Семантические методы извлечения имплицитной
информации
Кузнецов Игорь Петрович (igor-kuz@mtu-net.ru)
Институт
проблем информатики РАН, Москва
Одно
из направлений развития семантико-ориентированных лингвистических процессоров,
извлекающих структуры знаний из текстов естественного языка, связано с
выявлением имплицитной информации, которая рассматривается в узком плане - как
выявление новых свойств объектов, заданных в неявном виде. Предлагается
методика такого выявления, основанная на анализе структур знаний. В качестве области
приложения рассматривается задача выявления ролевых функций фигурантов на базе
их описаний в документах криминальной милиции.
Введение
Одной из актуальных задач области информационных
технологий является автоматическое извлечение знаний из текстов естественного
языка (ЕЯ). Методики и средства такого извлечения определяются
особенностями корпусов текстов и классом решаемых задач. Из текстов извлекается
то, что нужно пользователю для решения стоящих перед ним задач. Например, задачи
следователей-аналитиков из области «Криминалистика» заключаются в поиске
фигурантов, их адресов, деяний, связей между фигурантами, поиск по приметам, поиск
похожих фигурантов и происшествий и многое другое. Отсюда следует необходимость
извлечения соответствующей информации из текстов ЕЯ: сводок происшествий,
обвинительных заключений, справок по уголовным делам, записных книжек
фигурантов и др. При этом информация должна быть представлена в форме, удобной
для решения перечисленных ранее задач.
Другой
пример – задачи кадровых агентств, где документами являются резюме людей,
желающих получить работу. В резюме даются анкетные данные, места учебы и работы
с указанием периодов и организаций или учебных заведений и т.д. Задачи кадровых
агентств – поиск лиц по запросам клиентов. При этом следует учитывать, что
часто резюме пишутся в свободной форме – в виде текстов ЕЯ. Такие резюме
требуют формализации для организации необходимых поисков.
На протяжении последних 20 лет в ИПИ РАН
развивается научное направление, связанное с формализацией текстов ЕЯ для
решения задач в различных предметных областях [1-4]. Такая формализация
заключается в извлечении из текстов, так называемых, информационных объектов (лиц, организаций, адресов, дат и др.) и
связей между ними.
Отметим, что
связи между объектами, которые интересуют пользователей, могут иметь высокую
степень разнообразия. Например, интерес может представлять не только связь лиц
с их анкетными данными или объектами, которыми он владеет, но и действия или
события, в которых эти лица участвуют. Такие события привязаны к времени,
месту. Более того, одни события могут
быть составной частью других. Они могут быть связаны причинно-следственными и
временными отношениями. Для ряда задач подобные связи играют важную роль. Их
тоже нужно выявлять и обрабатывать. Поэтому следует считать, что события - это
тоже информационные объекты, связанные между собой и с другими информационными
объектами. Возникают сложные структуры. Для их представления в рамках проектов
ИПИ РАН разработан язык расширенных семантических сетей (РСС), а для обработки
– продукционный язык ДЕКЛ [3].
Проблема
извлечения знаний из текстов ЕЯ рассматривается под углом зрения выявления
информационных объектов и связей с построением структур знаний, на основе
которых осуществляется решение пользовательских задач. Для этого в рамках
проектов ИПИ РАН разработан и постоянно совершенствуется объектно-ориентированный
лингвистический процессор (ЛП), анализирующий тексты ЕЯ и извлекающий
из них структуры знаний – так называемые содержательные портреты документов
(СП-документов) [1-3]. Они образуют Базу
знаний. Для выдачи результатов разработан обратный лингвистический процессор (см.1.5),
формирующий на основе СП-документов тексты ЕЯ, которые выдаются пользователю. В
рамах такой организации пользователь получает информацию в удобной для себя
форме – на ЕЯ.
Процессор ЛП
реализован средствами языка ДЕКЛ и управляется лингвистическими знаниями (ЛЗ)
в виде предметных словарей, средств параметрической настройки, а также правил
выделения объектов и связей. С помощью ЛЗ осуществляется настройка ЛП на
соответствующие категории пользователей и корпуса текстов. В результате
возникает конкретная реализация. Таким образом, речь идет о средствах
построения класса процессоров с широкими возможностями их настройки и
совершенствования.
Дальнейшее
развитие таких процессоров (ЛП) связано с выявлением из текстов ЕЯ так
называемой имплицитной информации. Имеется в виду информация, которая
подразумевается, дается в тексте в скрытом или неявном виде. Изучение видов
имплицитной информации относится к области лингвистики и, как правило, рассматривается
с точки зрения коммуникативного воздействия на адресата, например, в процессе
чтения текста или речевого акта [5-7]. Задача автоматического извлечения
имплицитной информации из текстов ЕЯ сформулирована в рамках проекта «Линво-ИИ»
[13] и рассматривается как дополнение структур знаний новой информацией, которая
восстанавливается путем анализа содержимого текста. В данной статье предлагаются
методики такого извлечения, заключающиеся в использовании ЛП для формирования
структур знаний и использовании средств логико-аналитической обработки
(продукций языка ДЕКЛ) для анализа этих структур и порождения новой информации.
Преимущества и
недостатки предлагаемых методик будут рассмотрены на конкретной задаче из
области «Криминалистика» – выявления ролевых функций лиц (фигурантов) на основе
совершенных ими деяний или за счет участия в определенных событиях.
Отметим, что задача выявления ролевых функций
информационных объектов в общем виде включает в себя всевозможные «оценки», «окраски».
Например, оценка стабильности предприятия (по информации из Интернет), окраска
политических деятелей (положительная или отрицательная в зависимости от
высказываний о них
в прессе), оценка
качества изделия (по высказываниям пользователей) и т.д. Часто напрямую не
говорится – это плохо, а это хорошо. Как правило, в текстах ЕЯ описываются
события, ситуации, в которых участвовал тот или иной информационный объект. По
ним и делается оценка, которая зачастую представляется в виде нового
(порожденного) свойства объекта.
1. Выявление ролевых функций объектов
Семантические методы выявления ролевых
функций объектов (лиц) сводятся к анализу структур знаний (СП-документов) и их
дополнению новыми фрагментами, представляющими эти функции. При этом с помощью
ЛП из текстов ЕЯ извлекаются информационные объекты и связи, а также
конструкции ЕЯ, представляющие действия, которые преобразуются в однотипные
фрагменты <имя действия>(<арг.1>,<арг.2>,…). На базе них
формируются СП-документов. Для
порождения новых фрагментов используются продукции языка ДЕКЛ (правила ЕСЛИ…ТО), с
помощью которых осуществляется анализ СП-документов и логический вывод. Для
управления анализом используются специального вида управляющие фрагменты РСС,
входящие в лингвистические знания (ЛЗ). Вначале рассмотрим традиционные методы
выявления ролевых функций.
1.1.
Синтактико-семантические формы
Задача выявления ролевых функций
информационных объектов в общем виде включает в себя всевозможные «оценки»,
«окраски». Например, оценка стабильности предприятия (по информации из
Интернет), окраска политических деятелей (положительная или отрицательная в
зависимости от высказываний в прессе), оценка качества изделия (по
высказываниям пользователей) и т.д. Часто напрямую не говорится – это плохо, а
это хорошо. Как правило, в текстах ЕЯ описываются события, ситуации, в которых
участвовал тот или иной информационный объект. По ним и делается оценка,
которая зачастую представляется в виде нового (порожденного) свойства
объекта.
Для
решения данной задачи используются различные методы [11,12]. Наиболее
распространенный – метод выявления новых свойств объектов - путем использования
синтактико-семантических
форм. Например:
<кто
– человек> учинил скандал,
<кто – человек>задержан,
<кто – человек> ударил <кого
– человека> … и т.д.
