Материал из IpiranLogos.
Содержание |
Технологии извлечения и обработки знаний
Основные задачи лаборатории - построение новых классов экспертных и логико-аналитических систем, основанных на структурах знаний, и соответствено, Базах Знаний. Для этого разработаны средства представления знаний - расширенные семантические сети (РСС) и средства их обработки -
язык логического программирования ДЕКЛ. Они послужили основой для создания новых технологий, обеспечивающих автоматическое извлечение знаний их текстов на естественном языке (ЕЯ), формирование Баз Знаний и решение сложнейших задач логико-аналитической обработки путем преобразования и сопоставления структур знаний. Технологии носят достаточно универсальный характер и применимы к различным языкам (в настоящее время - к русскому и английскому, в перспективе - ко многим словянским и европейским языкам). На этой основе разработано множество интеллектуальных систем для различных приложений.
Отличительные особенности наших технологий:
1. Из текстов извлекаются не отдельные объекты (именованные сущности), а структуры знаний, представляющие связи объектов и их участие в действиях и событиях.
2. Для извлечения структур знаний разработан уникальный семантико-ориентированный лингвистический процессор (ЛП), осуществляющий глубинный анализ текстов ЕЯ и выявляющий десятки типов объектов вместе с их структурами.
3. Процессор ЛП управляется лингвистическими знаниями, представляющими собой декларативные структуры (на РСС) и обеспечивающие быструю
настройку ЛП на предметную область и язык.
4. Основой лингвистических знаний являются синтактико-семантические правила, осуществляющие глубинный анализ текстов и обладающие высокой степенью избирательности при выявлении объектов, средствами устранения коллизий при применении правил. Это позволяет минимизировать шумы и потери - добиваться высокой степени полноты и точности.
5. Структуры знаний (на РСС) и средства их обработки (язык ДЕКЛ) разрабатывались как единый инструментарий, ориентированный на задачи лингвистического анализа, семантического поиска, логико-аналитической обработки и экспертных решений. Использование этого инструментария значительно ускорило разработку
прикладных интеллектуальных систем.
Структуры знаний
Информационные объекты (ИО) - это то, что интересует пользователя в определенной предметной области. Например, следователей-аналитиков интересуют фигуранты, места их жительства, криминальные действия с указанием времени и места, используемое оружие, автосредства, наркотики и т.д. Все это ИО различных типов.
ИО извлекаются из документов на ЕЯ и представляются в Базе Знаний в виде фрагментов семантической сети (РСС), содержащих в качестве аргументов наборы нормализованных слов, чисел, знаков, отражающих сущность ИО и указывающих на его тип. Каждый фрагмент имеет свой уникальный код, который может быть аргументом других фрагментов. Например, фрагмент
FIO(ИВАНОВ,ИВАН,ИВАНОВИЧ,1957/2+)
представляет лицо с ФИО Иванов Иван Иванович 1957 года рождения. Тип ИО задается константой FIO. Знак "2+" - уникальный код фрагмента, соответствующий лицу. Знак "2-" есть ссылка на уникальный код (во внутреннем представлении эти знаки отображаются на одну и ту же вершину - внутреннюю константу). Такие коды необходимы для представления сложных структур знаний.
В наших системах из текстов ЕЯ выделяется более 40 типов ИО. Их количество зависит от предметной области и задач пользователя.
Понятие информационный объект (ИО) нам видится более широким и более правильным, чем общепринятое - именованная сущность (named entities). Отметим, что одни ИО могут быть компонентами других ИО. Их связи носят сложный характер. Связанные объекты образуют структуры, которые тоже являются ИО и могут быть связаны своими отношениями. Более того, многие ИО, выделяемые из текстов ЕЯ, редко именуются, гораздо чаще - сложным образом описываются с учетом связей их компонент.
{kind=link}
{kind=link}
Действия (обычно выражаемые в ЕЯ с помощью глагольных форм, причастных и деепричастных оборотов, форм с отглагольными существительными) - это тоже информационные объекты (ИО), компонентами которых могут быть другие ИО. Например, это могут быть лица, участвующие в действии, или предметы, на которые действие направлено. Более того, одни действия могут быть компонентами других. Для многих приложений действия - это значимая информация, требующая формализации.
{kind=link}
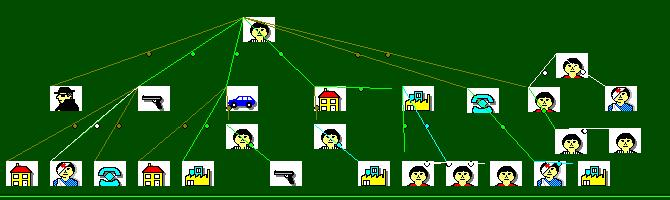
Связи или отношения между ИО, извлекаемые из текстов ЕЯ, могут быть весьма разнообразными. Они зависят от типов ИО. Например, лица могут быть связаны родственными, дружескими отношениями, а также по месту жительства, по интересам и т.д. Лица могут обладать определенным имуществом - это тоже ИО. Действия часто связываются с временем и местом. Между действиями могут быть причинно-следственные, временные и другие отношения. Возникают сложные структуры, для формализации которых требуются специальные средства представления знаний.
