построения сложных систем
обработки текстов, о которых было сказано выше, и отлаженный набор необходимых
инструментальных средств – РСС и ДЕКЛ. Для решения прикладных задач
использовался большой опыт построения программных средств для
обработки информации в БЗ. В результате
была создана система «Криминал», обеспечивающая автоматическое извлечение
структур знаний из текстов ЕЯ и их
использование для решения логико-аналитических задач - для следователей и аналитиков. В данной
системе не требовалось вводить морфологические и другие характеристики слов.
Для этого был создан блок лексико-морфологического анализа
(ЛМА), который анализирует текст и строит семантическую сеть (РСС), названной пространственной
структурой предложения (ПС-предложения). Последняя обрабатывается блоком синтактико-семантического анализа
(ССА), который формирует на РСС семантическую структуру (СС-предложения),
представляющую объекты и связи между ними. Такие структуры образуют БЗ.
Предложение ЕЯ после выделения признаков
слов, вариантов их разбора с учетом последовательности слов представляет собой
достаточно сложную структуру, которая плохо укладывается в типовые данные
существующих языков программирования. В связи с этим перспективным оказалось
использование языка РСС для представления таких структур и языка ДЕКЛ для
обработки. Блок ССА состоит из правил анализа и идентификации, образующих
лингвистические знания, которые поддерживаются программами на языке ДЕКЛ.
Отметим, что блок ЛМА написан на языке Си++, при
использовании которого на определенных этапах формализации текстов возникают
существенные трудности. В тоже время, чем больше функций берет на себя блок
ЛМА, тем в большей степени снимает трудности дальнейшего процесса формализации,
который осуществляется блоком ССА [13,14,20].
В последующих проектах ИПИ РАН (АНАЛИТИК,
ПОТОК и др.) объектно-ориентированный ЛП использовался в различных предметных
областях, где требовалось выделение своих объектов и связей - в соответствии с
интересами пользователя. ЛП
использовался для формализации различных корпусов текстов, которые имели
существенные отличия в плане использования выразительных средств и
конструкций. В связи с этим блоки ЛМА и
ССА постоянно совершенствовались [8-13]. В блок ЛМА постоянно вводились новые операторы и средства
настройки, которые достаточно хорошо описаны в работе [17].
Блок ССА совершенствовался в направлении
дифференциации правил анализа и идентификации, введения средств настройки для
выявления случаев некорректного анализа и их быстрого устранения. В данной
статье обобщается опыт разработчиков по построению объектно-ориентированных ЛП.
Статья посвящена описанию особенностей блока ССА и процесса его настройки на
предметную область – соответствующие корпуса тексов. Для иллюстрации будут
рассматриваться примеры из предметной области, связанной с описанием
памятников.
2.
Особенности объектно-ориентированных ЛП.
Объектно-ориентированные
лингвистически процессоры (ЛП) ориентируются на пользователей, которые имеют
постоянный интерес с определенного сорта вещам - объектам. Как уже говорилось, следователям
важны фигуранты, их места жительства, телефоны и др. Специалистов по кадрам
интересуют организации, где человек работал, кем и когда это было. Других
интересуют памятные места, их местонахождение, кто автор, архитектор и т.д.
Подобную информацию будем называть информационными объектами, которые
различаются по типам. Например, лица и фигуранты – это объекты одного типа,
адреса – другого и т.д.. Задача ЛП -
автоматическая обработка потоков текстов (документов) на
ЕЯ с выявлением информационных объектов и связей из
текстов ЕЯ и формированием результатов в соответствии с требованиями
пользователя. Имеет место ориентация на определенную категорию пользователей с
широкими возможностями настройки, что определяется лингвистическими знаниями
(ЛЗ) .
Отметим,
что связи между объектами могут иметь высокую степень разнообразия. Например,
памятники могут быть связаны не только с местом или лицами, которым они
посвящены, но и с действиями или событиями - инициированием работ,
проектированием, архитектурными работами, изготовлением отдельных компонент
(постамента, фигур,...) и многое другое. Такие события
привязаны к времени, месту, связаны с лицами, участвующие в создании
памятников. Одни события могут быть составной частью других. Они могут быть
связаны причино-следственными и временными
отношениями. Будем считать, что события - это тоже информационные объекты,
связанные между собой и с другими информационными объектами. В
ЕЯ такие связи выражаются с помощью глагольных форм,
форм с отглагольными существительными, различными оборотами. Возникают сложные
структуры. Для их представления и был разработан аппарат РСС, а для обработки
– язык ДЕКЛ.
Объектно-ориентированный
ЛП состоит из следующих блоков.
2.1.
Блок лексико-морфологического анализа (ЛМА), выделяет из
документа слова и предложения и выдает в виде семантической сети (ПС-документа), представляющей последовательность компонент
(слов в нормальной форме, чисел, знаков) и их основные признаки. Блок ЛМА имеет три основных подсистемы:
- Лексический
анализатор, который ответственен за правильное деление входного текстового
потока на абзацы, предложения и слова (формирует лексические признаки слов);
- Морфологический
анализатор, осуществляющий морфологический анализ всех слов текста
(приводит слова в нормальную форму и формирует для них морфологические
признаки);
- Систему
предметных словарей, призванную распознать в тексте характерные термины (словарь
стран, регионов России, городов имен собственных, профессий, организаций и др.)
для придания словам и словосочетаниям дополнительных семантических признаков [13,17].