Применение
таких форм к текстам ЕЯ заключается в поиске «оценочных» или
«характеристических» слов типа «скандал»,
«ударить» и др. Как правило, это глаголы. Далее анализируется окрестность
(глагольные формы) , т.е. слова, стоящие слева и справа, их семантические
классы и падежные формы. В результате даются оценки. По данным формам – что (первый)
человек совершил «хулиганские действия»
или что он «подозреваемый». А по третьей форме (дополнительно), что второй
человек «потерпевший». В общем случае при выделении информационных объектов должны
анализироваться не слова, а наборы слов. Например, выделение лица заключается в
поиске слов, составляющих его ФИО с указанием года рождения и др.: «Иванов И.И., 1980 г.р., безработный,…». Аналогично,
«оценка» объектов может включать в себя анализ множества слов.
Применение
форм к текстам ЕЯ требует различных видов анализа – морфологического (чтобы
привести словоформы к одному виду и сформировать для них наборы признаков),
синтаксического (строятся деревья разбора предложений, чтобы выделить связанные
компоненты и найти место для оценочных слов) и семантического (чтобы выделять объекты,
которые оцениваются, и связывать их с действиями).
Использование
синтактико-семантических форм связано с определенными трудностями, вызванными
особенностями ЕЯ: наличием в текстах причастных, деепричастных оборотов,
различных пояснений, факультативных компонент (время, место, цель),
анафорических ссылок и многое другое. В результате информационные объекты часто
оказываются на значительном расстоянии от оценочных слов. Отсюда – значительные
потери, влияющие на качество оценивания.
Пример 1. Текст взят из сводок происшествий ГУВД г. Москвы:
01.02.98г. В 18.15 сотрудниками ОВД АП
Галкиным и Тимаковым по ул.Байкальская
16-1-141 в своей квартире был задержан гр-н Кикин Иван Викторович 1952 г.р,
безработный, который в состоянии алкогольного опьянения на почве неприязненных
отношений нанес ножевое ранение в брюшную полость гр-ну Котову Артему Ивановичу
1973 г.р, прож. Плетешковский пер. 35-12, который от полученного ранения
скончался на месте.
В данном примере подразумевается, что
фигурант («Кикин…») участвует в криминальных действиях – «быть задержанным», «нанес ранение». В тоже время, между
фигурантом и описанием его криминальный действий стоит множество
вспомогательных компонент типа «безработный»,
«в состоянии алкогольного опьянения», «на
почве неприязненных отношений», которые описывают свойства фигуранта и
причину действий. Аналогичное относится и к другому лицу - Котову. Чтобы связать эти лица с их действиями требуется
первоначальное выделение компонент, которые не должны учитываться в формах:
годы рождения, адреса, свойства, время, место и др., что предполагает
достаточно глубокий анализ текста с выделением объектов, их свойств и
атрибутов. Еще одна проблема - идентификация объектов и местоимений. Их согласование
по роду-числу-падежу не всегда определяет такую идентификацию. В приведенном
примере «который» относится к «Кикину»,
а не к «переулку».
Известно,
что в ЕЯ возможно множество вариантов выражения одного и того же – с помощью
различных синтаксических конструкций, глагольных групп, форм и т.д. Для
выявления одной и той же ролевой функции каких-либо объектов может
потребоваться большое количество форм. Для уменьшения их количества, во-первых,
следует эквивалентные формы приводить к одному виду, например, «А1 задержан», «задержанный А1», «сотр. мил. задержал А1» и др. Во-вторых, следует учитывать тот факт, что различные
оценочные слова могут участвовать в одних и тех же формах и служить для
выявления одних и тех же ролевых функций. Такие слова следует объединять в
классы. Например, «задержан»,
«разыскиваться», «осужден»,… Возникает возможность обобщения форм – для
уменьшения их количества.
1.2. Обобщенные
синтактико-семантические формы
Для уменьшения количества форм введем обобщенные
синтактико-семантические формы (или просто обобщенные формы),
которые будем записывать в виде, допускающем их отображение на язык РСС и
использование для анализа структур знаний [13]. Для этого, во-первых, будем
допускать в этих формах классы слов для представления множества вариантов.
Во-вторых, будем использовать в обобщенных формах нормализованные слова. И
в-третьих, не будем записывать в таких формах вспомогательные слова, не
играющие роли при применении форм, например, многие предлоги, малозначимые
слова и др. Это позволит приблизить обобщенные формы к представлениям,
используемым в СП-документов, и соответственно, упростит построение ЛЗ и правил
вывода.
Введем необходимые обозначения для
обобщенных синтактико-семантических форм. Обозначим через лицо1 - объект (человека) со свойством «подозреваемый», через лицо2
- «потерпевший», а через лицо3 - «заявитель».
Обобщенную форму <человек> «учинил
скандал», из которой
следует, что данный человек «подозреваемый», будем записывать в виде
<лицо1> «учинить
скандал»
Это форма с одним лицом. Форма с двумя лицами:
< лицо1> угрожать <
лицо2>
В данных
формах используются нормализованные слова и отсутствуют компоненты, которые не
учитываются: предлоги, союзы, время, место и др.
Как уже говорилось, применение таких форм к
реальным текстам (как шаблонов) – это сложнейший процесс, где нужно учитывать
наличие различных слов и конструкций между оценочными (характеристическими)
словами и объектами. Но этого не требуется, когда форма преобразуется на язык
РСС и (с помощью правил языка ДЕКЛ) применяется к СП-документов, см. п. 4.4.
Часто сам глагол не является достаточно
информативным и соответствующее действие определяется стоящим за ним одним или
несколькими словами. Например «сбить с
ног» или «вырвать из рук», где
глаголы «сбить» или «вырвать» – не информативны. Будем
называть такие наборы слов, объединенные в единое целое и представленные в виде
терминов, глагольными словосочетаниями. Более того, многие действия
определяются объектами, на которые направлено действие, а также их свойствами,
орудиями действия и др. Это компоненты, уточняющие действия. Их тоже будем объединять
в классы и давать в виде перечней или
альтернативных пар. Например, (угроза:
насилие, убийство, слово, оружие, …) означает, что имеет место или «угроза насилием» или «угроза убийством» и т.д.
Будем
объединять в обобщенных формах слова, глагольные словосочетания и
альтернативные пары с одними и теми же ролевыми функциями в отдельные классы.
Их часто называют синонимичными рядами, которые являются основой многих онтологий. В связи с этим будем
называть такие классы онтологическими.
Рассмотрим пример онтологического класса для выявления: «подозреваемый» -
«потерпевший».
Класс_1={ударить, избить, обсчитать, … ,«вырвать из рук», «залезть в карман»,
…,(совершить: кража,
обсчет, побои),(завладеть: деньги, кошелек), …},
<лицо1> Класс_1 <лицо2>
Данная запись означает,
что если в тексте дается описание одного из перечисленных действий, связывающих
два лица, то первому лицу (субъекту действия) присваивается свойство
«подозреваемый», а второму лицу (на которое направлено действие) – свойство
«потерпевший».
Введем в обобщенные
синтактико-семантические формы факультативные
компоненты, которые будем отмечать звездочкой – «*». Например, в
вышестоящей форме «потерпевший» может
отсутствовать, что будет представлено как <лицо2*>.
При таком отсутствии форма будет служить для выявления «подозреваемого».
Рассмотрим еще один пример онтологического
класса для выявления «потерпевшего»:
Класс_4 = {обратиться,
заявить, сообщить, скончаться, (обнаружение: ранение,
ушиб),
(получить: травма, ушиб), …},
<лицо2> Класс_4.
