1. Логико-аналитическая система «Аналитик-2»
Проведенный анализ научно-технических достижений позволил
выработать требования и создать новую
комплексную логико - аналитическую систему
работы с неструктурированной информацией используя ЗАПРОС на
естественном языке . Логико-аналитическая система получила возможность
эффективно работать в различных предметных областях. Общая схема созданной
системы приведена на рис. 1.
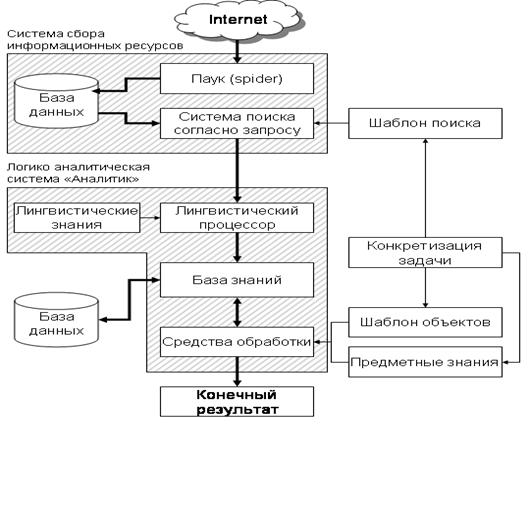
Рис. 1 - Общая схема системы
Система состоит из двух компонент. Первая компонента–система
сбора информационных ресурсов в соответствии с запросом. Её задача найти в сети
Internet WEB-страницы, которые могут
интересовать пользователя и выделить из них части (параграфы), которые могут
быть использованы для получения результатов. Эта компонента включает в себя Spider (паук),
скачивающий документы из заданного списка сайтов сети Internet, систему поиска документов и выделения наиболее значимых
частей текста, которая для уменьшения конечного объема информации и использует
для этой цели запрос, состоящий из ключевых слов.
Вся полученная в результате обработки информация подается на
вход логико–аналитической системы для дальнейшей обработки.
Второй и основной компонентой
логико-аналитической системы является лингвистический процессор (ЛП), который
отображает предложения естественного языка на базу знаний (БЗ). ЛП включает в себя блоки морфологического анализа, контекстного
анализа, синтактико-семантического
анализа и логико-аналитической обработки. Результатом работы лингвистического
процессора являются расширенные семантические сети, образующие так называемый
содержательный портрет этого документа. Морфологический анализ обеспечивает преобразование слов к
единому виду – каноническому, с указанием
формы слова, и вводит
дополнительные признаки слов (часть речи, число …). Такое
преобразование позволяет избавиться от различных форм написания.
Для контекстного анализа используются:
· типовые словосочетания,
· И-ИЛИ
графы, задающие контекст, а также
· характеристические слова и
ограничители.
Синтактико-семантический
анализ служит для выделения из документа значимых компонент и связей. В
результате по документу строится его содержательный портрет, представляющий
интересующие пользователя объекты и их связи.
База знаний
(БЗ) обеспечивает хранение содержательных портретов документов, а так же
эффективный поиск и анализ информации по связям и значимым компонентам. База
данных используется базой знаний как хранилище больших объемов информации
(оригиналов документов, содержательных портретов документов).
С помощью
разнообразных средств обработки решаются различные логико-аналитические задачи.
При решении задач используются предметные знания, и шаблоны объектов,
определяемые конкретной задачей.
Конечные результаты передаются в зависимости от задачи на интерфейс
пользователя или в базу данных.
2. Разработка блока быстрого поиска материалов
В дальнейшем при
описании работы системы будут применяться общепринятые термины:
- URL адрес - Система адресации и собственно сами адреса в HTML
документах . Адрес URL является сетевым расширением понятия полного имени файла
в операционной системе (пути к файлу).
- Протокол HTTP - HyperText Transport Protocol (протокол передачи
гипертекста).
- Параграф – часть
текста, насыщенная ключевыми словами, в которой содержится интересующая
пользователя информация.
