Семантико-ориентированные лингвистические процессоры
Обеспечивают глубинный анализ текстов естественного языка с выделением
знаний, интересующих пользователя, работающего в конкретной предметной области.
Процесс такого анализа, выполняемый объектно-ориентированным лингвистическим
процессором, представлен на следующем
рисунке:
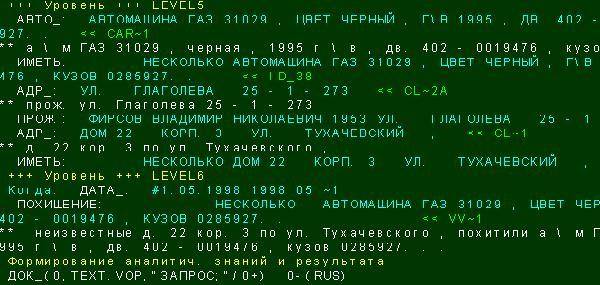
В данном разделе рассматривается новый класс лингвистических
процессоров (ЛП), ориентированных на обработку текстов естественного языка:
сводок происшествий, сообщений средств массовой информации и др. ЛП
осуществляет их преобразование в структуры БЗ. Такие ЛП выделяют из текстов
семантически значимую информацию: интересующие пользователя объекты, их
количественные, качественные характеристики и связи. Например, это могут быть
конкретные люди, их адреса, телефоны, организации, а также производства с
указанием их месторасположения, состава выпускаемой продукции, их количества,
качества и т.д. Их еще называют значимыми или информационными объектами. Под
связями понимаются отношения (принадлежности, родственные), участие в одном
действии, время, место события. ЛП состоит из оболочки, управляемой лингвистическими
знаниями.
1. Прямой лингвистический процессор
Лингвистический процессор (ЛП)
обеспечивает автоматическое построение содержательных портретов. Он включает в
себя лексикографический, морфологический, терминологический и
синтактико-семантический анализ.
Морфологический анализ необходим, чтобы избавиться от
различных форм написания слов, и облегчает поиск. Терминологический анализ
обеспечивает выделение терминов, а также синонимичные преобразования.
Синтактико-семантический анализ осуществляется специальными контекстными
правилами (см. п.4) и служит для выделения из
документа значимых компонент и связей.
Блок лексикографического анализа обеспечивает:
- автоматическое деление текста
на самостоятельные части (например, выделение документов из сводок)
- определения начала и конца
предложения, а также начала и конца абзаца.
Морфологический анализ имеет целью - приведение слов
в каноническую форму. Каждому слову присваиваются признаки, которые делятся на
три группы:
- лексические
(слово с большой буквы, большими буквами, с точкой на конце или это отдельная
буква и др.);
- морфологические
(грамматическая категория слова, род, число, падеж для существительных и т.д.);
- семантические (фамилия, имя,
отчество и др.).
Количество семантических
признаков может увеличиваться - за счет специальных словарей - организаций,
стран, городов и др. Само слово в нормальной форме тоже считается признаком.
Блок морфологического анализа
основан на обобщенных окончаниях слов. В этот блок введено лишь несколько
десятков тысяч слов, из которых специальной программой выделены типовые
окончания слов различных грамматических категорий. Благодаря им
обеспечивается морфологический анализ неизвестных слов, что осуществляется с
достаточно высокой надежностью.
Результатом работы блока
морфологического анализа является семантическая сеть (РСС), представляющая
пространственную структуру текста. В ней представлены слова в нормальной форме
с их признаками и указанием их последовательности. Последующая обработка
сводится к преобразованию сетей на основе заданных правил.
Терминологический анализ имеет целью - синонимичные
преобразования, расшифровку сокращений, выделение терминов. Для этого
используются фрагменты следующего вида:
TERMIN(<результ.слово>,<слово1>,<слово2>)
или
TERMIN(<результ.слово>,<слово1>,<слово2>,<слово3>),
где <слово1>,... это может
быть - отдельное слово, признак, а также И-ИЛИ графы. Фрагменты типа
"ИЛИ" представляется STR_OR(...), где перечисляются факультативные
слова или их признаки. Фрагменты типа "И" представляется STR_AND(...),
где предполагается обязательность слов с указанными признаками.
