Семантико-ориентированный лингвистический процессор Semantix.
Кузнецов И.П. (igor-kuz@mtu-net.ru), ИПИ РАН,
Кузнецов К.И..
Аннотация
Лингвистический процессор Semantix предназначен
для областей, где требуется автоматическая формализация потоков текстов на
естественном языке: резюме, сообщения СМИ, информационно-рекламные материалы, почтовые
сообщения, сводки происшествий, справки по уголовным делам, архивные материалы
и др. Из текстов (документов) извлекаются интересующие пользователя объекты, их
свойства и связи. Представляются факты участия
объектов в действиях. Последние сами рассматриваются как комплексные объекты с
их свойствами и связями. В результате на основе каждого документа строится
специального вида семантическая сеть, отражающая его семантическую структуру.
Такие сети отображаются на XML-файлы, которые служат для организации Баз Знаний,
соответствующих семантических поисков, для решения логико-аналитических задач,
а также для автоматического заполнения реляционнных БД.
Введение
Следует учитывать, что большая категория
пользователей имеют определенные служебные обязанности, и соответственно, постоянные интересы. Им необходима вполне
конкретная информация. Например, сотрудники информационно-аналитических
подразделений выбирают из СМИ информацию об интересующих их событиях,
катастрофах, террористических актах, персоналиях и др. Следователю важны
фигуранты, места их жительства, телефоны, криминальные события, даты и др.
Сотруднику кадровой службы нужно знать организации, где, кем и в какое время
кандидат работал. Подобная информация называется информационными объектами
или просто объектами [1,2,10]. Объекты различаются по типам. Каждая из
перечисленных категорий пользователей интересуется набором объектов
определенного типа. Находить нужные объекты в потоке текстов, читая их, во
многих областях - непосильный труд.
Для обеспечения подобных пользователей
нужной информацией требуются средства автоматического извлечения объектов из
текстов с их представлением в формах, удобных для восприятия или последующей обработки.
Речь идет об автоматической формализации текстов, связанной с извлечением
знаний (Knowledge Extraction). Это проблемная область, которая
находится в сфере внимания исследователей. Ее актуальность постоянно растет [3,4,5].
Особенность наших исследований – в их ориентации на логико-аналитическую обработку.
Для этой цели на протяжении последних 15 лет в рамках проектов ИПИ РАН
разрабатывались семантико-ориентированные лингвистические процессоры для
аналитических служб. Первый процессор построен более 10 лет назад для
логико-ангалитической системы Криминал [6,7]. Их научная база: расширенные
семантические сети (РСС), методики представления сложных видов знаний, инструментальная
среда ДЕКЛ обработки структур знаний, сетевые позиционные грамматики,
онтологии в формате РСС, морфологический анализ на основе обобщенных окончаний
[1,2,14]. Последний вариант такого процессора, изготовленного совместно с ЗАО
<Синергетические Системы> в виде модуля SDK, получил название Semantix.
1. Основные
компоненты процессора Semantix.
Лингвистический
процессор Semantix предназначен для областей, где требуется автоматическая
обработка потоков текстов на естественном языке (ЕЯ):
резюме, сообщения СМИ, информационно-рекламные материалы, почтовые сообщения,
сводки происшествий, справки по уголовным делам, архивные материалы и др. Из
текстов (документов) выделяются интересующие пользователя объекты, их связи, а
также факты участия объектов в тех или иных действиях или событиях. Последние сами рассматриваются как комплексные
объекты с их свойствами и связями. В результате на основе каждого документа
строится специального вида семантическая сеть (РСС), представляющая его семантическую
структуру. Такая сеть отображается на XML-файл. С их помощью
значительно облегчается последующий автоматический анализ. XML-файлы являются
основой для составления досье, обзоров, отчетов. Другой вариант их
использования - автоматическое заполнение реляционных БД или формирование
собственной Базы Знаний с последующей организацией направленного поиска
нужной информации (объектов), в том числе, различных видов семантического
поиска.
Основные компоненты процессора Semantix:
1.1.
Блок лексического и морфологического
анализа. Выделяет из текста слова и предложения, приводит слова нормальную
форму и формирует семантическую сеть, представляющую пространственную структуру текста
(ПС),
где отображается последовательность слов, их основные признаки, начало
предложений и наличие пробельных строк. Блок использует специальный набор
тематических словарей (словарь стран, регионов России, имен, видов оружия и
др.) для группирования слов и придания им дополнительных семантических
признаков [14].