Блок ЛМА имеет свои лингвистические
знания (ЛЗ) – средства параметрической настройки,
позволяющие учитывать разнообразие текстовой типологии [17].
2.2.
Блок синтактико-семантического анализа (ССА) путем анализа ПС-документа выделяет объекты и связи. На их основе строит
другую семантическую сеть, представляющую семантическую структуру документа
(СС-документа), называемую также содержательным портретом [7,9,13]. Этот блок включает в себя базу лингвистических знаний
(ЛЗ), которая содержит правила анализа текста во внутреннем представлении
(РСС). Они определяют работу ЛП [11,14,15].
Блок ССА управляется ЛЗ, за счёт которых обеспечивается:
- извлечение информационных объектов (лиц,
организаций, событий, их места);
- выявление связей объектов, например, связей
лиц с организациями, адресами и др.;
- анализ глагольных форм, причастных и
деепричастных оборотов с выявлением фактов участия объектов в тех или иных
действиях;
- идентификация объектов с учетом
анафорических ссылок и сокращенных наименований;
- выявление связей действий с их местом или
временем (где и когда имело данное действие или событие).
2.3. Блок построения каталогов объектов. Выделяет из СС-документов объекты определенного типа, которые
упорядочиваются по алфавиту и образуют каталог. Например, таким способом
создаются каталоги лиц (их ФИО), дат, адресов и др. - только тех, которые
встретились в документах.
2.4. База
лингвистических знаний (ЛЗ). Содержит правила анализа текста во внутреннем
представлении (РСС). Они определяют работу ЛП.
3. Предметные области и тексты
В
настоящее время имеется большой опыт использования объектно-ориентированных ЛП
в различных предметных областях, где требуется выделение различных объектов из
корпусов текстов, обладающих своими особенностями. В данном разделе мы постараемся обобщить эти
особенности и связанные с ними трудности, которые требовали постоянного
совершенствования блока ССА. С какими
предметными областями и текстами мы имели дело:
3.1. Документы криминальной милиции (на русском языке). Работа делалась
по заказу ГУВД г. Москвы [9]. Была
создана система «Криминал», в БЗ которой были введены: сводки происшествий
по (более 500 тыс. происшествий),
справки по уголовным делам (несколько сотен), обвинительные заключения (около
сотни), записные книжки фигурантов (около сотни). Система обеспечивает
выделение фигурантов, их примет, связей, организаций, дат, документов, номеров
счетов, оружия (всего до 40 типов объектов) с указанием характера их участия в
криминальных действиях .
3.2. Резюме (для приема на работу) на
русском и английском языках. Работа инициировалась риэлторской
компанией и имела целью автоматическую обработку архивов произвольно написанных резюме и их
представление в формате сайта данной компании [16]. Была создана система, выделяющая из резюме атрибуты человека, места его
работы, учебы, соответствующие периоды времени, знание языков и т.д. Система отлаживалась
в несколько этапов. Вначале на выборках в различных областях (информационные
технологии, банковское дело, финансы, юриспруденция и др.) по 200 резюме. Далее отладка шла на специально подобранных
«критичных» резюме (которые при обработке давали шумы по тем или иным типам
объектов), из которых составлялись
специальные выборки. Система работала на сайте компании, чтобы автоматически
переводить резюме пользователей, поступающих через Интернет, в формат сайта.
3.3. Документы о терроризме на русском и
английском языках. Работа носила инициативный характер с целью внедрения в
крупный проект. Система дополнительно
выделяла руководящих лиц, правительственные организации, террористов (как
свойство фигурантов), террористические
организации, орудия преступления, время и место событий и т.д., а также связи и
участие лиц в тех или иных действиях. На первом этапе (для русского языка) она
отлаживалась на массиве в 300 документов, относящихся к террористической
деятельности. В дальнейшем отладка шла
на материалах СМИ, в том числе, взятых из Интернет
[18]. Была также разработана ДЕМО-версия для
обработки документов на английском языке, которая отлаживалась на документах,
взятых из Интернет.
3.4. Документы о памятниках культуры (на русском
языке). Работа носила инициативный характер - делалась для Министерства
культуры. Система выделяет из текстов тип памятника (скульптура, монумент), кто
является автором, создателем, время, место и многое другое.
Во всех случаях (за счет средств настройки
блоков ЛМА и ССА) удавалось добиться требуемого качества работы ЛП [8,10,13].
Отметим высокое разнообразие перечисленных
предметных областей, которое определяется различием выделяемых объектов и
связей, разнообразием используемых изобразительных средств, а также «стилем»
текстовых сообщений. В понятие «стиль» мы включаем весь комплекс
особенностей, присущих определенной группе текстов. Сюда входят лексика
предметной области (включая всю совокупность специфических терминов предметной
области), тип текста (коммуникативный или структурный), способ грамматического оформления текста, а также
следование стандартным правилам
орфографии языка. Настройка на «стиль» осуществляется в рамках блока МЛА и
достаточно хорошо описана в работе [17]. В данной работе акцент будет сделан на
особенности средств и процесса настройки на предметную область блока ССА.
4.
Проблемы настройки на предметную область
При
настройке блока ССА на предметную область возникают следующие трудности.