Данная запись означает,
что если в тексте встретилось описание одного из перечисленных действий, то
субъекту действия (лицо2)
присваивается свойство «потерпевший».
Если с помощью имеющихся форм не выявлен
«потерпевший», то с высокой степенью вероятности им является «заявитель».
Более сложные случаи выявления ролевых функций лиц требуют анализа составных действий, т.е. множество
(последовательных) действия лица.
Например, в формах:
Класс_8= {«уйти из дому»,уехать, …}
< лицо2> класс_8* + не вернуться
представлено, что «потерпевший» (лицо2) «ушел из дому и не вернулся».
Отметим, что в онтологические классы могут
быть включены не только действия, но и свойства лиц. Например, для выявления «подозреваемого»
характеристическими словами являются: «неизвестные
(лица)», «двое неизвестных» и т.д.
1.3.
Содержательные портреты документов.
Обобщенные формы
представляют действия, а также их компоненты, которые связывают действия с ролевыми
функциями. Предполагается, что такие действия и их аргументы выделены из
текста. Это делается семантико-ориентированным ЛП, который на основе текста
строит структуры знаний (СП- документа). Рассмотрим, как выглядят такие
структуры в формализме РСС [1.2,3].
Пример
2. Текст взят из сводок происшествий ГУВД г. Москвы:
01.02.98 г. в 16-30 в ОВД обратился гр-н
Митрофанов Виктор Михайлович,
Содержательный портрет
данного текста (СП-документа) имеет вид:
ДОК_(22,“1-02-
ОВД_(ОВД/1+)
FIO(МИТРОФАНОВ,ВИКТОР,МИХАЙЛОВИЧ,1955/2+)
БЕЗРАБОТНЫЙ(2-/3+) 3-(22,PROP_)
АДР_(БОРОВСКИЙ,Ш.,38,211/4+)
ПРОЖ.(2-,4-)
АДР_(УЛ.,ФЕДОСЬИНО,ДОМ,3/5+)
FIO(" ","
"," ",НЕСКОЛЬКО/6+)
НЕИЗВЕСТНЫЙ(6-)
ПЬЯНЫЙ(6-/7+) 7-(2,PROP_)
СКАНДАЛ(6-,ПЬЯНЫЙ/8+) 8-(22,ACT_)
СООБЩИТЬ(2-,8-/9+) 9-(22,ACT_)
ДАТА_(1998,02,~01,"10-00"/10+)
Когда(9-,10-)
ОБРАТИТЬСЯ(1-,2-/11+) 11-(22,ACT_)
ДАТА_(1998,02,~01,"16-30"/12+)
Когда(11-,12-)
ВЫРАЖАТЬСЯ(6-,НЕЦЕНЗУРНЫЙ,БРАНЬ/13+) 13-(22,ACT_)
НАТРАВИТЬ(6-,СОБАКА/14+) 14-(0,ACT_)
ОБРАТИТЬСЯ(2-,В,ТРАВМПУНКТ/14+) 14-(0,ACT_)
ПОСТАВИТЬ(ДИАГНОЗ,УКУС,НОГА/16+)
16-(0,ACT_)
ПРЕДЛ_(22,11-,4-,3-,9-,13-,14-/17+)
17-(2,15,341)
ПРЕДЛ_(22,15-,16-/18+)
18-(6,342,448)
Содержательный портрет
состоит из элементарных фрагментов, аргументами которых являются слова в
нормальной или канонической форме (например, для существительных – в ед. числе,
им. падеже, для прилагательных – дополнительно муж. род и т.д.). Это необходимо
для поиска и обработки.
Каждый элементарный фрагмент имеет свой уникальный код, который
записывается в виде числа с знаком + и отделяется косой линией. Например, в фрагменте
ОВД_(ОВД/1+) знак 1+ есть его код (а 1- - ссылки на него). Например, в
фрагменте ОБРАТИТЬСЯ(1-,2-/11+) знаки 1- и 2- означают, что в ОВД обратилось
лицо, представленное FIO(МИТРОФАНОВ, … /2+).
Фрагменты ДОК_(22,“1-02-98.TXT”,“СВОДКА;”/0+) 0-(RUS) указывают, что содержательный портрет
построен на основе русскоязычного текста документа с номером 22 из файла
1-02-98.TXT”, который обрабатывался
как сводка происшествий (от этого зависят лингвистические знания). Следующие фрагменты представляет отделение
милиции (ОВД_), лицо (ФИО), его свойство (PROP) – безработный, адрес (АДР_) и т.д. Знаки 2+,2-,3+,3-,… - это коды
фрагментов, с помощью которых задаются их связи и отношения. Например, фрагмент
ПРОЖ.(2-,4-) представляет отношение, что лицо (представленное как ФИО с кодом
2+) проживает по адресу (фрагмент АДР_ с кодом 4+). Действия также
представляются в виде фрагментов типа СКАНДАЛ(6-,ПЬЯНЫЙ/8+) 8-(22,ACT_), где представлено, что «лицо (ФИО с кодом 6+), будучи пьяным, учинило скандал». С
помощью кода (8+,8-) указывается, что фрагмент представляет действие (ACT_) и относится к документу
с номером 22. Такие коды также служат
для представления времени, места действия и фактов их комбинирования – когда
одно действие включено в состав другого. Будем называть такие действия
составными. Например, фрагмент
СООБЩИТЬ(2-,8-/9+) представляет, что лицо (код 2+) сообщило о действии
(код 8+), т.е. об «учиненном скандале». Следующие фрагменты ДАТА_(…/10+)
Когда(9-,10-) представляют время (ДАТА_) и что оно относится к действию «сообщить» (код 9+).
Особую роль играют
фрагменты ПРЕДЛ_(...), которые соответствуют предложениям. Они заполняются
словами, не вошедшими в информационные объекты (в данном примере их нет), а
также кодами самих объектов. К этим фрагментам добавляются указатели их
местоположения в тексте. Например, фрагмент
ПРЕДЛ_(22,11-,3-,9-,13-,14-/17+) 17-(2,15,341)
представляет тот факт, что объекты с кодами
11- (соответствует действию «обратиться»),
3- (соответствует свойству «безработный»)
и др. находятся в предложении, которое начинается с 2-ой строки текста
документа и занимают место от 15-го байта до 341-го. Это средства
позиционирования, которые необходимы для работы обратного ЛП.
Анализируя данный пример,
можно сделать следующие выводы:
1) В СП-документа
оценочные (характеристические) слова оказываются или в одном фрагменте с
объектом - СКАНДАЛ(<лицо>,…), или рядом, т.е. коды действий, в которых
участвует объект, соседствуют в ПРЕДЛ_(…9-,13-,14-…). При этом учитывается и
возможность составных действий.
2) По действиям,
представленным как СКАНДАЛ(<лицо>,…), можно сделать вывод, что речь идет
о «подозреваемом», а СООБЩИТЬ
(<отд.мил.>, <лицо>) – что лицом является «потерпевший» или
«заявитель». Такие выводы легко порождаются с помощью правил ЕСЛИ…ТО
(называемых продукциями) языка ДЕКЛ, которые являются основой выявления
ролевых функций.
3) Имеют место
определенные трудности деления текста на предложения. Сокращение «н/р.» (с точкой в конце) не было понято ЛП как конец предложения.
4) Процессор ЛП правильно
идентифицировал местоимение Он, а
также сумел выявить участие субъекта («неизвестные»)
в действиях «выражаться нецензурной
бранью» и «натравить собаку», которые тоже характеризуют субъект. В тоже время
ЛП не удалось связать действие «поставлен
диагноз» с лицом – «Митрофанов …»
(код 2-).