-Релевантность (relevancy) – это «нужность», или, другими словами, соответствие
информации ожиданиям пользователя. WEB сервер – это
приложение, работающее на рабочих станциях обычно под управлением операционных
систем Unix или Windows и других платформах. Основная задача WEB – сервера – обработать информационный запрос пользователя и
отправить в ответ информационный пакет.
– WEB Browser – это специальный
просмотровщик, который позволяет пользователю осуществлять доступ к информации,
предоставляемой WEB – сервером. WEB броузер обеспечивает дружественный интерфейс.
2.1 Система сбора информационных ресурсов в
соответствии с запросом пользователя.
Рассматриваемая система сбора информационных ресурсов (Аналитик-2)
скачивает документы из глобальной сети Internet, индексирует, сохраняет
полученную информацию в базе данных,
проводит поиск по запросу, состоящему из ключевых слов и параметров
поиска (логических выражений, дополнительных параметров тонкой настройки),
фильтрует, выделяет наиболее важную
информацию и предоставляет результы в удобной для дальнейшего анализа форме
(вывод в файл, на экран).
Работа системы полностью определяется пользователем в виде
входных параметров: списка Интернет адресов для скачивания и индексирования,
глубины и периода скачивания документа, ключевых слов и других параметров. В
настоящее время одним из важнейших направлений является создание удобного,
настраиваемого и «интеллектуального» поиска информации в сети Internet.
2.2 Описание поисковой системы Аналитик-2.
Поисковая система Аналитик-2 (общая схема показана на
рисунке 7.2) представляет собой самостоятельный программный продукт, который
для решения поставленной задачи работает в
рамках логико-аналитической системы.
Отличительной чертой системы Аналитик-2 (её поискового алгоритма) от
других подобных систем является возможность выделения частей текста
(параграфов), содержащих ключевые слова из запроса и отфильтровывание другого
рода данных (кнопок, элементов навигации, не содержательных текстов). Таким образом, в процессе работы программы
уменьшение количества исходной информации сводится к двум этапам:
·
нахождение документов, содержащих
заданные ключевые слова,
·
выделение из документов наиболее
значимых частей текста.
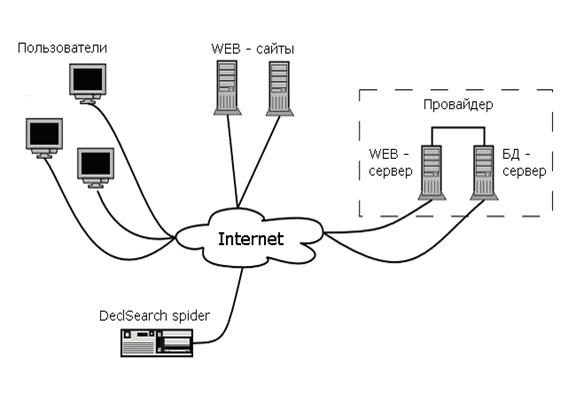
Рисунок 2 - Общая схема поисковой системы.
Система сбора информационных ресурсов (Аналитик-2) состоит
из двух программных компонент: HTTP-паука (spider),
написанного на языке программирования Perl и непосредственно
осуществляющего функции получения, обработки и сохранения/удаления документа; и
шаблонного интерфейса, написанного на языке программирования PHP,
осуществляющего поиск по ключевым словам, анализ и отбор документов по их
релевантности.
Ключевые слова, список сайтов, скачанные сохраненные тексты
хранятся в базе данных MySQL, которая используется как пауком
(spider), осуществляющим операции сохранения информации в БД, так и
поисковым интерфейсом, извлекающем информацию из хранилища. Взаимодействие
между пользователями, программой и WEB ресурсами происходит через сеть Internet. База данных – важнейшая
компонента системы Аналитик-2. Именно на нее возлагается «ответственность» за
сохранность гигантского количества скачанных документов. Её внутреннее
устройство нацелено на реализацию конкретной задачи с высокой скоростью и
эффективностью работы, и большими объемами хранимых данных.