1.2.
Блок синтактико-семантического анализа.
Он преобразует одну семантическую сеть (ПС) в другую, представляющую семантическую
структуру текста (СС), т.е. выделенные объекты и их
связи. Последнюю часто называют содержательным портретом
документа [9,10].
Блок управляется лингвистическими знаниями (ЛЗ), которые определяют процесс
анализа текста. ЛЗ включают в себя специального вида контекстные правила, которые
обеспечивают высокую степень избирательности при выявлении (извлечении) объектов
и связей [8].
Задачи этого блока:
- Извлечение из потока ЕЯ-документов
информационных объектов: лиц, организаций, действий, их места и времени, и многих
других объектов.
- Выявление связей объектов. Например, как
лица связаны с организациями (МЕСТО_РАБОТЫ),
адресами (ПРОЖИВАЕТ, ПРОПИСАН).
Или как фигуранты связаны с объектами типа оружие, наркотики (ИМЕТЬ).
- Анализ глагольных форм, причастных и
деепричастных оборотов с выявлением фактов участия объектов в соответствующих
действиях. Например, один фигурант передал другому фигуранту наркотики – это факт,
связывающий фигурантов.
- Выявление связей действий с объектами
типа место или время (где и когда имело место данное действие или событие).
- Анализ причино-следственных и временных
связей между действиями и событиями.
1.3. Экспертные системы (ЭС). На основе сети
СС формируют новые знания - в виде дополнительных фрагментов РСС. Например, при
обработке тектов резюме по каждой автобиографии ЭС выявляют область деятельности
лица по его автобиографии (в соответствии с заданным классификатором). Оценивается
опыт его работы. При анализе криминальных действий ЭС осуществляют соотнесение криминального
происшествия к определенному типу: выявляют характер преступления, способ его
совершения, орудие и т.д. (в соответствии с классификаторами криминальной
милиции).
1.4. Обратный лингвистический процессор,
преобразующий содержательный портрет документа (семантическую сеть СС) в
XML-файл. При этом осуществляются необходимые замены символов, служебных слов (имен объектов), выставляются метки
начала и конца объектов, действий, предложений. Преобразование осуществляется
без потери информации. XML-файл устроен таким образом, что в нем представлены
все выявленные компоненты и связи. В случае необходимости, обеспечивается
обратное преобразование XML-файл в сеть СС.
1.5. База лингвистических и
экспертных знаний (БЗ). Содержит
правила анализа текста и экспертных решений во внутреннем представлении. Они определяют
работу лингвистического процессора. Semantix имеет несколько таких баз, которые
активизируются в зависимости от предметной области и задач пользователя, см. п.4.
2.
Выделяемые объекты и связи.
Набор выделяемых объектов зависит от задач
пользователя. В тоже время, качество
лингвистического процесора в значительной степени определяется возможностями
такого выделения. Ниже перечислены основные типы информационных объектов
и связей, извлекаемые Semantix:
- лица (по ФИО) с их особенностями
(потерпевший, террорист и др.);
- адреса, почтовые атрибуты;
- организации;
- должности;
- террористические группы, ОПГ;
- номера телефонов, факсов, электронных
постовых адресов с их стандартизацией;
- средства транспорта с выделением марки
машины, государственного
номера, цвета и других
атрибутов;
- количественные характеристики (сколько
лиц или других объектов принимали участие в том или ином событии);
- паспортные данные и другие документы с их
атрибутами;
- взрывчатые вещества;
- наркотические вещества;
- оружие с атрибутами;
- словесное описание лиц, их приметы;
- номера счетов, суммы денег с указанием
типа валюты;
- события (криминальные, террористические,
поломки изделий и др.) с указанием участия в них информационных объектов;
- время и место событий;
- связи между различными типами
информационных объектов, включая комплексные объекты (действия или события);
- другие объекты (опыт работы, знание
языков ... до 40 типов).
На рис.1 представлено графическое
изображение этих объектов в ДЕМО-версии. (ДЕМО-версия в сети
Интернет находится на сайте www.semantix4you.com).