Во-первых, при наличии разнотипных объектов требуются соответствующие правила
их выделения. Качество ЛП определяется трудоемкостью построения таких правил. В
процессоре объектно-ориентированных ЛП выделение всех объектов (их может быть
более 40 типов) и событий осуществляются правилами, которые конструктивно
оформлены одинаковым образом, и соответственно,
которые работают по однотипным методикам. Поэтому трудоемкость
построения не высокая. Важно, что изменяются только ЛЗ, но не программы.
Во-вторых,
при настройке возникают частые случаи коллизии правил выделения. Одни
правила могут захватывать слова, которые относятся к другим объектам и которые
должны обрабатываться другими правилами. В связи с этим правила должны иметь
средства их быстрой подстройки, ограничивающие возможность применения. В ЛП
такая подстройка осуществляется за счет изменения списков, задающих допустимые
признаки слов, стоящих на тех или иных позициях. В общем случае такие списки
организованы в виде И-ИЛИ графов.
В-третьих,
важный фактор - это избирательность правил и процедур идентификации: коэффициент
шумов и потерь. Под шумами понимается наличие лишних
слов в объектах. Потери - это когда объект не выявлен или выявлен частично (в
тексте есть слова, которые не вошли в объект).
В объектно-ориентированном ЛП правила (составляющие
ЛЗ) имеют все средства для повышения степени их избирательности правил для
минимизации шумов и потерь при большом количестве выделяемых объектов. С
помощью ЛЗ обеспечивается настройка на особенности языка - на типовые
конструкции и формы языка с учетом признаков, которые даются словам. Имеются
все необходимые удобства в плане создания и корректировки правил.
В-четвертых, определенные трудности вызывает
выделение связей. Это не только глубинный анализ глагольных и других форм.
Многие связи даются с помощью анафорических ссылок, другие - в неявном виде.
Требуется организация сложного процесса их поиска, восстановления. Такие
процессы организуются, чтобы связать лицо с его местом проживания или местом
работы, идентифицировать слова (ПАМЯТНИК, ФИГУРА,..) с
объектами (типа памятник) и т.д. Эти слова и подразумеваемые объекты
могут стоять в тексте на значительном расстоянии. Важно не захватить
посторонний объект. В процессоре Semantix для этой цели используются
специальные фильтры.
В-пятых,
для настройки ЛП на корпуса текстов необходим специальный комплекс инструментальных средств, обеспечивающих следующие
функции:
-
последовательную обработку множества документов (корпуса текстов) с
формализацией каждого из них, формированием СС-документов
и построением общей БЗ;
-
формирование списков выделенных объектов (для каждого типа объектов свой
список), осуществляемое в процессе обработки множества документов; такие списки
будем называть каталогами;
-
возможность выделения в каталоге любого объекта с быстрым поиском документов,
из которых выделен данный объект;
-
подача на вход ЛП найденного документа с анализом процесса его формализации
(формирования СС-документа);
-
визуализацию процесса применения правил и осуществляемых ими преобразований;
-
трассировку работы каждого правила с указанием, в какой последовательности
захватываются слова (благодаря каким признакам), а также, почему и на каком
слове процесс применения правила закончился;
-
выдачу в одно окно СС-документа и сам документ для их сравнения;
-
обращение к ЛЗ с выбором любого правила и его изменением.
Эти
средства позволяют быстро находить ошибки в работе ЛП и корректировать ЛЗ.
Методика достаточно проста. Берется корпус текстов и включается в
последовательную обработку с формированием общей БЗ и каталогов объектов. Они
просматриваются. С их помощью легко находить объекты с шумами (лишними словами).
Во многих случаях сразу видны потери - если по смыслу объект не
соответствует своему статусу. Труднее находить потери, когда объект имеется в
документах, но не найден. Тогда нужно просматривать каталог "лишних"
слов и их комбинаций (которые не вошли ни в какие объекты). Или же
просматривать СС-документов и сравнивать их с самими
документами. Конечно, идеальный вариант, когда кто-то (лингвист) выделяет из
корпуса текстов объекты определенного типа, и они сравниваются с построенным
каталогом. Но этот вариант крайне трудоемок, когда имеют место корпуса текстов большого объема, которые
постоянно обновляются.
Следует
отметить, что подобные инструментальные средства имеются в системах
"Аналитик" ("Криминал"), где реализованы различные виды
объектных поисков, ответ на запросы в свободной форме, развита интерфейсная
компонента. Поэтому процесс разработки и отладки ЛЗ для новой предметной
области осуществляется в рамках этих систем.
5. Выделяемые объекты и связи
Набор выделяемых объектов и связей
определяется задачами пользователя. В рамках выполнения плановых работ была
взята предметная область «Памятники», связанная с описанием монументов, памятников.
Работа в этой области явилась еще одним примером достаточной универсальности объектно-ориентированного ЛП. Корпус текста имеет вид:
1.
Памятник руководителю первой русской кругосветной экспедиции Ивану Фёдоровичу
Крузенштерну находится на набережной Лейтенанта Шмидта. Решение об его
установке было принято в 1869 году, в канун столетия со дня рождения адмирала.
Памятник находится напротив здания Морского кадетского корпуса. Торжественная
закладка памятника состоялась 8 ноября 1870 года, в день 100-летнего юбилея
Крузенштерна. Фигура из бронзы была отлита в декабре 1872 года по модели
И.Н Шредера. Гранитный постамент
спроектировал архитектор И.А. Монигетти. Открытие памятника состоялось 6 ноября
1873 года.
