Semantic
Oriented Linguistic Processors
·
The Linguistic Processor provides the deep analysis of texts in natural
language with knowledge extraction, which are interested by users in his
subject fields. Process of text analysis by the Linguistic Processor is presented
on following pictures:
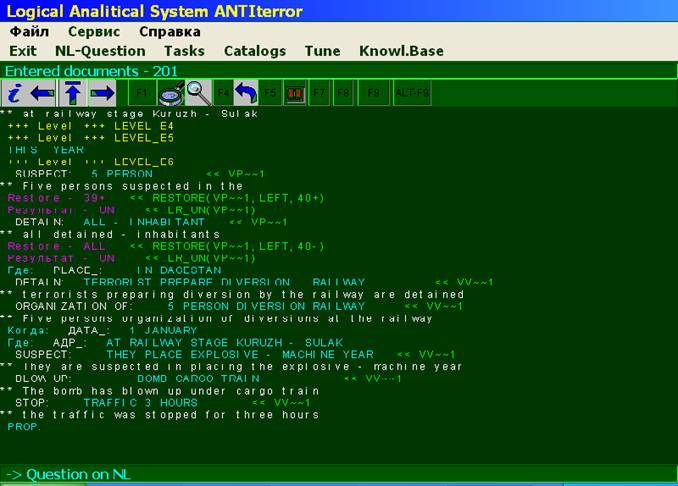
In the paper the new class of Semantic Oriented Linguistic Processors (LP) for knowledge extraction
from texts (about criminal events, correspondence of mass media and so on) are
considered. Processor LP transforms the texts to the structures of Knowledge
Base (KB). Processors LP select from texts the semantic significant information
which is interested by users, i.e. the information objects (named essences),
their quality and quantity characteristics and interconnections. For example, they
may be persons, their addresses, telephones, organizations and so on.
2. Components of Semantic Oriented Linguistic Processor
A variety of semantic search
forms is supported. The linguistic processor LP comprises the following components.
1) The component of
lexical and morphological analysis. It extracts words and sentences from
the text, performs lemmatization of words (normal form establishment) and
constructs the semantic network presenting the space structure of text (SpST),
which reflects the sequence of words, their basic features, beginnings of
sentences and the presence of space character lines. The component uses a
two-level general ontology and a special collection of subject dictionaries
(the dictionary of countries, regions of Russia, names, forms of weapons, and
other items specific for the supported domains). The component performs semantic
grouping of the words and assigns them additional semantic attributes.
2) The component of
syntactic-semantic analysis. It converts one semantic network (SN)
into another one which represents the semantic structure of text (SemST)
the, i.e., the relevant semantic entities and their connections. The SemST is
called the meaningful portrait of document. It comprises knowledge
structures of the knowledge base which serve the basis for implementing
different forms of semantic search : the search by features and connections,
the search for the entities connected at different levels, the search for
similar persons and incidents, the search by distinctive characteristics (with
the use of ontologies).
The component is
controlled by the linguistic knowledge (LK), which determines the process of text
analysis. LK includes special form of contextual rules which ensure the high
degree of selectivity with the extraction of entities and connections. The
functions of this component are as follows:
- Extraction of information objects from the
flow of NL documents: persons, organizations, actions, their place and time, and
many other relevant types of objects.
- The establishment of the connections of
between objects. For example, persons are connected with organizations
(PLACE_OF_WORK), by addresses (LIVES, REGISTERED). Or figurants of criminal
cases are connected with such objects as the type of weapon, drugs (TO HAVE).
- The analysis of finite and nonfinite verbal
forms with the identification of the participation of objects in the
appropriate actions. For example, one figurant gave drugs to another figurant,
and this is the fact linking them.
- The establishment of the connections of
actions with the objects by place or time (where and when some action or event
occurred).
- The analysis of the
reason-consequence and temporary connections between actions and events.
3) Expert system component
(ES). On the basis of semantic networks the new knowledge pieces are
constructed in the form of additional
fragments (ESN). For example, the ES extracts the area of a person
activity (in accordance with the assigned
classifier) from the text of resume for each autobiography. The
experience of the person’s work is
evaluated. The correlation of a criminal incident to the specific type is
accomplished with the analysis of the
criminal actions of ES: the following facts are revealed - the nature of crime,
the method of its accomplishment, the instrument, and so forth (in accordance
with the classifiers of the criminal police).
4) Reverse linguistic
processor, which converts the meaningful portrait of document (semantic
network) into NL-text (for users) or the XML- file (for KB). In this case the
necessary replacements of symbols, service words (names of objects) are achieved,
the markers of beginning and end of the objects, actions, sentences. Conversion
is achieved without the loss of information.