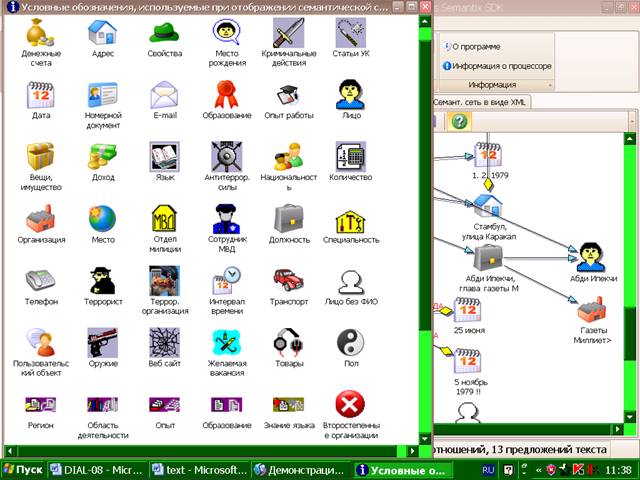
Рис.1.
Набор выделяемых объектов процессором Semantix.
При выделении объектов учитываются
возможные варианты называния объекта в тексте, в том числе, в краткой форме. Типовые объекты (ФИО, даты, адреса, должности и др.) приводятся к
одному (стандартному) виду. Осуществляется
идентификация объектов с учетом кратких наименований (например, отдельных
фамилий или имен с ФИО), анафорических ссылок (указательных и личных
местоимений, например, "Этот
человек", "Он ..."), определений (например, "Мэр Москвы Лужков" идентифицируется
с последующими словами "мэр",
"Лужков").
Выделение связей - это не только глубинный
анализ глагольных и других форм. Многие связи даются по умолчанию. Например, в
сводках происшествий, как правило, за ФИО фигуранта следуют его данные без
указания их принадлежности и с дополнительными текстовыми вставками. В связи с
этим в процессоре Semantix для ряда объектов организуется направленный поиск связанных
объектов, т.е. восстановление связей, данных по умолчанию. Для этого организуются
специальные процессы, чтобы связать лицо с его местом проживания или местом
работы, принадлежащим ему автотранспортом и т.д. Наример, при анализе сводок
происшествий это делается следующим образом. Для ряда объектов (адрес, телефон,
г.рожд и др.) строится виртуальная связь с другими объектами (ФИО, организации), пока
неизвестными. Далее, на одном из уровней
обработки с помощью специальных правил идентификации производится их
поиск. В этих правилах указывается направление поиска, допустимое количество
шагов, а также признаки слов и знаки
препинания, где процесс поиска следует заканчить. При этом требуются
специальные фильтры, чтобы не захватить и не связать посторонний объект. Такой
подход показал достаточно хорошие
результаты в системе Криминал [6].
В результате строится РСС, называемая содержательным портретом документа.
При этом учитываются особенности ЕЯ, где с помощью глаголов, отглагольных
существительных и причастных оборотов задаются одни и те же действия. При
представлении на РСС они приводятся к одному виду – комплексному объекту. Более
того, формы с отглагольными существительными могут быть компонентами глагольных
форм. Аналогично, в РСС одни объекты могут быть компонентами других.
Представляются причино-следственные и временные зависимости между действиями,
событиями, которые отражают логическую связь предложений, заданную в явном виде
– с помощью слов типа поэтому, затем
и др. Пример содержательного портрета,
изображенного в виде графа, представлен на Рис.2.
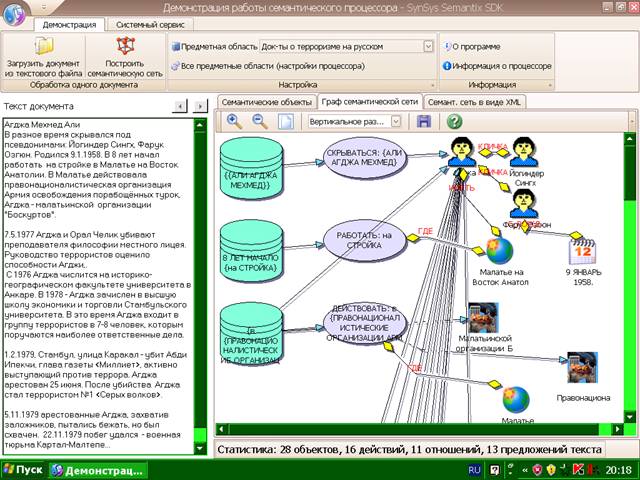
Рис.2. Графическое представление
содержательного портрета документа.
