Извлечение знаний из текстов естественного
языка
Это
одна из наиболее актуальных задач областей «лингвистика» и «информатика».
Тексты – это наборы слов и знаков, из которых нужно выделить то, что интересует
пользователя. Пример такого выделения представлен на следующем рисунке:
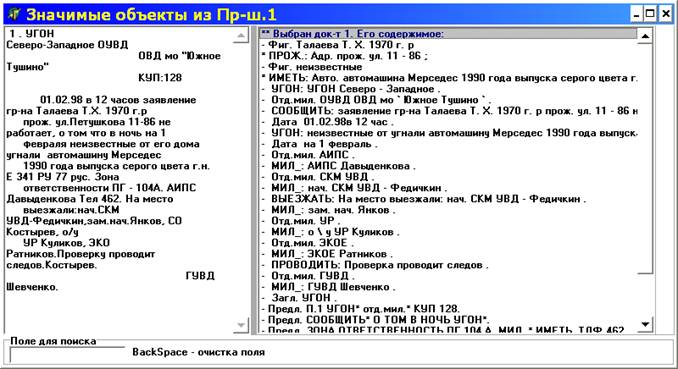
За
последнее время одной из важнейших проблем является автоматическая обработка
текстов, получаемых пользователями, в том числе через ИНТЕРНЕТ. Лавинообразный
рост объемов документов требует дифференцированного извлечения только такой
информации, которая может заинтересовать пользователя. Речь идет о
содержательной обработке, т.е. извлечении знаний из текстов.
Трудности такой обработки определяются особенностями естественного языка (ЕЯ):
наличием большого количества словоформ, синтаксических конструкций,
неоднозначностей, умолчаний и др. В связи с этим, уровень формализации текстов
в существующих системах (полнотекстовых баз данных, системах на гипертекстовой
основе) невысок, что зачастую не устраивает пользователя.
Полнотекстовые
базы данных не решают проблемы, так как при работе с текстами на ЕЯ дают много шумов (лишних
документов) и потерь. Причина этому - свободный порядок слов в русском языке,
явление омонимии и полисемии. Одно и тоже можно
выразить множеством различных способов. Более того, слова запроса могут быть
разбросаны по тексту документа и относиться к различным сущностям. Все одно
документ будет найден. Например, нужно найти Иванова Ивана, а в документе упоминаются Иванов Петр и Петров Иван.
Такой документ при поиске будет считаться адекватным. Чтобы уменьшить процент
шумов используют различные методы: вводят критерии близости слов, обрезают
окончания словоформ, вводят индексирование нормализованных слов и др. Но и это
кардинально не решает проблемы.
Другой
вариант - это использование реляционных БД. Но для этого требуются трудоемкая
работа специально обученных людей по формализации текстов на
ЕЯ: выделение из текстового документа (происшествия)
лиц, адресов, дат,... и заполнение соответствующих таблиц БД. При больших
потоках документов это сделать крайне трудно. В любом случае будут потери той
информации, которая не учтена в рамках схем (таблиц) БД.
Описанная
ситуация является типичной для многих других областей, имеющих дело с потоками
информации в виде текстов на ЕЯ:
через СМИ, ИНТЕРФАКС, из специальных источников.
Отметим,
что в настоящее время в глобальной сети Интернет хранится огромное количество
всевозможной информации. Подавляющее большинство документов - это текстов на ЕЯ. На данный момент в качестве помощи пользователю,
работающему в Интернет, предлагается класс поисковых машин, которые
обеспечивают возможность контекстного поиска по ключевым словам запроса.
Поисковая машина является универсальным инструментом и дает много лишней
информации, которую конечному пользователю приходится самостоятельно анализировать.
Причиной этому является неспособность поисковой машины вылавливать то, что
интересует пользователя.
В
тоже время большинство конкретных пользователей - это люди, которые
интересуются конкретными вещами. Например, следователю важны фигуранты, их
место жительства, телефоны, криминальные события, даты и др. Специалиста по
кадрам интересуют организации, где человек работал, кем он работал
и когда это было. Другие люди вылавливают из СМИ информацию о странах,
влиятельных лицах, катастрофах и др. Здесь важны и связи: место работы с
занимаемой должностью, экстремальная ситуация с ее временем и т.д. Будем
называть интересующую пользователя конкретную информацию - информационными
объектами. Каждый пользователь (или класс пользователей) интересуется своими
объектами и связями между ними. Вся остальная информация является лишней и
человек старается ее просто не замечать. Отсюда часто используемая людьми
методика чтения "по диагонали", или "с поиском ключевых
слов".
Перспективное
направление в области информатики (обработки документов на
ЕЯ) должно учитывать, прежде всего, интересы конечного
пользователя. Отсюда следует необходимость построения нового класса
информационных систем, использующих специальные лингвистические процессоры и
технологию баз знаний (БЗ). Лингвистические процессоры необходимы для глубинной
обработки текстов с выявлением информационных объектов и связей. На основе
последних формируются структуры знаний, которые образуют БЗ. На уровне БЗ
становится возможным более полно учитывать потребности пользователя - за счет
организации различных видов поиска: поиска конкретных объектов, поиска похожих
объектов, поиска по связям и др. Такие виды поиска относятся к
"семантическим", так как осуществляется не на уровне слов или
словоформ, а на уровне структур знаний из БЗ. Будем называть системы подобного
типа семантико-ориентированными.