2. 23
мая 1909 года в центре Знаменской площади был открыт конный памятник
Александру III. Автор памятника Паоло
Трубецкой выполнил его откровенно как карикатуру, что вызвало довольно сильный
скандал. В 1937 году памятник перенесли во
двор Михайловского дворца. Перенос
памятника объяснили тем, что он якобы мешал
трамвайному движению, хотя к тому
времени трамвай по Невскому проспекту ходил уже
около трёх десятилетий.
3. Памятник Екатерине II создан в 1862-1873 годах по проекту ...
.............
В качестве основных типов информационных
объектов и связей были выбраны следующие:
- памятники (монументы, скульптуры и т.д.);
- лица (кому посвящен памятник, кто
участвовал в его создании и др.);
- ролевые функции или профессии (скульптор,
архитектор, дизайнер, зодчий, ...) ;
- места расположения памятников;
- события с указанием участия в них
информационных объектов ("памятник
создан ...", "работа
выполнена ...");
- даты, время, интервалы времени;
- организации (связанные с созданием
памятников);
- связи между различными типами
информационных объектов (время и место событий, ролевые функции лиц и др.)
6. Пространственные
структуры
Текст ЕЯ – это
сложный структурный объект, который в процессе его формализации проходит
множество уровней преобразования. На первом уровне работает блок ЛМА, который
формирует РСС, называемую пространственной структурой текста (ПС-текста).
Далее следуют преобразования, осуществляемые блоком ССА, которые приводят к
формированию семантической структуры
(СС-текста) для БЗ.
Рассмотрим
особенности ПС-текста. Информация об абзацах и
предложениях представляется в виде фрагмента SENT, имеющего вид:
SENT(1-,A,B,C,1+/2+)
1-(D)
где:
A – позиция первого слова предложения
относительно начала входного потока;
B – 0,1
или 2 – признак начала абзаца (нет абзаца, абзац без разделительной строки,
абзац с одной и более разделительными строками);
C – номер первого слова предложения относительно
начала входного потока;
D – номер строки входного потока, на которой
расположено первое слово предложения.
Для каждого слова
(и для каждого варианта его разбора) блок выдает фрагменты РСС следующего вида:
LR(1-,W,M,No,1+/2+),
где W
– нормализованное слово,
M – признаки слова,
закодированные в виде отдельной записи,
No – порядковый номер слова.
Символы 1+, 1-,
2+.2- на языке РСС – это внутрисистемные
константы, которые связывают фрагменты, и соответственно, представляют связь
слов и их признаков.
Далее следуют
признаки, выделенные из записи M и представленные в виде
отдельных фрагментов:
2-(NAME0) – слово
начинается с прописной буквы;
2-(HEAD_) – слово
полностью состоит из прописных букв;
2-(NAME1) – И. или О. – т.е. сокращение имени или
отчества (прописная буква, за которой идет точка);
2-(POINT) –
сокращение;
2-(HEAD_1) –
слово из букв, среди которых более одной прописной;
2-(NUM) – целое
число;
2-(NUM_F) – число
с дробной частью;
2-(ENGL) – слово
из букв латинского алфавита;
2-(WEB_C) – URL (адрес
Интернет);
2-(MAIL_E) –
адрес электронной почты;
2-(FIRST_) –
признак первого слова на новой строке;
2-(LETT) –
слово состоит из одной буквы.
Фрагменты типа LR и SENT вместе
с выделенными признаками - это семантическая сеть (РСС), которая в дальнейшем
проходит множество уровней преобразования, осуществляемое блоком ССА.
В общем случае блок ЛМА выдает несколько
вариантов разбора. Эта ситуация является весьма типичной. Например, слово «стекло» является и существительным и глаголом. Чтобы зафиксировать множественность вариантов
морфологического разбора, во входном потоке генерируется фрагмент LR для первого варианта разбора и фрагменты LD для прочих вариантов. Например, для слова «что» выдается следующий набор РСС-фрагментов:
LR(1-,'ЧТО','M4?ив',1869,1+/2+) 2-('ЧТО')
2-(PRON)
LD(1-,'ЧТО','R',1869,1-/2+) 2-('ЧТО')
2-(ADV)
LD(1-,'ЧТО','Ss',1869,1-/2+)
2-('ЧТО') 2-(CONJ)
Каждый из фрагментов LR и LD – пятиместные. Первая и пятая позиции служат для связи данных
фрагментов со всей остальной семантической сетью. А позиция после «/» служит
для связи слова с его признаками. Четвертая позиция – номер слова в тексте. Во
второй позиции записана каноническая форма слова. В третьей позиции записаны
морфологические признаки, причем каждый из них закодирован одним символом. В
нашем случае первый вариант разбора определяет «что» как вопросительное местоимение в именительном или винительном
падеже. Второй вариант разбора рассматривает «что» как наречие. Наконец, третий вариант разбора представляет это слово
как союз.
Отсев вариантов осуществляется блоком ССА в
процессе обработки ПС-текста и построения
семантической структуры. Отметим, что в ПС-текста
представлены все признаки слов, необходимые для последующего анализа и
выделения объектов.
Рассмотрим в качестве примера фрагмент ПС-текста, построенного на основе первых слов из
упомянутого корпуса.