На данном примере видно, что фигурант Агджа Мехмет Али во многих случаях
задается его именем Агджа и в
результате идентификации имеет много связей. С помощью эллипсов изображаются
действия, которые связываются с предложениями.
3. Факторы, определяющие качество процессора
Качество лингвистического процессора
определяется рядом факторов. Во-первых, это возможности выделения объектов и
связей. Имеется в виду типы выделяемых объектов, их количество. Процессор Semantix выделяет до 40 типов объектов, в том числе
комлексных объектов, соответствующих действиям и событиям. С увеличением
количества возникают дополнительные трудности, связанные с
"коллизией" правил выделения: одни правила могут захватывать слова,
относящиеся к другим объектам и выделяемым другими правилами. становится важным
порядок применения правил, в том числе, правил идентификации..
Во-вторых, важный фактор - это избирательность
правил
и процедур идентификации: коэффициент шумов и потерь. Под шумами
понимается наличие лишних слов в объектах. Потери - это когда объект не выявлен
или выявлен частично: в тексте есть слова, которые не вошли в объект. В
процессоре Semantix правила устроены таким образом, что они обеспечивают
высокую степень избирательности и минимизацию шумов и потерь при большом
количестве выделяемых объектов, см. п.3.
Третий фактор - возможность и трудоемкость настройки на корпус
текстов (для повышения избирательности правил выделения объектов), а также настройки
на новые объекты. В связи со сложностью процессов анализа такая настройка
должна осуществляться через лингвистические знания (ЛЗ). Последние должны иметь
все средства для повышения избирательности правил и необходимые удобства в
плане их создания и корректировки. В идеале с помощью ЛЗ должна обеспечиваться
настройка на особенности языка - признаки, которые даются словам, на типовые
конструкции и формы языка. Лингвистический процессор должен быть в значительной
степени индифирентен к языку. Его задача - поддерживать ЛЗ, в том числе,
процесс применения правил выделения идентификации.
По такому принципу организован процессор
Semantix, в котором за счет ЛЗ обеспечивается анализ сложных конструкций
русского языка, а также анализ англо-язычных
конструкций и форм, выделение англо-язычных объектов и их связей. Другими
словами, обеспечивается анализ не только русского, но и английского языка. Это
говорит об универсальности процессора.
Четвертый фактор - скорость работы
лингвистического процессора, т.е. время анализа текстов. Скорость
определяется конструктивными особенностями процессора (средствами уменьшения
переборов), а также количеством выделяемых объектов. Применение правил их
выделения связано с поиском нужных слов, где требуются переборы. Чем больше объектов
и правил, тем больше переборов и больше время анализа.
В процессоре Semantix имеются различные
средства уменьшения переборов. Помимо программных,
также имеются средства, управляемые с помощью ЛЗ. Для каждого правила
указывается, какие слова следует искать для инициирования процесса его
применения. Задаются допустимые контексты (слева и справа от выявляемых слов),
факультативные элементы [8].Таким образом обеспечивается достаточно высокая
скорость (доли секунды на 1 кб. текста)
при достаточно большом количестве выделяемых объектов. Отметим, что если
объектов мало, то скорость значительно возрастает. В связи с этим в ЛЗ введены
специальные средства, использующие список значимых слов и признаков (указывающих
на наличие объектов) для выделения значимых предложений. Только их следует анализировать.
И если в тексте много предложений без объектов, то таким образом скорость можно
увеличить на порядки.
4. Предметные области.
Настройка на предметную область
осуществляется при наличии соответствующего корпуса текстов путем разработки
лингвистических знаний (ЛЗ), определяющих набор выделяемых объектов и связей. У
коллектива разработчиков имеется большой опыт настройки на различные предметные
области и корпуса текстов - для русского и английского языков, см. рис.3. Результатом являются отлаженные правила ЛЗ, обеспечивающие
выделение большого количества разнотипных объектов (до 40 типов).