В данном случае пример
оказался удачным. В тоже время процессор ЛП (с его ЛЗ) разрабатывался для задач
криминальной милиции, связанных с различными видами объектных поисков: поиск
похожих фигурантов (адресов и т.д.), поиск по связям, точный поиск объектов,
поиск по приметам и др. При этом не требовалось анализа некоторых сложных форм
ЕЯ. Имеются в виду случаи перечисления объектов, участвующих в однотипных
действиях (описываются одним глаголом), перечисления действий одного объекта и
др. В отличие от сказанного, при выявлении ролевых функций для каждого объекта
требуется указание его участия в каждом действии.
Во многих случаях
причиной неточностей в СП-документа явились многочисленные ошибки: отсутствие
знаков препинания или их наличие, где не требуется, не принятые сокращения,
разрывы в словах и много другое. Дело в том, что документы, входящие в сводки
происшествий, составляют на месте люди (милиционеры) различной степени
грамотности.
Определенные
трудности вызывает наличие в анализируемых глагольных формах словосочетаний,
представляющих причину действий («на
почве неприязненных отношений», «в
ссоре», «из хулиганских побуждений»,…), сопутствующие действия («при личном досмотре», при поставке
оружия», «во время кражи», …) и др. Многие
из таких словосочетаний в сводках происшествий встречаются регулярно и поэтому
задаются в виде перечней - в предметном словаре.
1.4
Средства выявления ролевых функций
Как уже говорилось, в рамках
предлагаемой методики (вместо применения синтактико-семантических форм к
документам) используются правила логического вывода и преобразования структур
знаний - СП-документов, в которых нет
морфологических признаков (типа кто, кого,…), а субъекты и объекты
различаются по их расположению в фрагментах РСС, представляющих действия:
субъект стоит впереди объектов. Имена фрагментов представляют характер
действий.
Обобщенные синтактико-семантические
формы трансформируются в фрагменты РСС, которые определяют преобразования и
логический вывод, осуществляемые продукциями языка ДЕКЛ. Они играют роль логико-семантической
оболочки,
определяющей преобразования и логический вывод на основе СП-документов.
После заполнения оболочки онтолого-фрагментарными знаниями
(ОФЗ), состоящими из упомянутых фрагментов РСС, образуется программа,
осуществляющая выявление ролевых функций и пополнение СП-документа
соответствующими фрагментами. При таком подходе удается избежать многих
трудностей, связанных с особенностями конструкций ЕЯ и спецификой использования
синтактико-семантических форм.
Возможны
различные варианты построения оболочек и представления соответствующих знаний,
которые различаются по степени их обобщенности [13]. Рассмотрим вариант, который
соответствует обобщенным формам, рассмотренным в п. 1.2. При этом лицо1, лицо2, … трансформируются в
константы MAN_1, MAN_2, …, для
которых с помощью фрагментов РСС указываются ролевые функции. Классы Класс_1,
Класс_2 трансформируются в константы CLASS_D1, CLAS_D2. …, а их элементы задаются как аргументы фрагментов,
именами которых являются эти константы.
Случай
1. Ролевые функции определяются именами действий.
В данном случае для выделения объектов
(фигурантов), которым требуется присвоение свойств (ролевых функций),
используются фрагменты следующего вида:
INTERPRET(MAN_2,FIO,"потерпевший")
FORMA_CC(MAN_2,CLASS_D4," ")
CLASS_D4(ОБРАТИТЬСЯ,ЗАЯВИТЬ,СООБЩИТЬ,СКОНЧАТЬСЯ,
…)
Первый фрагмент INTERPRET(…) означает, что из СП-документа
нужно выделять фрагменты вида FIO(…),
соответствующие фигурантам, и анализировать возможность присвоения им свойства
"потерпевший". Такие фигуранты условно обозначаются как MAN_2. Второй фрагмент FORMA_CC(…)
задает условия присвоения для MAN_2,
определяемое константой CLASS_D4. В третьем фрагменте
CLASS_D4(…) перечисляются слова, представляющие действия. Представляется
принадлежность слов к классу CLASS_D4. Если фигурант участвует в одном из
перечисленных действий, то ему присваивается свойство "потерпевший".
Такое участие выявляется путем анализа СП-документа. Если в нем имеется
фрагмент ОБРАТИТЬСЯ(…, N-, …), аргументом которого
является код FIO(…/N+), то добавляется
фрагмент N-("потерпевший"),
представляющий ролевую функцию соответствующего фигуранта.
Применительно СП-документа,
представленного в примере 2, анализ будет происходить следующим образом.
Последовательно выделяются фрагменты FIO(…), соответствующие фигурантом. Первым будет выделен FIO(МИТРОФАНОВ, …/2+). Его
код 2- является аргументом фрагмента ОБРАТИТЬСЯ(1-,2-/11+), представляющим
действие. В связи с этим к СП-документа будет добавлен фрагмент
11-("потерпевший"), который через обратный ЛП будет преобразован в
сообщение, что «Митрофанов Виктор
Михайлович является потерпевшим».
Подобные действия реализуются в рамках логико-лингвистической оболочки.
Случай 2.
Ролевые функции определяются действиями и поясняющими словами.
Для этого
используются те же фрагменты, как в первом случае, но при перечислении имен
действий вводятся дополнительные фрагменты, представляющие действия с
возможными поясняющими словами:
INTERPRET(MAN_1,FIO,"подозреваемый")
FORMA_CC(MAN_1,CLASS_D3," ")
ОБМАН(ПОТРЕБИТЕЛЬ,ПОКУПАТЕЛЬ/15+)
НАТРАВИТЬ(СОБАКА/16+)
ВЫРАЖАТЬСЯ(НЕЦЕНЗУРНЫЙ,БРАНЬ,МАТЕРНЫЙ,
…/17+)
CLASS_D3(ЗАДЕРЖАН,РАЗЫСКИВАТЬСЯ, …,15-,16-,17-)
Данные фрагменты определяют действия по
выделению лиц (MAN_1)
, которым присваивается свойство "подозреваемый". Для этого на уровне
структур знаний анализируется их участие в действиях «задержан», «разыскиваться», а также в составных действиях: «натравить собаку», «выражаться нецензурный
…», «выражаться матерными …» и
др.
В примере 2 код фрагмента FIO("
"," "," ",НЕСКОЛЬКО/6+), представляющего неизвестных
лиц, является аргументами фрагмента НАТРАВИТЬ(6-,СОБАКА/14+), представляющего действие «натравить» с поясняющим словом «собака». Поэтому добавляется фрагмент
6-("подозреваемый"), представляющий, что «неизвестные лица являются
подозреваемыми», и через обратный ЛП дается объяснение такому выводу, см.
ниже. Аналогичный вывод будет сделан на основе фрагмента ВЫРАЖАТЬСЯ(6-,НЕЦЕНЗУРНЫЙ,БРАНЬ/13+), но с
другими объяснениями.
Случай 3.
Действия определяют ролевые функции нескольких лиц.
Для этого
(дополнительно к фрагментам INTERPRET) добавляются фрагменты:
CLASS_D1(УДАРИТЬ,ИЗБИТЬ, … )
FORMA_CC(MAN_1,CLASS_D1,MAN_2),
где
FORMA_CC(…) указывает на необходимость поиска
двух лиц – "подозреваемый" и "потерпевший" (MAN_1 и MAN_2), участвующих в одном
действии, которые перечисляются в фрагменте CLASS_D1(…). Например, «некое одно лицо ударило другое …». В соответствующем фрагменте
УДАРИТЬ(…) код FIO(…),
соответствующий первому лицу, будет стоять впереди второго.