Структура базы данных,
используемой поисковой системой Аналитик-2 приведена на рисунке 7.3
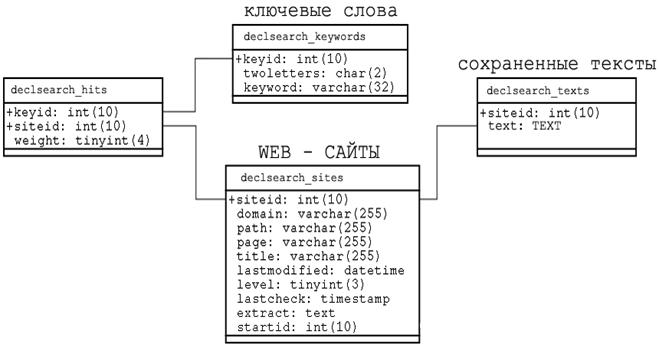
Рисунок 3 - Структура базы данных
.
Таблица Web–сайтов: используется для
хранения информации о проиндексированных сайтов. Она содержит уникальный идентификационный
номер (ID) сайта, по которому осуществляется привязка к таблице
ключевых слов, домен (часть URL адреса, содержащего имя сервера,
например «rambler.ru»), путь к странице (часть URL адреса,
содержащего полный путь к папке WEB сервера в котором лежит документ
(например «/content/about»), название
файла страницы (или список параметров + имя скрипта (если страница является CGI
скриптом), текст названия страницы (определяется специальными HTML тэгами
«<TITLE>» в коде страницы), дату последнего изменения
(отправляется WEB - сервером), глубину индексации,
дату последней проверки, начальные данные, стартовый ID для
страницы.
Таблица ключевых
слов: хранит ключевые слова и использует связь
«один-ко-многим» с таблицей сайтов, таким образом, исключается избыточность
данных в случае, если одно ключевое слово встречается на многих сайтах.
Таблица текстов: хранит тексты из документов, без HTML кода.
Сохранять тексты полностью необходимо в том случае если есть необходимость
осуществлять поиск не только по ключевым словам, но и по фразам (комбинациям
ключевых слов). Таблица связана с таблицей WEB сайтов по
уникальному идентификатору.
3 Алгоритм работы паука (spider)
В рамках решения поставленной задачи был разработан следующий алгоритм
работы паука (spider). Структурная схема показана на рис.
4.

Рис. 4 - Структурная схема работы паука (spider).
Если на вход программе подается URL адрес, он попадает в
базу данных (БД). Далее основная часть программы выбирает из базы данных
все сайты, последняя дата обновления которых старше заданного в файле
конфигурации (или командной строке)
периода.
Для каждого сайта производится процедура скачиваниия. Если
страница больше не существует, то WEB-сервер посылает код ошибки - 404.
Это является признаком того, что документ следует удалить. Также документ
удаляется, если содержимое запрашиваемого документа не является текстом
(например, картинка или другой тип файла). При удалении сайта из базы данных
удаляются также все привязанные ключевые слова и тексты.
В случае успешного скачивания документа, первым шагом
анализа документа является выделение из заголовка названия полученного
документа, начало содержательной части страницы.
На втором шаге выделяются все ссылки, которые встречаются в HTML коде
страницы. Если глубина индексации страницы больше 0, то паук (spider) добавляет
выделенные ссылки в очередь на индексирование. На завершающем этапе происходит
выделение, подсчет и сохранение ключевых слов, выделение текстовой информации
из HTML кода и ее сохранение в базе данных.
Основная часть программы (выделенная на рис. 4 пунктиром)
может выполняться в несколько процессов параллельно. Это обусловлено тем, что
время, которое требуется для получения документа из сети Internet, достаточно велико из-за сравнительно медленной скорости
соединения с Интернет и возможно большим временем отклика от запрашиваемого WEB-сервера, и,
с другой стороны, быстрой обработкой уже скачанного документа. Для того, чтобы
программа не простаивала в ожидании получения очередного документа, допускается
возможность параллельного выполнения. От количества параллельных процессов
зависит загрузка центрального процессора компьютера, этот уровень может
регулироваться количеством параллельно запущенных процессов (определяется при
настройке программы).