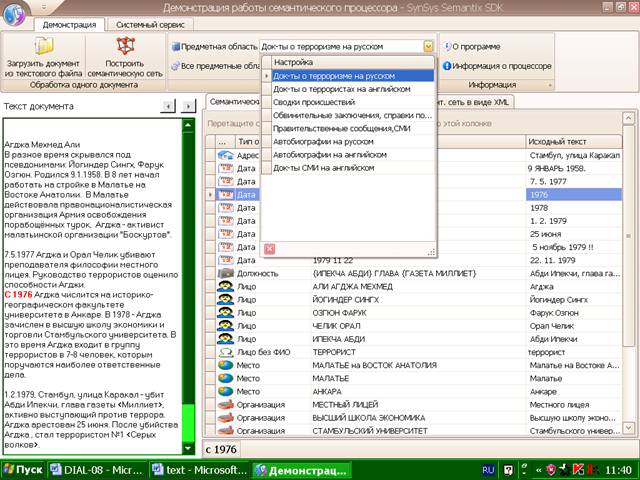
Рис.3.
Предметные области, на которые настроен процессор Semantix:
Рассмомтим эти области более подробно:
4.1.
Документы о терроризме на русском языке. Анализ документов, в
которых речь идет о террористических
актах и группах. Обеспечиваетя выделение до 40 типов объектов, их связей и
степень участия в криминальных действиях.
4.2.
Документы о террористах на английском языке. Выделяются
руководящие и другие лица, должности, организации, террористические группы,
орудия преступления, время и место событий и т.д., а также связи и участие в
действиях.
4.3.
Сводки происшествий. Обеспечивается
выделение фигурантов, их связей, организаций, дат, документов, номеров счетов,
оружия ... (до 40 типов объектов) с указанием их участия в криминальных
действиях
4.4.
Обвинительные заключения, справки по
уголовным делам. Объекты идентифицируются по всему полю текста. Выявляются их
связи и криминальные действия.
4.5. Правительственные сообщения, СМИ.
Выделяются лица, даты, организации, должности и другая значимая информация, а
также связи и участие в действиях.
4.6. Автобиографии на русском языке. Из русскоязычных резюме выделяются все атрибуты человека,
периоды времени и место его работы, учебы, знание языков и т.д.
4.7.
Автобиографии на английском языке. Из
англоязычных резюме выделяются все атрибуты человека (см.п. 4.6.).
4.8. Документы СМИ на английском. Из
англоязычных текстов выделяются упомянутые в СМИ лица,
должности, организации,
даты, террористические и антитеррористические группы, оружие, события, их время. место, различные связи и др.
Как результат достаточно эффективного
процесса настройки на различные предметные области, в Semantix
имеется достаточно большой набор правил избирательного выявления из текстов
разнотипных объектов.
Первые правила,
осуществляющие выделение дат, адресов, лиц, автотранспорта, криминальных
объектов (оружие, наркотики) и др., отлаживались на корпусе текстов ГУВД г. Москвы:
сводки происшествий, справки по уголовным делам, записные книжки фигурантов и
др. (более 500 тыс. документов). Никаких ограничений на тексты не
накладывалось. И этого нельзя было делать, так как большие потери криминальной
информации недопустимы. При этом удалось добиться уникальных результатов.
Коэффициент шумов удалось свести до уровня, не превышающего 1-2%, а коэффициент
потерь около 1%.
Далее ЛЗ были настроены на выделение
объектов из автобиографий, написанных на русском языке. При этом потребовалась
настройка на значительное количество объектов нового типа [13]. Соответствующие
правила отлаживались на корпусе текстов, состоящих более чем из 1000 резюме.
Стояла задача обработки любых текстов резюме с возможностью использования
процессора для компаний, работающих до настоящего времени с неформализованными
резюме.
Далее, процессор был настроен на работу с
резюме на английском языке. Использовался корпус текстов около 500 резюме.
Построение англоязычного процессора на базе русскоязычного носило в большей
степени экспериментальный характер. В процессор были добавлены средства,
учитывающие особенности английского языка – словообразование, многозначность
слов и др. При этом удалось добиться достаточно хорошего качества [16].
Следующий этап - это тексты СМИ с
дополнительным выделением террористических организаций, групп, отдельных лиц, а
также сил, противоборствующих терроризму. Потребовались дополнительные правила для
выделения арабских ФИО, идентификации объектов и др. Правила ЛЗ отлаживались на
корпусе текстов около 1000 сообщений СМИ, правительственных сообщений и
материалов из других источников (документы от 2-х до 40 кб.). Далее за счет ЛЗ
процессор был настроен на работу с документами СМИ на английском языке [12].