Приведенные
фрагменты РСС составляют знания ОФЗ, которые постоянно дополняются – за счет
пополнения классов новыми словами-действиями и поясняющими словами. Процесс
пополнения достаточно простой. Если не выявлена ролевая функция, то нужно
посмотреть в СП-документа, в каком действии участвует тот или иной фигурант (по
тексту легко определяется его роль). Далее, находятся соответствующие
константы, которыми пополняются классы знаний ОФЗ. В дальнейшем предполагается
автоматизировать процесс пополнения знаний ОФЗ следующим образом. В тексте
отмечаются слова, определяющие ролевые функции. Далее, в сформированном СП-документе
находятся соответствующие константы, которые пополняют знания ОФЗ.
Случай 4.
Ролевые функции определяются словами или словосочетаниями.
Такие функции
задаются с помощью правил, которые реализуются на языке ДЕКЛ. Вот некоторые из
них.
Правило А. Если в
документе, взятом из сводок происшествий, говорится о нескольких неизвестных
лицах, то они, как правило, и есть подозреваемые.
Правило В. Если в
документе говорится об одном неизвестном лице, для которого не выявлены ролевые
функции, и при анализе документа не выявлено подозреваемых, то это лицо и
является подозреваемым.
1.5 Объяснение результатов
Для объяснения
результатов разработан обратный ЛП, который на основе СП-документа
и дополнительных фрагментов к нему строит тексты на ЕЯ, которые выдаются
пользователю. Обратный ЛП работает следующим образом. По кодам фрагментов,
соответствующих объекту и действиям, он находит предложение (ПРЕДЛ_) и его
месторасположение в тексте документа. По аргументам этих фрагментов (словам в
нормальной форме) находит компоненты предложения, в которых описываются
упомянутые объект и действия. Эти компоненты преобразуются в форму, пригодную
для выдачи пользователю. Дело в том, что многие компоненты трансформируются в
зависимости от контекста. Например, «…угрожал
Петрову И.И. …», где при выдаче ФИО должно быть преобразовано
в «Петров И.И.»
Далее выдается
описание объекта на ЕЯ: его порожденное свойство и действия, объясняющие это
свойство – ролевую функцию.
Пример 3.
При использовании приведенных выше знаний ОФЗ знаний к СП-документа примера 2
будут сформированы ролевые функции, которые с помощью обратного ЛП будут выданы
пользователю в следующем виде:
неизвестные - подозреваемые,
так как - неизвестные , находясь в пьяном
виде учинили скандал,
выражались нецензурной бранью,
натравили собаку.
Митрофанов Евгений Михайлович , 1953 год
р. – потерпевший,
так как -
в ОВД обратился гр-н Митрофанов Евгений Михайлович , 1953 год р.,
так как - Митрофанов обратился в травмпункт.
Пример 4. Текст документа (с номером 27) взят из сводок ГУВД:
01.02.98
в 15.30 уч.инс. ОВД Навценей по ул.Вешняковская дом 39-Д в ЗАО "ТК
ВОСТОК" была задержана гр-ка
Яковлева Людмила Владимировна, прож: ул.Вешняковская 122-1-26,которая допустила
обман потребителей на сумму 9 руб.
После обработки текста
процессором ЛП сформирован содержательный портрет - СП-документа. При формировании ролевых функций были
использованы фрагменты - см. п.1.4, случай 2. В результате была выявлена
подозреваемая и были выданы следующие объяснения:
Яковлева Людмила Владимировна - подозреваемая,
так как - ОВД Навценей в ЗАО ` ТК ВОСТОК
` была задержана гр-ка Яковлева
Людмила Владимировна,
так как - которая допустила обман
потребителей на сумму 9 руб.
Другой
пример приведен на рис.1, где слева показан текст документа с номером 128. На
его основе с помощью ЛП был построен СП-документа. Путем использования
логико-семантической оболочки были проанализированы действия лиц и выявлены их
ролевые функции. Результаты выданы в виде объяснений, приведенных в правой
части рис.1.
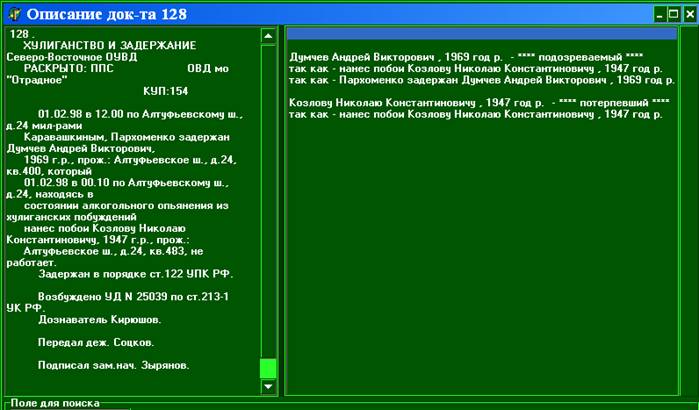
Рис.1. Пример объяснений ролевых функций
лиц.
Отметим, что все
рассмотренные действия, связанные с различными случаями выявления ролевых
функций и объяснением результатов, реализуются в рамках логико-семантической
оболочки, которая реализована в виде программы на языке ДЕКЛ. В связи с
ориентацией языка ДЕКЛ на обработку структур знаний (на РСС) и широкой
возможностью использования обобщенных продукций [3], программа на ДЕКЛ
получилась достаточно простой. Она содержит 16 продукций – около 4 кб. текста.
2
Выявление новых объектов и связей
В данном разделе будут рассмотрены
методики выявления новых объектов и связей, заданных в неявном виде, в процессе
синтактико-семантического анализа, а также средства реализации этих методик.
При выявлении новых объектов используется
принцип ожидания - после одних слов или объектов ожидается наличие
других. Например, если после слова «инженер»
стоит слово с большой буквы (и это не название организации), то скорее
всего, оно относится к ФИО. Таким образом начинается выделение объектов, у
которых нет характеристических слов, определяющих его наличие. Например, не
распознаны компоненты ФИО.
В текстах ЕЯ многие связи
подразумеваются и привязаны к типу выявленных объектов. Например, если выявлен
адрес, то скорее всего, он относится к какому-либо определенному лицу (или
организации), которое нужно искать. При результативном поиске формируется новая
связь. На этом основана методика формирования новых связей. Она заключается в следующем. В
процессе анализа текста строятся «временные» фрагменты, представляющие связи
выявленных объектов с пока что неизвестными объектами, которые специальным
образом отмечаются. В дальнейшем
осуществляется их поиск. Если соответствующий объект не найден, то «временный»
фрагмент удаляется из СП-документа. Если найден, то фрагмент остается и
вводится в структуру СП-документа.
Аналогичная методика используется при
формировании новых признаков. Формируется признак с пока что неизвестным объектом,
который в дальнейшем уточняется.
При формировании объектов и некоторые
компоненты могут быть сразу не найдены, например, год рождения, который в СП-документа
представляется как компонента ФИО. Тогда в соответствующих фрагментах
специальными константами отмечаются незаполненные аргументные места, которые в
дальнейшем уточняются. Для более детального описания методик и средств их
реализации рассмотрим правила и этапы построения СП-документов в процессе
синтактико-семантического анализа.