5) The base of linguistic
and expert knowledge (KB). It contains the rules of the text analysis and
expert solutions in the internal presentation. They determine the work of the
linguistic processor. Processor LP has several such bases, which are activated
depending on subject areas and user tasks.
3. The
Entities and Links for Extraction
The set of the entities to be
extracted depends on the tasks of a user. At the same time the quality of a linguistic
processor is to a considerable degree determined by the possibilities for this
extraction. The processor LP supports more than 40 types of semantic entities
which can be extracted automatically.
Some examples of basic
entities types and connections extracted by LP are given below:
• persons
(by family name, given name and patronymic - FNP) with their role features
(criminal, victim);
• the
verbal description of the persons, their distinctive signs;
• address,
posting information attributes;
• date(s)
mentioned;
• weapon
with its special features;
• telephone
numbers, faxes, e-mails with their subsequent standardization;
• the
means of transport with the indication of the vehicle type, its state number,
color and other attributes;
• passport
data and other documents with their attributes;
• explosives
and narcotic substances;
• organizations,
positions;
• quantitative
characteristics (how many persons or other objects participated in an event);
• the
numbers of accounts, sums of money with the indication of the currency type;
• terrorist
groups and organizations;
• participants
of terrorist groups with the indication of their roles (leader, head of, etc.);
• the
armed forces, assigned for antiterrorist combat (Military_.Force);
• event
(criminal, terrorist, biographical, and so on) with the indication of the
information objects participation in them;
• time
and the place of events;
• the connection between
different types of information objects (with whom a person works in an organization,
or lives at the same address, in what events participated together with other
objects, etc.).
For extracting objects all
versions of an object name including the contracted form possible in the text were
considered. Standard objects (names, dates, addresses, types of weapons and
others) are reduced to one (standard) form. The identification of objects is
performed taking into account brief designations (for example, separate
surnames, patronymics, initials), anaphoric references
(indicative and personal pronouns, for example, "this person",
"it...") definitions and explanations (for example, "the mayor
of Moscow Luzhkov" is identified with the subsequent words
"mayor", "Luzhkov"). For the extraction of events and connections
the analysis of verbal forms, participial and adverbial constructions is
carried out. An important task is the identification of entities in the entire
text, the use for these purposes of indicative pronouns, brief names, anaphoric references.
4. Factors
of Processor Quality
The quality of a linguistic processor is determined by a number of
factors.
The first one is the facility of entities and connections establishment.
The processor LP outperforms the existing systems by the number of the
supported semantic entities types. It identifies more than 40 types of entities
including very complex ones, which correspond to actions and events, for comparison
the competitors’ best result is about 15 types.
The second important factor
is the selectivity of rules and procedures of identification: the factor of the
noise and losses. By noise we mean the presence of excessive words in the
entities. Losses are the situations when an entity is not revealed or revealed
partially: in the text there are the words, which did not enter into the
entity. In the processor LP the rules are arranged in such a way that they
ensure the high degree of selectivity and the minimization of noise and losses
with the large number of the entities being selected.
The third factor is the
possibility and the labor expense for tuning to a corpus of texts (for
increasing the selectivity of rules for extraction of entities), and also
tuning to the new subject domains and types of entities. Due to the complexity
of analysis this tuning is achieved through the linguistic knowledge (LK).
The linguistic processor LP ensures the analysis of the Russian and
English language forms with the aid of the uniform language model.
The fourth factor is the
speed of linguistic processor operation, i.e., the time of text analysis. The
speed is determined by the design features of a processor (by means of search
time decrease), and also by the number of entities being extracted. The
application of rules of extraction is connected with the search for the necessary
words, where sorting is required. The greater is the number of entities and
rules the greater is the time of analysis. In the processor LP there are
different means of sorting time decrease.
Besides the program, there
are also means of control by linguistic knowledge. It is indicated for each
rule, what words should be searched for the initiation of the process of its
application. The constraints in the form of the expected contexts (to the left
and to the right of the revealed words) are assigned. These features ensure sufficiently
high speed (fractions of a second for 1 KB of text) with a sufficiently large
number of entities extracted.
The system features the
entire complex of means which ensure rapid tuning to the applications
(including the introduction of new entities and connections) taking into
account the demands of customers. Note that in the mentioned processors the
entities are brought to the standard form with the indication of the types of components.
A sufficiently in-depth analysis of sentences is conducted with the development
of verbal forms, and also with the identification of entities of the entire
text. The analysis of complex language structures is ensured: forms with verbal
nouns, participial and adverbial constructions, coordinated terms, etc. is
supported by the expert component. The processor LP can be used as a
stand-alone (independent) module. At present the first release of the English
language version of the information semantic-oriented linguistic processor LP
has been developed.