Например,
TERMIN(БЕЗРАБОТНЫЙ,НЕ,РАБОТАЮЩИЙ)
указывает на преобразование: НЕ РАБОТАЮЩИЙ ->
БЕЗРАБОТНЫЙ.
Другой
пример:
TERMIN(МО,МОСКОВСКИЙ,3+) STR_OR(ОБЛ.,ОБЛ,ОБЛАСТЬ/3-)
задает множество преобразований: МОСКОВСКИЙ ОБЛ. ->
МО, МОСКОВСКИЙ ОБЛ -> МО, МОСКОВСКИЙ ОБЛАСТЬ ->
МО.
Для терминов может быть задан
допустимый контекст - слова или их признаки, стоящие слева и справа. Может быть
также указан недопустимый контекст - слова или их признаки, которых не должно
быть слева или справа. В результате удается выделять термины и словосочетания,
значения которых зависят от контекста.
Для
синонимов используются многоместные фрагменты:
SYNON(<результ.слово>,<исх.слово>
... <исх.слово>).
Например, SYNONIM(УКРАИНЕЦ,ХОХОЛ)
- слово ХОХОЛ должно быть заменено на
УКРАИНЕЦ.
Многие синонимы носят условный
характер. Для них указывается допустимый или недопустимый контекст. Например, в
приведенном выше случае недопустимы замены для слов - фамилий, кличек, названий
улиц и др.
Блок синтактико-семантического
анализа
выполняет следующие функции:
- по признакам и контексту
выделяет значимые объекты (ФИО людей, организации и др.);
- для каждого выявленного
значимого объекта находит в документе связанную информацию (для лиц это их год
рождения, пол, адрес и др.).
Для
этого используются "контекстные" правила.
2. Контекстные правила
Синтактико-семантический анализ
необходим для выделения адресов, номеров машин, организаций и др. Как правило,
это наборы слов, которые грамматически никак не согласованы. Их выделение может
осуществляться по чисто формальным принципам. Например, адрес может
рассматриваться как набор буквосочетаний Г., УЛ., Д.,.., слов с большой буквы и
чисел. Каждый такой набор может иметь свои границы и недопустимые компоненты.
Например, в адресах не может быть ФИО, глаголов и т.д. Выделение таких наборов
слов (описаний объектов) основано на использовании контекстных правил
следующего вида:
CONTEXT(<слово1>,<слово2>,...,<словоN>)
-> <результ. фрагмент>
где <слово1>,... это может
быть - отдельное слово, признак, а также
И-ИЛИ графы. Для этих правил
указывается, с какой позиции начинать применение, а также допустимый или
недопустимый контекст. Далее, может быть указано, слово
с какими признаками не должно стоять на той или другой позиции. Это
обеспечивает дифференцированное применение правил.
Такие правила выделяют из
текста группы слов (по их признакам), описывающих какой-либо объект, и заменяют
их на одно слово, с которым связывается соответствующий фрагмент семантической
сети, например, представляющий адрес.
Cинтактико-семантический анализ предложений с выделением словосочетаний и
анализом форм осуществляется на основе контекстных правил, которые применяются
в определенной последовательности. Вначале выделяются объекты, затем их
признаки, словосочетания, и наконец, глагольные формы. По мере применения таких
правил строится семантическая сеть - содержательный портрет документа.
Например, рассмотрим правило GG~1:
MUSTBE(GG~1,1) STR_OR(ADJ,PRON/2+) CONTEXT(2-,NOUN/GG~1)
P_P(GG~1,3+)
WORD_C(1,2/3-) 3-(2,MORF) NOTBE(GG~1,2,LETT)
Это
правило осуществляет преобразования:
ПРИЛАГАТЕЛЬНОЕ СУЩЕСТВИТЕЛЬНОЕ -> <комбинация
слов> и
МЕСТОИМЕНИЕ
СУЩЕСТВИТЕЛЬНОЕ -> <комбинация
слов>.
Фрагмент MUSTBE указывает, что
применять правило GG~1 нужно с 1-ой позиции, т.е. искать слова с признаками
ПРИЛАГАТЕЛЬНОЕ (ADJ) и МЕСТОИМЕНИЕ (PRON), так как их меньше, чем
СУЩЕСТВИТЕЛЬНЫХ (NOUN). Фрагмент P_P отделяет левую часть от
правой ( -> ), а WORD_C - указывает, что слова на 1-й и 2-ой позициях должны
быть склеены в комбинацию слов, которое в дальнейшем будет рассматриваться как
одно слово с морфологическими признаками 2-го слова. Фрагмент NOTBE
указывает, что на 2-ой позиции не могут быть отдельные буквы (признак LETT).