DOC('text.txt',1+)
SENT(1-,0,0,1,1+/2+)
1-(0)
LR(1-,'ПАМЯТНИК','NмXФви7',0,1+/2+)
2-('ПАМЯТНИК') 2-(NOUN) 2-(NAME0)
2-("Памятник
",WORD) 2-(FIRST_)
LR(1-,'РУКОВОДИТЕЛЬ','NмIФд',9,1+/2+) 2-('РУКОВОДИТЕЛЬ') 2-(WORK_K)
2-(NOUN)
2-(КОМУ) 2-("руководителю ",WORD)
LR(1-,'ПЕРВЫЙ','Aрдтпж.',22,1+/2+) 2-('ПЕРВЫЙ') 2-(ADJ) 2-(КОГО) 2-(КЕМ)
2-(КОМУ)
2-("первой
",WORD)
LR(1-,'РУССКАЯ','AГрдтпж.',29,1+/2+) 2-('РУССКАЯ') 2-(ADJ) 2-(КОГО) 2-(КЕМ)
2-(КОМУ)
2-("русской ",WORD)
LR(1-,'КРУГОСВЕТНЫЙ','Aрдтпж.',37,1+/2+) 2-('КРУГОСВЕТНЫЙ') 2-(ADJ) 2-(КОГО)
2-(КЕМ)
2-(КОМУ) 2-("кругосветной ",WORD)
.
. .
Каждый фрагмент
типа LR соответствует определенному слову, для которого дается его нормальная
форма, а также признаки и исходное слово. Например, для слова руководителю нормальная форма –
РУКОВОДИТЕЛЬ, а признаки – WORK_K, NOUN, КОМУ. Знаки 2+ и 2- служат для указания связи или принадлежности.
Для уникальных памятников, которые воспринимаются
как обычные словосочетания, создан предметный словарь MONUM_K.SLV, фрагмент
которого имеет вид:
.
. .
Вандомская колонна
Воин-освободитель
Демидовский столп
<Медный Всадник>
Миноносец "Стерегущий"
Родина-мать
Собор Парижской богоматери
Соловецкий камень
.
. .
Если в тексте встретилось одно из этих
слов (или словосочетаний), то ему в ПС-текста
присваивается признак MONUM_K,
который в дальнейшем учитывается правилами из ЛЗ.
7.
Правила выделения объектов
Блок ССА состоит из правил, которые
осуществляют преобразование ПС-документов (имеются в
виду текстовые документы) в СС-документов.
Правила устроены таким образом, что в их рамках могут быть реализованы
различного рода грамматики [10]. В тоже время они ориентированы на более
сложные преобразования, связанные с выделением объектов, и имеют средства,
выходящие за рамки традиционных грамматик. Построение правил требует
определенных навыков. Если правило построено и показало свою работоспособность
в определенной предметной области, то оно (с некоторыми модификациями) может
быть перенесено в другую предметную область.
Так
для области «Памятники» правила, осуществляющие выделение лиц, дат, интервалов
времени, мест и адресов, профессий, организаций, событий и связей, были взяты
из предметных областей, на которые уже был настроен ЛП. Они отлаживались на текстах - "Докyменты о терроризме", "Автобиографии",
"Сводки происшествий" и др.
В каждой
области могут быть свои объекты. Так, в обсуждаемой области новые
информационные объекты - это памятники В связи с этим
потребовалась разработка новых правил - выделения памятников (их несколько).
Далее возникла потребность доработки правил выделения мест
расположения памятников, так как ранее не встречались описания типа: возле Каменного моста, напротив здания Моссовета, на площади перед
Михайловским замком и др. Например, в сводках происшествий таких описаний
нет - всегда фигурирует точное название мест, адресов.
Рассмотрим в качестве примера одно из
правил выделения памятников. Каждое правило имеет левую часть (условие
применения) и правую (действия). Правило выделения монументов выглядит следующим образом:
MUSTBE(MONUM~2,1)
STR_OR(БЮСТ,СТАТУЯ,ФИГУРА,СОБОР,ЦЕРКОВЬ,ХРАМ/1+)
STR_OR(WORK_K,NAT_K,ИМПЕРАТОР,ЦЕСАРЕВИЧ,ГРАФ,КНЯЗЬ,ГЕРЦОГ,../2+)
STR_OR(КОГО,КВЧ,MONUM_K,FIO,FAM/3+)
CONTEXT(1-,2-,3-/MONUM~2)
P_P(MONUM~2,MON~2R)
MONUM_(1,2,3/MON~2R)
MON~2L(MONUM,ADD_)
MAYBE(MONUM~2,2)
Данное правило записано в формализме РСС и
означает следующее. Вызов правила - по его идентификатору MONUM~1. Фрагмент
P_P(MONUM~2,MON~2R)
разделяет левую и правую части, т.е. CONTEXT(1-,2-,3-/MONUM~2), который задает
условие применения, и MONUM_(1,2,3/MON~2R) - что формировать.
Применять правило нужно с 1-й позиции -
MUSTBE(MONUM~2,1). Нужно искать ключевые слова, отмеченные 1+ , т.е. БЮСТ, СТАТУЯ,... На
следующей позиции должно быть одно из слов списка 2+. Это может быть слово с
признаком WORK_K (т.е. входить в
словарь професссий) или с признаком NAT_K
(словарь национальностей), или же одно из перечисленных далее слов.
Фрагмент MAYBE(MONUM~2,2) указывает, что эта позиция
факультативная - перечисленных слов может не быть в тексте.