2.1 Правила синтактико-семантического анализа
Синтактико-семантический
анализ необходим для выделения связанных групп слов, а также информационных
объектов: адресов, номеров машин, организаций и др. Последние, как правило, это
наборы слов, которые могут быть грамматически никак не согласованы. Их
выделение осуществляется по чисто формальным принципам. Например, адрес может
рассматриваться как набор буквосочетаний «г.»,
«ул.», «д.»,.., слов с большой буквы и чисел. Каждый такой набор может иметь
свои границы и недопустимые компоненты. Например, в адресах не может быть ФИО,
глаголов и т.д. Выделение таких наборов слов (описаний объектов) основано на
использовании правил следующего вида:
CONTEXT(<слово1>,<слово2>,...,<словоN>) ->
<результ. фрагмент>
где <слово1>,... это может
быть - отдельное слово, признак, а также И-ИЛИ графы. Для этих правил
указывается, с какой позиции начинать применение, а также допустимый или
недопустимый контекст. Как правило, с упомянутой позицией связываются характеристические
слова, с поиска которых
начинается применение правила. При выделении лиц характеристическими словами
являются компоненты ФИО. При выделении адресов - ул., дом, кв. и т.д.
Правила синтактико-семантического анализа
выделяют из текста группы слов (по их признакам), описывающих какой-либо
объект, и заменяют их на одно (абстрактное) слово, с которым связывается
соответствующий фрагмент семантической сети и которому присваиваются определенные
морфологические характеристики (см. ниже).
Cинтактико-семантический анализ предложений с выделением
словосочетаний и анализом форм осуществляется на основе правил, которые
применяются в определенной последовательности. Вначале выделяются объекты,
затем их признаки, словосочетания, и наконец, глагольные формы, см. п. 2.2. По
мере применения таких правил строится семантическая сеть - содержательный
портрет документа. Например, рассмотрим правило с именем GG~1:
MUSTBE(GG~1,1) STR_OR(ADJ,PRON/2+) CONTEXT(2-,NOUN/GG~1)
P_P(GG~1,3+)
WORD_C(1,2/3-) 3-(2,MORF) NOTBE(GG~1,2,LETT)
Это правило осуществляет преобразования:
ПРИЛАГАТЕЛЬНОЕ + СУЩЕСТВИТЕЛЬНОЕ
-> <комбинация слов> и
МЕСТОИМЕНИЕ + СУЩЕСТВИТЕЛЬНОЕ -> <комбинация слов>.
Фрагмент
MUSTBE указывает, что применять правило GG~1 нужно с 1-ой позиции, т.е. искать
слова с признаками ПРИЛАГАТЕЛЬНОЕ (ADJ) и МЕСТОИМЕНИЕ (PRON), так как их
меньше, чем СУЩЕСТВИТЕЛЬНЫХ (NOUN).
Фрагмент P_P отделяет левую часть от
правой ( -> ), а WORD_C - указывает, что слова на 1-й и 2-ой позициях должны
быть склеены в комбинацию слов, которое в дальнейшем будет рассматриваться как
одно слово с морфологическими признаками 2-го слова. Фрагмент NOTBE указывает,
что на 2-ой позиции не могут быть отдельные буквы (признак LETT). К данному
правилу добавляется фрагмент, требующий согласованности слов ( по падежам,
числам), а также фрагменты, задающие контекстные ограничения.
Это пример наиболее простого правила.
Помимо правил выделения объектов, в ЛЗ имеются специальные правила, которые
осуществляют идентификацию объектов, например, с местоимениями или краткими
описаниями (по имени восстанавливается фамилия, если они где-нибудь упоминались
вместе). И многое другое, что необходимо для работы с естественным языком.
Отметим, что каждое контекстное правило
(как и все лингвистические знания) записываются в языке PCC. Над ними работают
продукции языка ДЕКЛ (программа), которые применяют эти правила и играют роль
пустой лингвистической оболочки, поддерживающей язык записи лингвистических
знаний - PCC. Как показывает опыт, такую оболочку можно настраивать на
различные языки, т.е. строить различные лингвистические процессоры, в том
числе, англоязычные.
2.2 Применение правил
Правила синтактико-семантического анализа
применяются в строго определенной последовательности - каждое на своем уровне.
Например, при обработке сводок происшествий вначале выделяются информационные
объекты - отделения милиции (ОВД_), сотрудники милиции (МИЛ_) и др. Они могут
содержать фамилии, имена, которые следует отличать от ФИО лиц – фигурантов (последние
представляются фрагментами FIO). Далее выделяются статьи УК и т.д. Это
необходимо, чтобы облегчить последующий анализ. Иначе слова, составляющие эти
объекты, могут захватываться другими правилами и создавать шумы.
Далее начинается выделение лиц -
фигурантов. Для этого вводится множество правил. Одни правила начинают свое
применение с поиска имен или фамилий (MUSTBE), другие - с поиска года рождения,
третьи - с инициалов. В результате минимизируются потери в случаях, когда блок
морфологического анализа не дает необходимых признаков для каких-либо слов (что
это имена или фамилии и т.д.).
Затем анализируются словосочетания,
выделяются объекты, и наконец, анализируются глагольные формы. По мере
применения таких правил строится СП-документа. Последовательность правил
задается с помощью специальных фрагментов. Ниже приведен пример представления
уровней, определяющих порядок применения правил.
{== Уровни ==}
LEVEL(LEVEL1,LEVEL2,LEVEL3,LEVEL4,...)
LEVEL1(CATALOG) {= Объединение словосочетаний из каталогов
=}
LEVEL2(MIL~1,ST~1) {= Выявление
отд.милиции, ст. УК =}
LEVEL3(FF~1,FF~2) {= Выявление лиц =}
LEVEL4(AA~1,AA~2) {= Выявление однородных членов =}
LEVEL4(GG~1,GG~2,...) {=
Выявление словосочетаний =}
. . .
В фигурных скобках даны комментарии.
Первый фрагмент LEVEL(…) задает уровни, а последующие – правила каждого
уровня. Правила начинают применяться к ПС-документа, представляющего линейную
структуру: последовательность слов в нормальной форме с указанием конца каждого
предложения. Все это представляется на РСС. Правила анализируют линейную
структуру, находят соответствующие группы слов, из которых формируются объекты.
При этом объекты как бы замещают эти слова. Линейная структура сохраняется, но
видоизменяется. В конце остается линейная структура (на РСС), компонентами
которой являются объекты и слова, не вошедшие в объекты (напомним, что события
и действия – это тоже объекты). На этой основе формируется СП-документа.
В ЛП имеются правила, которые обеспечивают
полный разбор предложений. При этом параллельно обеспечивается выделение
значимых (информационных) объектов, в том числе таких, в которых слова никак не
согласованы между собой, например, адресов, машин с указанием их номеров и т.д.
[см. также 1,3,13].
2.3 Выявление
объектов без характеристических слов
При наличии в тексте объектов без
характеристических слов возникают трудности их выделения. Например, если в тексте встречаются лица с
иностранными ФИО. У английских фамилий («Буш»,
«Блэк», «Барак», …) нет характерных суффиксов, как в русском языке. Более
того, в качестве фамилий может быть любое слово, называющее или определяющее
какой-либо предмет внешнего мира. При анализе англоязычных текстов такие
фамилии вносят элементы неопределенности – омонимии. В азиатских языках
компоненты ФИО – это просто слова с большой буквы («Ден Сяо Пин», «Хун Вай», …). Задать перечислением имена или фамилии
(в предметном словаре) не представляется возможным. В таких ФИО отсутствуют
характеристические слова. Требуются другие методики выделения. Аналогично,
адреса могут иметь вид – «Семеновская
2-44». Сказанное относится и к другим объектам.
Для выделения, как уже говорилось,
используется принцип «ожидания» - после одних объектов (или понятий) ожидается
наличие других. Реализация соответствующей методики осуществляется с помощью
операторов вида:
GO_(<Правило1>,<Правило2>,N),
где Правило1 – правило, которое было вызвано. И
если оно применилось, то оно вызывает Правило2, применение которого начинается
с позиции N.