Это пример наиболее простого
правила. К таким правилам добавляются фрагменты, указывающие на контекст, на
возможность каких-либо символов внутри и др. Специальные правила осуществляют
идентификацию объектов, например, на основе местоимений или кратких описаний
(по имени восстанавливается фамилия, если они где-нибудь упоминались вместе). И
многое другое, что необходимо для работы с естественным языком.
Каждое контекстное правило -
это семантическая сеть (PCC). Все лингвистические знания записываются в виде
PCC. Над ними работают продукции языка ДЕКЛ (программа), которые применяют эти
правила и играют роль пустой лингвистической оболочки, поддерживающей язык
записи лингвистических знаний - PCC. Как показывает опыт, такую оболочку можно
настраивать на различные языки, т.е. строить различные лингвистические
процессоры.
3. Применение правил
Контекстные правила применяются
в строго определенной последовательности - каждое на своем уровне. Например,
при обработке сводок происшествий вначале выделяются информационные объекты -
отделения милиции, работники милиции и др. Они могут содержать фамилии, имена,
которые не являются фигурантами (последние представляются фрагментами FIO).
Далее выделяются статьи УК и т.д. Это необходимо, чтобы облегчить последующий
анализ. Иначе слова, составляющие эти объекты, могут захватываться другими
правилами и создавать шумы.
Далее начинается выделение
фигурантов. Для этого вводится множество правил. Одни начинают свое применение
с поиска имен, фамилий (MUSTBE), другие - с поиска года рождения, третьи - с
инициалов. В результате минимизируются потери в случаях, когда блок
морфологического анализа не дает необходимых признаков для каких-либо слов (что
это имена или фамилии и т.д.). Затем анализируются словосочетания, и наконец,
глагольные формы. По мере применения таких правил строится семантическая сеть -
содержательный портрет документа. Ниже приведен пример представления уровней,
определяющих порядок применения правил.
== Уровни ==
LEVEL(LEVEL1,LEVEL2,LEVEL3,LEVEL4,...)
LEVEL1(CATALOG) = Объединение словосочет.
из каталогов =
LEVEL2(MIL~1,ST~1) = Выявление отд.милиции,
ст. УК = LEVEL3(FF~1,FF~2) = Выявление
фигурантов = ...................................
== Грамматический разбор, выделение словосочетаний =
== AA~.. - однородные члены,
GG~.. - словосочетания == LEVEL4(AA~1,AA~3,AA~4,GG~1,GG~2,...)
== GG~1: Словосочетание ПРИЛАГАТЕЛЬНОЕ - СУЩЕСТВИТЕЛЬНОЕ
==
MUSTBE(GG~1,1)
STR_OR(ADJ,PRON/2+) CONTEXT(2-,OBJ/GG~1) P_P(GG~1,3-)
WORD_C(1,2/3+) 3-(2,MORF) NOTBE(GG~1,2,LETT)
== GG~2: Словосочетание
СУЩЕСТВИТ.- СУЩЕСТВИТ.+ КОГО =
MUSTBE(GG~2,2)
STR_AND(КОГО,OBJ/4+) CONTEXT(OBJ,4-/GG~2)
P_P(GG~2,5+)
WORD_C(1,2/5-) 5-(1,ALL)
........................
В фигурных скобках даны
комментарии. В конце приведен пример правила, выявляющего словосочетания типа
СУЩЕСТВИТЕЛЬНОЕ - СУЩЕСТВИТЕЛЬНОЕ в родит. падеже (КОГО). В системе имеются контекстные правила,
которые обеспечивают полный разбор предложений. Но в отличие от типовых
грамматик параллельно обеспечивается выделение значимых (информационных)
объектов, в том числе таких, в которых слова никак не согласованы между собой,
например, адресов, машин с указанием их номеров и т.д.
Описанные ЛП являются семантико-ориентированными, так как
они обеспечивают выделение объектов и связей между ними. Это семантические
компоненты. Такие ЛП нашли свое применение в системах нового класса -
"Аналитик", "Криминал" и др.