На следующей позиции должно быть одно из
слов списка 3+. Это может быть слово с признаком КОГО (род. падеж),
или слово в кавычках, или фамилия, или
лицо (ФИО), или слово с признаком MONUM_K
(означает, что слово входит в предметный словарь памятников). Если условие
выполняется, то правило будет применимым. Формируется объект MONUM_(1,2,3) с
признаком MONUM. Аргументами являются
слова (или объекты), которые оказались на позициях 1,2,3. Сформированный объект
замещает эти слова и занимает свою позицию: три позиции замещаются на одну. Правило будет применяться, когда в тексте
встречаются описания типа статуя
императора Николая I, Фигура Петра Великого и
т.д.
В результате применения правил формируется
СС-документа (содержательный портрет), где все слова приведены в нормальную
форму, а объекты и связи представлены в виде фрагментов РСС. Например, для 1-го
документа (из корпуса текстов) он будет иметь вид;
ДОК_(1,MONUM.TXT,"ПАМЯТНИКИ;")
FIO(КРУЗЕНШТЕРН,ИВАН,ФЕДОРОВИЧ,"
"/1+)
DESC_(1-,"Ивану Федоровичу Крузенштерну
")
РАБ_(1-,РУКОВОДИТЕЛЬ,ПЕРВЫЙ,РУССКАЯ,КРУГОСВЕТНЫЙ,ЭКСПЕДИЦИЯ/2+)
DESC_(2-,"руководителю
первой русской кругосветной экспедиции Ивану
Федоровичу
Крузенштерну ")
MONUMENT_(ПАМЯТНИК,2-/3+)
DESC_(3-,"Памятник
руководителю первой русской кругосветной экспедиции
Ивану
Федоровичу Крузенштерну ")
НАХОДИТЬСЯ(3-/4+) 4-(0,ACT_)
DESC_(4-,"Памятник
руководителю первой русской кругосветной экспедиции
Ивану Федоровичу
Крузенштерну находится ")
АДР_(НАБ.,ЛЕЙТЕНАНТ,ШМИДТ/5+) 5-(0,АДР_)
DESC_(5-,"на набережной Лейтенанта Шмидта ")
Где(4-,5-)
.
. .
Первый фрагмент говорит, что документ взят
из файла MONUM.TXT и имеет номер 1. Последующие фрагменты представляют "Памятник руководителю первой русской
кругосветной экспедиции Ивану Фёдоровичу
Крузенштерну", "он находится на набережной Лейтенанта
Шмидта" и т.д. Коды 1+ и 1- (2+ и 2- и т.д.) обозначают один и тот же
объект - лицо FIO (соответственно,
профессию – РАБ_). Во фрагментах типа DESC_ записывается та часть
текста, на основе которого был построен соответствующий объект.
Более подробное описание того, как устроена СС-документа, см. в [8-11]. СС-документов
являются исходным материалом для
автоматического порождения различных сведений – кто автор, архитектор, когда
памятник установлен, открыт и т.д. На этой основе строятся аннотации, краткие
описания, заполняются табличные формы или поля сайтов. Это делается с помощью
экспертных программ на языке ДЕКЛ, который создан для обработки структур знаний
на РСС [2,12].
8. Каталоги объектов
Как уже говорилось, отладка правил и ЛЗ
ведется в рамках систем "Аналитик" ("Криминал"). Они
обеспечивают последовательную обработку множества документов (корпуса текстов
из заданного файла) с формализацией каждого из них, формированием СС-документа
и построением общей БЗ и каталогов объектов. Такие каталоги - это описания
объектов (фрагменты DESC_),
взятые из СС-докумнтов, преобразованные в нормальную
форму (т.е. в именительном падеже) и отсортированные по типам и по
алфавиту. Например, каталог выделенных
памятников (когда обработано 30 документов) имеет вид:
Александровская колонна
Бронзовый бюст
Вандомская колонна
Гранитный постамент
Екатерининский дворец
Михайловский дворца
Памятник - бюст М. П. Мусоргскому
Памятник - бюст Н. А. Некрасову
Памятник - бюст Н. М.
Пржевальскому
Памятник - бюст П. П. Семенову - Тян - Шанскому
Памятник - бюст знаменитому
архитектору XVIII в. Франческо Бартоломе
Памятник Екатерине II
Памятник Николаю I
Памятник Петру I ( Медный
всадник )
Памятник руководителю первой русской
кругосветной экспедиции Ивану Ф
Памятник цесаревичу Алексею
Николаевичу
Памятник, названный < Героям
Краснодона >
Первый памятник императору Петру
I
Петропавловская крепость
СОЛОВЕЦКИЙ КАМЕНЬ, памятник
Скульптура < Зайчика, спасшегося от
наводнения >
.
. .
Каталог выделенных мест:
Александровский парк близ Каменноостровского просп.
Большой Сампсониевский
проспект,
Боткинская улица
Васильевский острове
Веребьинский мост на железной дороге Санкт - Петербург - Москва
Гатчина
Исаакиевская площадь
Ленинград
Летний сад
Марсовое поле
Нева
Невский проспект
Петербург
Россия
Санкт - Петербурге
Сенная площадь
Соловецкий остров
Финляндский вокзал
.
. .
Выявление шумов и потерь сводится к просмотру
таких каталогов с поиском неполных или бессмысленных описаний. Выбрав любую
строчку и нажав ENTER, будет найден документ, из которого выделен
соответствующий объект. Этот документ подается на вход ЛП для повторного
анализа.