3. Алгоритм нахождения документов и деления текста документа на наиболее значимые части,
согласно ключевым словам
Отличительной чертой системы DeclSeacrh (её поискового алгоритма) от других подобных систем
является возможность выделения частей текста (параграфов), содержащих ключевые
слова из запроса и отфильтровывание другого рода данных (кнопок, элементов навигации,
несодержательных текстов). Структурная
схема приведена на рисунке 7.5. Система
работает, используя интервалы отступа влево и вправо от ключевых слов на
заданное расстояние и общепринятые признаки разделения текста на смысловые
параграфы (отступы, пустые строки, табуляцию…), для выделения тематически
отделенных фрагментов текста.
Интервалы отступов, ключевые слова и логические выражения
(поддерживаются конъюнктивные формы «AND» и «OR») вводятся пользователем через
интерфейс программы.
Запрос к поисковой системе представляет собой конъюнктивную
нормальную форму ключевых слов с ограничителями.
Примеры запросов:
а) «sale» - одно ключевое слово.
б) «sale AND Georgia» - несколько ключевых слов, разделенных конъюнктивными формами «AND» или «OR».
в)«(sale sell sold) AND (Georgia Washington) OR (Mortgage)» Множества ключевых слов, объединенных в скобки и разделенных
конъюнктивными формами «AND» или «OR».
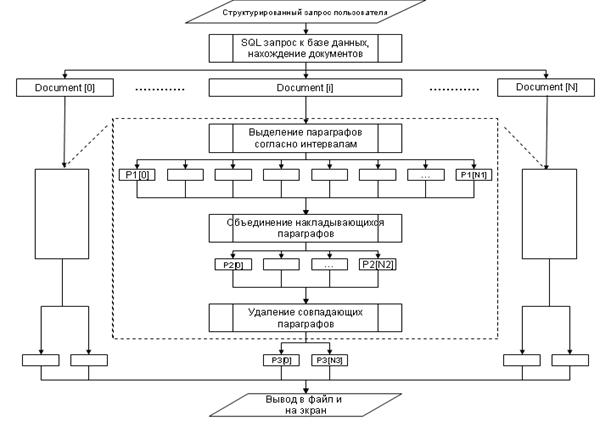
Рис. 5 - Структурная схема алгоритма
разбиения тексты на релевантные параграфы
От типа запроса зависит процесс формирования SQL команды.
Границы параграфов задаются элементами интерфейса программы.
На втором этапе включается морфологический модуль, который
получает список слов с учетом русской морфологии. Например, для введенного
ключевого слова: «бег», система получает слова: «бега», «бегу», «бегом»,
«беге», «беги», «бегов», «бегам», «бегами», «бегах». И таким образом, расширяет диапазон ключевых слов.
Для морфологического поиска по базе данных применяется
таблица MySQL, содержащая 2 поля: «индекс исходного слова», «слово».
Для составления данной таблицы применяется небольшой скрипт
на языке программирования Perl, который генерирует все словоформы русского
языка при помощи словарей Ispell. Ispell – программа
для проверки орфографии в среде UNIX, LINUX.
На вход программе подаются
два файла:
Файл префиксов и суффиксов
Файл, содержащий словарь
русских слов.
Был использован
словарь, состоящий из 120 тысяч слов. После дополнения всех слов суффиксами и
префиксами, база данных состоит из более миллиона слов. При запросе на поиск документов, система
получает индекс ключевого слова, далее находит в базе данных слова с таким же
индексом и расширяет список ключевых слов всеми их формами.
На следующем этапе формируется SQL – запрос к
базе данных. В него включаются все слова, введенные пользователем плюс их
словоформы. Все слова разделены в SQL запросе логическими выражениями AND или OR, согласно
запросу пользователя.
Далее система получает список документов, в которых
введенные слова найдены, и приступает к работе с конкретными текстами
документов, выделяя параграфы.
В тексте находится ключевое слово, запоминается его позиция
в тексте и от нее берутся отступы влево и вправо. Границы интервалов могут
попасть на середину слова, чтобы избежать «обрезков» слов, делается отступ
влево или вправо до конца или начала предложения (точки) или, если не найден
конец или начало предложения, до конца или начала слова. Таким образом, получается множество кусков текста, в которых
содержатся ключевые слова. Для каждого такого куска система запоминает
начальную и конечную позиции.