Рассмотрим пример использования данного
оператора при выявлении ФИО. Это осуществляется с помощью двух правил – FA~1 и FF~1:
MUSTBE(FA~1,1) STR_OR(WORK_K,NAT_K/2+) CONTEXT(2-/FA~1)
P_P(FA~1,”
”)
GO_(FA~1,FF~1,1)
MUSTBE(FF~1,1) STR_OR(NAME0/3+)
CONTEXT(3-,3-,3-/FF~1)
FIO(1,2,3,” ”/4+)
P_P(FF~1,4-) 4-(FIO,ADD_)
MAYBE(FF~1,3)
STR_OR(VERB,ENG/5+)
NOTBE(FF~1,ALL,5-)
Правило FA~1 находит в
тексте слова с признаками WORK_K (профессии) и NAT_K (национальность). Такие признаки присваиваются словам
блоком морфологического анализа на основе предметных словарей, где даны списки
профессий, национальностей и др. [9,10]. И если
слово с таким признаком найдено, то вызывается правило FF~1, которое проверяет, чтоб за найденным словом стояли 3
слова с большой буквы (с признаком NAME0). При этом
такие слова не могут быть (NOTBE) глаголами
(которые имеют признак VERB) или англоязычными (их признак –
ENG), что задается с помощью двух последних фрагментов.
Фрагмент MAYBE(FF~1,3) указывает, что третья позиция
является факультативной, т.е. третьего слова с большой буквы (ББ) может не
быть. И все одно правило будет применимым. В случае применимости формируется
фрагмент FIO(…). У него в качестве первых трех аргументов будут
первые три слова, которые удовлетворяют условиям, заданным в фрагменте CONTEXT. Эти три слова заменяются на одно, с которым связывается
сформированный фрагмент и к которому добавляется признак FIO, что задается с помощью - 4-(FIO,ADD_).
Эти два правила правило осуществляет преобразования:
ПРОФЕССИЯ + 2 или 3 СЛОВА С ББ
-> <выделенное лицо>
НАЦИОНАЛЬНОСТЬ + 2 или 3 СЛОВА С
ББ -> <выделенное лицо>
Например,
словосочетание «инженер Лю Цао Хуань»
будет преобразовано в фрагмент FIO(ЛЮ,ЦАО,ХУАНЬ,”
”). При этом слово «инженер» останется
и будет использовано при последующем анализе. Словосочетание «президент Барак Абама» будет
преобразовано в фрагмент FIO(БАРАК,АБАМА,”
”,” ”).
Другой
способ выделения ФИО – через глаголы, субъектами которых могут быть только
лица. Например, «… Барак Абама предложил …», где глагол «предложить» помогает выделению лица.
Такие глаголы даются перечнем («предложить»,
«подписать», «согласиться» и
т.д.), а выделение лиц реализуется с помощью того же оператора GO_.
2.4 Выявление
признаков и связей
Для выявления связей, заданных в неявном
виде, используется следующая методика. В правые части синтактико-семантических
правил, выявляющие определенного типа объекты,
вводятся «временные» фрагменты, представляющие связь этих объектов с
пока что неизвестными объектами, которые в дальнейшем ищутся и уточняются с
помощью специальных процедур идентификации. Если неизвестный объект найден, то
«временный» фрагмент становится постоянным и
вводится в структуру СП-документа. Например, для адреса строится
фрагмент ИМЕТЬ(??_1,<адрес>) и в дальнейшем с помощью процедур
идентификации осуществляется поиск аргумента ??_1, соответствующего лицу или
организации. Найденный объект замещает этот аргумент.
Возможен и другой вариант, когда
предполагается, что у лица, встретившегося в тексте, должен быть задан адрес. Тогда в правую часть
правила, выявляющего лица, вставляется другой фрагмент ИМЕТЬ(<лицо>,
??_2), где аргумент ??_2 соответствует адресу. В дальнейшем осуществляется его
поиск.
Выбор варианта зависит от вероятности
наличия связи, что определяется особенностью корпусов анализируемых
текстов. Например, в сводках
происшествий не для каждого человека может быть задан адрес. И в тоже время,
если встретился адрес, то он, как правило, относится к какому-либо лицу. И
очень редко – к событию. В корпусах текстов области «Резюме», где описываются
данные людей для приема на работу, наоборот. Человек, который пишет резюме,
должен указать свой адрес, телефон и т.д. Поэтому и ЛЗ (состоящие из правил)
для каждой области будут иметь свои особенности.
Рассмотрим одно из таких правил,
соотносящих клички к лицам - фигурантам.
MUSTBE(FFA~1,2)
STR_OR(NAME0,КВЧ/1+)
CONTEXT(КЛИЧКА,1-/FFA~1) КЛИЧКА(??_1,2/2+)
P_P(FFA~1,2-)
GO_(FFA~1,ID_33)
Данное
правило FFA~1 ищет словосочетания следующего вида:
кличка + <слово с большой буквы (NAME0) или слово в кавычках (КВЧ)>.
И если такое словосочетание найдено, то
формируется фрагмент КЛИЧКА(??_1,<2-е слово>), где ??_1 соответствует
неизвестному лицу. После этого с помощью оператора GO_(FFA~1,ID_33) вызывается
процедура идентификации – ID_33, которая
осуществляет поиск лица. В результате формируется законченный фрагмент.
Например, если анализируется текст «… Иванов Сергей Сергеевич, 1955 г.р. …, по
кличке ‘серый’ …» , то правило FFA~1 делается
применимым к последнему словосочетанию. В результате формируется фрагмент КЛИЧКА(??_1,СЕРЫЙ).
После этого с
помощью оператора GO_ вызывается процедура ID_33, которая осуществляет поиск лица. Код фрагмента,
соответствующего найденному лицу, подставляется на место ??_1. В результате в СП-документа
формируются связанные фрагменты:
FIO(ИВАНОВ,СЕРГЕЙ,СЕРГЕВИЧ/3+) КЛИЧКА(3-,СЕРЫЙ).
Отметим, в другом варианте в правила,
осуществляющие поиск лиц, могут быть вставлены фрагменты, связывающие лица с
пока что неизвестными кличками. Но вероятность такой связи не велика, что
делает последующие поиски кличек мало результативными.
Процедура идентификации неизвестных
объектов задается в ЛЗ с помощью специальных правил идентификации,
каждое из которых содержит фрагмент ID_K, где указывается, какого типа объекты следует искать, в
каком направлении и когда заканчивать поиск. Поиск заключается в
последовательном переходе по шагам от одного компонента линейной структуры
(слова, выделенного словосочетания или объекта) к другой, начиная от того
места, где встретился знак неизвестного объекта - ??_N.
Отметим, что
правила идентификации могут вызываться на любом уровне анализа текста, см. п. 2.2
(а не только с помощью операторов GO_). Важно, чтобы
при вызове правила объекты, которые оно должно искать, были бы уже
выявлены.
Фрагмент ID_N имеет следующую структуру:
ID_K(??_N,А3,А1,А2,LEFT),
где ID_K – имя правила (через него
осуществляется вызов);
??_N – указывает на неизвестный объект;
А1 – задает
тип объекта, который нужно искать;
LEFT – указывает, что искать объект нужно слева (RIGHT – справа);
А2 –
ограничивает количество шагов поиска;
А3 – задает
поисковый режим: заканчивать (или нет) поиск, если встретился символ конца (или
начала) предложения.