9. Просмотр процесса применения правил
Когда найден документ, из которого не
правильно выделен объект, нужно найти соответствующее правило и скорректировать
его. Для этого служит режим просмотра
процесса анализа документа, где для каждого правила указывается, какие оно
осуществило преобразования. Процесс визуализации изображен на рис.1.
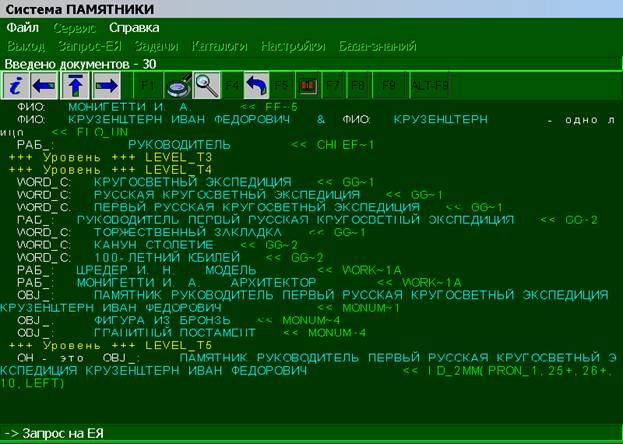
Рис.1
На рис.1 показано следующее. Правило FF~5 применилось и выделило лицо МОНИГЕТТИ И.А.
Следующее правило объединило фамилию КРУЗЕНШТЕРН
с выделенным лицом – КРУЗЕНШТЕРН ИВАН
ФЕДОРОВИЧ. Слово РАБ_ указывает на профессию, а OBJ_ - на памятники. Правила GG~1 и GG~2 выделяют группы
согласованных слов – генетивные цепочки.
Правила MONUM~1,
MONUM~4 выделяют группы слов –
описания памятников. В режиме просмотра легко увидеть, что сделало
каждое правило и где имела место ошибка. Более того, все правила имеют
встроенные механизмы трассировки. Их
можно активизировать для каждого
интересующего правила. Трассировка визуализирует процесс, выводя на экран, в
какой последовательности захватываются слова и почему правило оказалось не
применимым [11,12].
10. Трассировка правил
Если найдено правило, которое является
причиной ошибки, то его работа подвергается дальнейшему анализу. Для этого
разработаны встроенные механизмы (программные средства) трассировки правил.
Каждое правило можно
активизировать, чтобы обеспечить выдачу процесса его применения по
шагам. Трассировка визуализирует процесс, выводя на экран, в какой
последовательности захватываются слова и почему правило оказалось не
применимым.
Для активизации правил разработаны
средства, которые обеспечивают две функции. Во-первых, выдачу всех правил,
находящихся в ЛЗ. Пользователь может выбрать любое из них и отметить его, нажав
клавишу ENTER. За правилом появится
надпись «просмотр». На рис. 2 отмечено правило MONUM~1, выделяющее объекты – памятники. В
общем случае может быть выделено несколько правил.
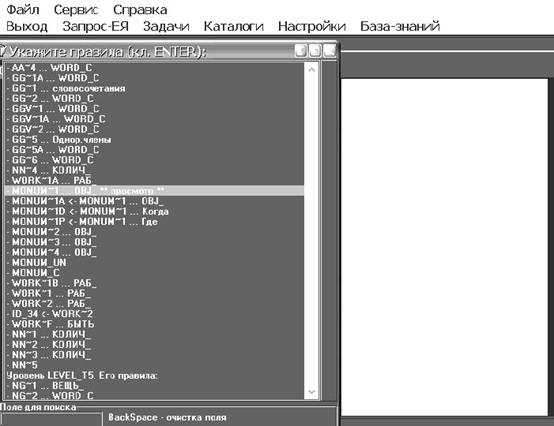
Рис. 2
Отмеченные правила активизируют процесс их трассировки. Для
этого нужно выйти в режим просмотра, иллюстрирующий по шагам разбор документа. В процессе визуализации для
активизированного правила реализована своя выдача – более детализированная. На
рис. 3 проиллюстрирован процесс трассировки правила MONUM~1. Это основное правило, обеспечивающее выделение памятников.
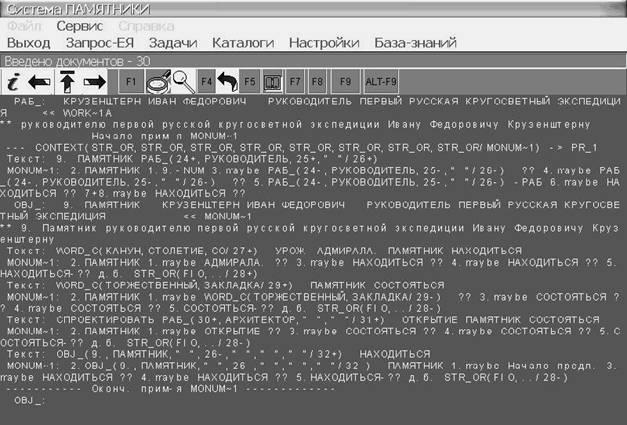
Рис. 3
После метки «Текст:» стоят компоненты
текста (это последовательно стоящие слова, объекты или сформированные фрагменты,
к которым правило пробует примениться. Далее иллюстрируется сам процесс применения. Числа 2…., 1.,
указывают, что применение правила начинается с второй
позиции и затем идет проверка того, что стоит на первой позиции и т.д.