Результатом явилось большое количество отлаженных правил выделения объектов из
различных текстов русского и английского языков. В рамках системы Semantix пользователю
предоставляется возможность выбора этих объектов. Еще раз отметим, что если
пользователю не требуется анализа предложений или его не интересуют какие-либо
объекты из заданного перечня, то он указывает это в соответствующем меню. В
результате скорость анализа может возрасти на порядок.
Заключение
В настоящее время предлагается версия семантико-ориентированного лингвистического процессора - Semantix
1.0, обрабатывающего документы в различных предметных областях на
русском и английском языках. Качество работы процессора может оценить любой
пользователь на своих документах, выйдя на сайт [16].
Semantix 1.0 представляет собой библиотеку
COM-объектов и функций, предназначенную для автоматической обработки текстов естественного
языка- русского и английского. Модульная структура Semantix позволяет без больших
трудозатрат встраивать его в системы обработки текстовой информации, например,
системы документооборота, электронные издания и т.п. Представляется также
перспективным использование Semantix 1.0 как основу организации баз знаний и
разичного вида семантических (объектных) поисков.
Литература
1. Кузнецов И.П.
Семантические представления // М.: Наука. 1986г. 290 с.
2. Кузнецов И.П., Мацкевич А.Г.
Семантико-ориентированные системы на основе баз знаний. Монография.
М.Связьиздат. 2007. 173 с.
3. Cunningham, H. Automatic Information
Extraction // Encyclopedia of Language
and Linguistics, 2cnd ed. Elsevier, 2005.
4. Han J. and Kamber, M.
Data Mining: Concepts and Techniques // Morgan Kaufmann, 2006.
5. FASTUS:a
Cascaded Finite-State Trasducerfor Extracting
Information from Natural-Language Text. // AIC, SRI International. Menlo Park. California, 1996.
6. Кузнецов И.П. Методы обработки сводок с выделением особенностей
фигурантов и происшествий // Труды международного семинара Диалог-1999 по
компьютерной лингвистике и ее приложениям. Том 2. Таруса 1999.
7. Кузнецов И.П., Мацкевич А.Г. Система
извлечения семантической информации из текстов естественного языка // Труды
международной конференции Диалог 2001 по компьютерной лингвистике и её
приложениям: Т.2. М.: Наука 2002.
8. Кузнецов И.П., Особенности
обработки текстов естественного языка на основе технологии баз знаний // Сб.
ИПИ РАН, Вып.13,
9. Kuznetsov, I., Kozerenko, E. The system for extracting semantic
information from natural language texts // Proceeding of International
Conference on Machine Learning. MLMTA-03, Las Vegas US, 23-26 June 2003, p. 75-80.
10. Кузнецов И.П., Мацкевич А.Г. Англоязычная
версия системы автоматического выявления значимой информации из текстов
естественного языка // Труды международной конференции по компьютерной
лингвистике и интеллектуальным технологиям "Диалог 2005", Звенигород,
2005.
11. Кузнецов И.П., Мацкевич А.Г. Семантико-ориентированный
лингвистический процессор для автоматической формализации автобиографических
данных // Труды международной конференции по
компьютерной лингвистике и
интеллектуальным технологиям "Диалог 2006", Бекасово, 2006, стр.
317-322.
12. Кузнецов И.П., Сомин Н.В.
Англо-русская система извлечения знаний из потоков информации в Интернет-среде. //
Сб. ИПИ РАН, Вып.17, 2007,
стр. 236-253.
13. Кузнецов И.П., Мацкевич А.Г. Лингвистические
и алгоритмические аспекты выделения объектов и связей из
предметно-ориентированных текстов // Труды международной конференции по компьютерной
лингвистике и интеллектуальным технологиям "Диалог 2007", Бекасово,
2007, стр. 333-342.
14. Сомин Н.В., Соловьева
Н.С.., Шарнин М.М. Система
морфологического анализа: опыт эксплуатации и модификации // Системы и
средства информатики, Вып. 15 // ИПИ РАН - М.: Наука, 2005. - с. 20-30.