Полученные куски текста могут пересекаться (накладываться),
поэтому следующим шагом является склеивание пересекающихся частей между
собой. В результате множество параграфов уменьшается, и появляются идентичные
параграфы, устранения которых происходит на следующем этапе.
Если в запросе были применены конъюнктивные формы («AND» или «OR»),
вызывается процедура, выбирающая из всего множества параграфов только те, в
которые попали обязательные ключевые слова (соединенные AND).
У каждого параграфа существуют свойства, которые можно использовать
для сортировки и определения границ выдаваемых результатов:
стартовая позиция в тексте;
конечная позиция;
длина;
количество ключевых слов, попавших в данный параграф;
количество всех ключевых слов в параграфе;
плотность ключевых слов (отношение длины текста к количеству
найденных ключевых слов в параграфе).
Конечным результатом работы поисковой системы является
множество параграфов, выделенных из текстовых документов. У каждого параграфа
также сохраняется ссылка на URL адрес исходного документа, на
случай, если пользователь затребует исходный документ.
В конфигурационных параметрах программы указывается путь к
каталогу, в котором находится программа DECL. В этом
каталоге сохраняются все найденные фрагменты текста и запускается программа DECL в фоновом
режиме. Вызывающая программа ждет появления в каталоге файла с расширением *.res, что
является признаком того, что DECL завершил свою работу.
Результирующий файл имеет строгую структуру, что позволяется
вызывающей программе путем простых манипуляций выделить пары «ключ - значение».
Эти значения представляются пользователю в удобной для чтения форме, в данном
случае в виде HTML размеченной страницы в окне
Интернет броузера.
4. Лингвистический процессор для автоматического выявления из текстов значимой информации

Рис.9 Основные этапы автоматического анализа текста
Выделенные параграфы
обрабатываются лингвистическим процессором, который формирует Базу Знаний (БЗ).
Объектные поиски осуществляются путем сопоставления семантической структуры
запроса и содержимого БЗ.
Алгоритмы разработанной
логико-аналитической системы доведены до уровня практической реализации.
Система в данный момент находится на стадии тестирования в реальных
производственных условиях. Опытная эксплуатация разработанного ПО показала, что
имеется ряд дополнительных возможностей, позволяющих унифицировать структуру
каталогов и тем самым упростить ПО, что позволит устранить дуализм словарей, поместив все каталоге в одном
словарном файле. Это помимо унификации, ускорит поиск, ибо на каждое слово
нужно будет только одно обращение к словарной системе.
Кроме того, возможно увеличение
типов каталогов со своими специфическими особенностями. В перспективе видится
специальный параметрический язык настройки описания каталогов и его реализация
под имеющуюся словарную систему.
В результате проведенной работы
были существенно расширены возможности семейства логико-аналитических
систем (Аналитик, Криминал), благодаря созданию двух новых программных
компонент – системы сбора информационных ресурсов и модуля внешней базы данных
была повышена общая производительность систем, появилась возможность доступа к
неисчерпаемым информационным ресурсам сети Интернет.
Система
сбора информационных ресурсов имеет самостоятельную ценность и может
применяться как полностью независимый продукт, для решения разного рода задач
поиска и фильтрации информации. Примененные на стадии разработки средства
обеспечивают переносимость на любые Unix- и Microsoft Windows платформы.
Применение
мощного математического аппарата - расширенных семантических сетей (РСС),
позволяет по новому анализировать информацию. В отличие простого нахождения
совпадений, РСС позволяет выделять объекты и их признаки, связи, то есть именно
то, что ищет в информации пользователь.
Сегодня только лишь
подход, основанный на построении семантических сетей, свободен от ограничений,
присущих двоичному поиску; он обладает достаточной гибкостью, доступен для
расширения и не слишком громоздок при эксплуатации. Пользователю очень важно иметь в
распоряжении информационно-поисковую систему, которая обеспечит
дифференцированный поиск Интернет – ресурсов и выделение из них компонент,
интересующих пользователя. Вся ненужная информация фильтруется и не включается
в отчет о поиске. Такая система решает
новый класс практических задач.