Поиск начинается от того места линейной
структуры, где встретился знак неизвестного объекта - ??_N. И заканчивается,
если найден нужный объект или выполнены условия окончания. Это может быть:
допустимое количество шагов, наличие символа начала предложения, а также
специальные условия. Для их представления к основному фрагменту ID_K добавляются фрагменты, которые
задают недопустимые слова – в виде списка ли перечня:
STR_OR(<перечень недопустимых слов и
признаков>/2+) NOTBE(ID_32,”
”,2-)
Если в процессе движения по линейной
структуре встретилось слово, входящее в перечень, или компонента (слово,
словосочетание, объект), имеющее признак из перечня, то движение заканчивается.
Поиск считается не результативным.
Рассмотрим
пример поиска неизвестных лиц, отмеченных символом ??_1.
STR_OR(LR,SENT/24+) {= Допускается переход по словам и по предложениям
=}
STR_OR(FIO/27+)
{= Определяет идентификацию ??_1 – с лицами =}
STR_OR(ЗАДЕРЖАТЬ,НАНЕСТИ,POINT_1/2+) {= Что не допустимо при переходах
=}
ID_33(??_1,24-,27-,20,LEFT) NOTBE(ID_33,” ”,2-)
Данное правило определяет движение влево (LEFT) по линейной структуре от того места, где находится знак
??_1, с поиском фрагмента FIO(…),
представляющего лицо. Число шагов поиска - не более 20. При этом допускается
переход по словам (LR), а также от одного предложения к
другому (SENT), т.е. поиск не заканчивается, если встретился символ
начала предложения (или конца предыдущего). Но поиск заканчивается, если
встретились глаголы «задержать»,
«нанести» или слово (знакосочетание) с признаком POINT_1 – это пункты с
красной строки при перечислениях типа 1., 2., …
Аналогичная методика используется при
формировании новых признаков объектов. Рассмотрим пример:
MUSTBE(PROP~2,2)
STR_OR(БЕЗРАБОТНЫЙ,НАРКОМАН,ПРЕСТУПНИК/1+)
CONTEXT(1-/PROP~2)
1(??_1/2+) P_P(PROP~2,2-)
GO_(PROP~2,ID_33)
{== Уточняется ??_1 (чье свойство) ==}
Правило PROP~2 ищет слова «безработный», «наркоман», «преступник»
(их может быть больше). И если, к примеру найдено слово «безработный», то на основе 1(??_1/2+) формируется фрагмент типа БЕЗРАБОТНЫЙ(??_1).
Далее вызывается (GO_) правило идентификации ID_33, которое ищет лицо, к
которому относится данное свойство. Конечно, правила выявления лиц должны быть
вызваны раньше, чем PROP~2.
2.5
Уточнение неопределенных компонент
Достаточно часто при анализе текста,
выявлении объектов и формировании соответствующих фрагментов некоторые
компоненты могут оставаться неизвестными. Например, если они описаны где-то в
другом месте. Например, в текстах резюме год рождения может находиться на
значительном расстоянии от лица. В сводках происшествий имеет место тот же
случай. Например, «… Иванов Иван,
сотрудник ООО «Алмаз», … 1966 г.р.,
…». Тогда формируется фрагмент с
неизвестным компонентом FIO(ИВАНОВ,ИВАН,”
”,??_2), где аргумент ??_2 в дальнейшем уточняется с помощью соответствующего
правила идентификации.
Рассмотрим пример.
MUSTBE(FF~3,3)
CONTEXT(FAM,NAME,NAME_1/FF~3)
FIO(1,2,3,??_2/3+) P_P(FF~3,3-)
3-(FIO,ADD_)
С помощью данного правила FF~3
осуществляется поиск трех слов, где первое имеет признак фамилия (FAM), второе – имя (NAME), а третье – отчество (NAME_1). Это задается фрагментом CONTEXT(…/FF~3). Если поиск
оказался результативным, то в рамках линейной структуры формируется фрагмент,
который замещает эти слова:
FIO(<1-е слово>,<2-е слово>,<3-е
слово>,??_2).
Далее на одном из уровней (когда уже
сработали правила выделения года рождения) вызывается правило идентификации
ID_4, которое имеет вид:
STR_OR(LR,SENT/25+)
STR_OR("гг.рожд."/26+) {== С чем идентифицируется ??_2 ==}
ID_4(??_2,25-,26-,8,RIGHT) {= Ищет вправо от фрагмента с ??_2 =}
За счет перемещения вправо (RIGHT)
осуществляется поиск объекта - года рождения. При ограничении – не более, чем 8
шагов. Этого достаточно, учитывая, что многие объекты уже найдены (описывающие
их слова заменены на одно слово) и перемещение по каждому из них – это один
шаг.
Заключение
В данной статье рассмотрены результаты
работ, выполненных в рамках проекта «Лингво-ИИ» в течение 2010 г. [13]. Рассмотрены
семантические методики (и средства их реализации) по извлечению некоторых видов
имплицитной информации из естественного языка (ЕЯ).
В связи с высокой сложностью конструкций
ЕЯ, с которыми имеет дело лингвистический процессор, создание средств выявления
имплицитной информации представляет собой важную научную и практическую задачу
бурно развивающейся области «автоматическое извлечение знаний из текстов ЕЯ».
Практическая ценность выполненных работ определяется возрастающей потребностью
автоматической формализации быстро растущих потоков документов на естественном
языке, особенно в среде всемирной сети Интернет.
Литература
1. Igor Kuznetsov, Elena Kozerenko. The system for
extracting semantic information from natural language texts // Proceeding of
International Conference on Machine Learning. MLMTA-03, Las Vegas US,
2. Кузнецов И.П. Семантико-ориентированная
система обработки неформализованной информации с выдачей результатов на
естественном языке // Сб. ИПИ РАН, Вып. 16,
3. Кузнецов И.П., Мацкевич А.Г.
Семантико-ориентированные системы на основе баз знаний (монография) // М.
МТУСИ,
4. Kuznetsov I.P., Kozerenko E.B. Linguistic Рrocessor “Semantix” for Knowledge extraction from natural texts in Russia and English // Proceeding of
International Conference on Machine Learning, ISAT-2008.
5. Падучева Е.В. Высказывание и ее
соотнесенность с действительностью (монография) // М. Наука, 1985г.
6. Кондрашова Д.С. К проблеме
классификации типов имплицитной информации // Материалы VIII
Международной конференции ‘Cognitive Modelling in Linguistics’, Varna,
2005, Т. 1., стр. 245-252.
7. Пирогова Ю.К. Имплицитная информация как
средство коммуникативного воздействия и манипулирования// Сб. Проблемы
прикладной лингвистики, М
8. Кузнецов И.П. Сомин Н.В. Англо-русская
система извлечения знаний из потоков информации в среде Интернет // Сб. ИПИ
РАН,
9. Кузнецов И.П., Сомин Н.В. Средства настройки семантико-ориентированной
системы на выделение и поиск объектов // Системы и средства информатики, Вып.
18. ИПИ РАН,
10. Кузнецов И.П., Сомин Н.В. Особенности
лексико-морфологического анализа при извлечении информационных объектов и
связей из текстов естественного языка // Вып.19. ИПИ РАН. 2009. – с.97-118.
11. Banko M., M. Cafarella, S. Soderland,
M. Broadhead, and O. Etzioni. Open Information Extraction from the Web // Proceedings
of the 20th International Joint Conference on Artificial Intelligence
(IJCAI-07), 2007. P. 2670–2676.
12. Clark P., P. Harrison, and J. Thompson.
A Knowledge-Driven Approach to Text Meaning Processing // Proceedings of the
HLT-NAACL 2003 Workshop on Text Meaning, 2007. P. 1–6.
13. Разработка и исследование методов автоматического извлечения из
естественно-языковых текстов имплицитной информации об объектах, признаках и
связях с ее отображением на структуры знаний (Линво-ИИ)// Отчет ИПИ РАН о НИР,
№ гос.рег. 01201000922.