На каждой позиции могут быть отдельные слова, объекты или
промежуточные структуры (фрагменты) со своими признаками. С помощью значка maybe отмечаются факультативные
позиции правила. Знаки «??» означают несоответствие, т.е. проверка по данной
позиции не прошла.
Если позиция факультативная, то факт несоответствия
игнорируется. В других случаях применение правила заканчивается. Ищутся новые
варианты применения. Если правило сформировало объект, то он выдается в
формате:
OBJ_: ПАМЯТНИК …. << MONUM~1,
где OBJ_ указывает, что выделен объект – памятник. Далее следуют слова
в нормальной форме, составляющие данный объект. На следующую строчку ставятся
компоненты текста, на основе которых был сформирован объект.
Подобная трассировка позволяет понять, почему не сработало то
или иное правило, какие признаки должны быть у слов (или фрагментов)
анализируемого текста, чтобы правило
к ним применилось.
Это является основанием
для корректировки правила.
Заключение
В настоящее время объектно-ориентированный
лингвистический процессор настроен на автоматическую обработку потоков текстов
на естественном языке (ЕЯ), представляющих собой: резюме на русском и
английском языке, сообщения СМИ (о терактах), тексты описания
достопримечательностей (памятников), сводки происшествий, справки по уголовным
делам. Процессор может быть использован для обработки архивных и
информационно-рекламных материалов, почтовых сообщений и т.д. Достоинства этого
процессора - высокая избирательность при выделении объектов и связей, наличие
правил глубинного анализа с выделением событий и их привязкой к времени и
месту, а также наличие средств быстрой настройки на новую предметную область.
Как показывает опыт, время такой настройки исчисляется не годами, а неделями,
месяцами: зависит от количества и сложности новых объектов и допустимыми
коэффициентами шумов-потерь.
Список литературы
1. Кузнецов И.П. Семантические
представления// М.: Наука. 1986г. 290 с.
2. Кузнецов
И.П., Шарнин М.М. Продукционный язык программирования ДЕКЛ. Сб. Система
обработки декларативных структур знаний Деклар-2// ИПИ РАН, 1988.
3. Любушкина
Л.А., Михеев А.С., Соловьева Н.С., Сомин Н.В., Фрейдлин И.Я. LOG - программа, ведущая диалог на
естественном языке.// Вторая всесоюзная конференция по ИИ "ВКИИ-90".
Минск: Центрпрограммсистем, 1990.
4. Карунин А.Б., Соловьева Н.С., Сомин Н.В. ЭССЕИСТ -
программа, ведущая диалог с базой знаний
на естественном языке. // В кн.:
Социальная информатика-93 / Сб. научн.
трудов под ред. Колина К.К. и Суслакова Б.А. -М.,
1993. -С. 168-174
5. Кузнецов
И.П., Шарнин М.М. Интеллектуальный редактор знаний на основе расширенных
семантических сетей// Сб. Системы и
средства информатики. Вып.5. М. Наука, 1993.
6. Кузнецов
И.П. Гипертекстовые технологии на семантической основе// Сб. Системы и средства
информатики. Вып.7. М. Наука, 1995.
7. Кузнецов В.П. Автоматическое выявление из
документов значимой информации с помощью шаблонных слов и контекста// Труды
межд. Семинара Диалог 98. Т.2. Казань: ООО «Хетер»
1998.
8.
Кузнецов И.П. Методы обработки сводок с выделением особенностей фигурантов и
происшествий// Труды межд. Семинара Диалог 99. Т.2. Тарусса,
1999.
9. Кузнецов И.П., Особенности обработки
текстов естественного языка на основе технологии баз знаний // Сб. ИПИ РАН,
Вып.13, 2003 г. стр. 241-250.
10. Igor Kuznetsov, Elena Kozerenko.
The system for extracting semantic information from natural language texts//
Proceeding of International Conference on Machine Learning. MLMTA-03, Las Vegas US, 23-26 June 2003, с. 75-80.
11.
Кузнецов И.П., Мацкевич А.Г. Семантико-ориентированный лингвистический
процессор для автоматической формализации автобиографических данных// Труды
международной конференции "Диалог
2006", Бекасово, 2006, стр. 317-322.
12. Кузнецов И.П., Мацкевич А.Г.
Семантико-ориентированные системы на основе баз знаний (монография)// М.:
МТУСИ,
13. Кузнецов И.П. Сомин Н.В. Англо-русская
система извлечения знаний из потоков информации в среде Интернет// Сб. ИПИ РАН,
14. Kuznetsov I.P., Kozerenko
E.B. Linguistic Рrocessor “Semantix” for Knowledge extraction from natural texts in Russia and
English// Proceeding of International Conference on Machine Learning,
ISAT-2008. 14-18 July,
15..Кузнецов И.П., Сомин Н.В. Средства
настройки семантико-ориентированного лингвистического процессора на выделение и
поиск объектов. Сб. ИПИ РАН, Вып.18.
16. Кузнецов И.П. Объектно-ориентированная
система, основанная на знаниях в виде XML- представлений.// Сб. ИПИ РАН, Вып.18.М.: 2008, с.
96-118.
17. Сомин Н. В, Кузнецов И.П., Мацкевич А.Г., Николаев В.Г.. Методы и средства настройки морфо-лексического анализатора на предметную область // Системы и средства информатики. Вып.19. – М.: Наука, 2009, с.97-118.