Связи могут быть прямыми (см. выше) и косвенными. Косвенные связи, когда один ИО связан с другим, а тот связан с третьим (связь между первым и третьим). Аналогично: связь первого с четвертым и т.д. Образуются цепочки связей, которые очень важны для многих аналитических решений, где устанавливаются связи между фигурантами (лицами) и другими объектами.
Содержательный портрет документа (текста на ЕЯ) - это формальное преставление ИО, их свойств и связей, выделенных из текста документа. Такие портреты - это и есть структуры знаний. В качестве средств формализации в наших технологиях используются расширенные семантические сети. Формализация осуществляется автоматически с помощью семантико-ориентированного лингвистического процессора, анализирующего тексты документов на ЕЯ и отображающего их на структуры знаний.
Семантико-ориентированный лингвистический процессор
Семантико-ориентированный лингвистический процессор (ЛП) проводит глубинный анализ текстов ЕЯ, из которых извлекаются ИО, их свойства, участие в действиях. На этой основе формируются структуры знаний, представляющих факты и ситуации с конкретизацией их компонент. Итак, в задачи процессора ЛП входит извлечение информационных объектов (в простейшем случае - именованных "сущностей") с их связями из документов на ЕЯ.
Семантико-ориентированный ЛП состоит из следующих блоков:
1. Блок лексико-морфологического анализа (ЛМА), выделяет из документа слова и предложения и выдает в виде семантической сети, называемой пространственной структурой документа и представляющей последовательность компонент (слов в нормальной форме, чисел, знаков) и их основные признаки. Блок ЛМА имеет три основных подсистемы:
- Лексический анализатор, который ответственен за правильное деление входного текстового потока на абзацы, предложения и слова (формирует лексические признаки слов);
- Морфологический анализатор, осуществляющий морфологический анализ всех слов текста (приводит слова в нормальную форму и формирует для них морфологические признаки).
- Систему предметных словарей, призванную распознать в тексте характерные термины (словарь стран, регионов России, городов имен собственных, профессий, организаций и др.) для придания словам и словосочетаниям дополнительных семантических признаков.
Блок ЛМА имеет свои лингвистические знания – средства параметрической настройки, позволяющие учитывать разнообразие текстовой типологии.
При настройке ЛП на другой язык (например, английский) требуется свой болок морфологического анализа, небольшое изменение блока лексического анализа и дополнение системы предметных словарей.
2. Блок синтактико-семантического анализа (ССА) путем анализа пространственной структуры документа выделяет объекты и связи. На их основе строит другую семантическую сеть, представляющую
содержательный портрет документа, называемый также семантической структурой документа. Этот блок включает в себя базу лингвистических знаний, которая содержит правила анализа текста во внутреннем представлении (в виде семантической сети - РСС). Они определяют работу ЛП.
Блок ССА управляется ЛЗ, за счёт которых обеспечивается:
- извлечение информационных объектов (лиц, организаций, действий, событий, их времени, места и т.д.);
- выявление связей объектов, например, связей лиц с организациями, адресами и др.;
- анализ глагольных форм, причастных и деепричастных оборотов с выявлением фактов участия объектов в тех или иных действиях;
- идентификация объектов с учетом анафорических ссылок и сокращенных наименований;
- выявление связей действий с их местом или временем (где и когда имело данное действие или событие).
Правила анализа текстов для различных языков имеют одну и туже структуру и записываются одной той же нотации, что значительно облегчает переход с одного языка на другой и делает возможным анализ смешанных русско-язычных текстов (где часть - на русском, часть - на английском).
3. Экспертные системы. На основе содержательного портрета документа формируют новые знания, которые дополняют этот портрет. Например, по автобиографии выявляют область деятельности лица, его специальность и др. Осуществляют соотнесение криминального происшествия к определенному типу (в соответствии с классификаторами криминальной милиции).
4. Блок построения каталогов объектов. Выделяет из содержательных портретов документов объекты определенного типа, которые упорядочиваются по алфавиту и образуют каталог. Например, таким способом создаются каталоги лиц (их ФИО), дат, адресов и др. - только тех, которые встретились в документах.
5. База лингвистических знаний. Содержит правила анализа текста во внутреннем представлении (в виде РСС). Они определяют работу ЛП.
Задачи логико-аналитических систем
Задачи решаются путем автоматического формирования Базы Знаний (на основе содержательных портретов документов) и ее использовании для решения поисковых и логико-аналитических задач. Такое решение сводится к сопоставлению и преобразованию структур знаний - содержательных портретов. Для этого создан язык логического программирования ДЕКЛ, конструкции которого обеспечивают преобразование структур. Все задачи решаются на структурном уровне.
---------------------------------------------
Технология семантического поиска информации в больших массивах документов на ЕЯ основана на использовании Базы Знаний (БЗ). Семантические поиски идут на уровне структур БЗ и включают в себя логический анализ признаков, связей. Например, поиск ответа на запросы в свободной форме (на ЕЯ) обеспечивается путем сопоставления содержательного портрета, построенного на основе запроса, и содержимого БЗ, т.е. сводится к поиску соответствующей структуры в БЗ. При этом широко используются онтологии, представленные в виде РСС, а также дополнительная информация, которая характеризует поисковый объект или ситуацию, но которая дается в тексте в неявной форме – как имплицитная информация, которую нужно восстанавливать.
Точный поиск информационных объектов.
Поиск похожих информационных объектов.
Поиск похожих объектов с учетом онтологий.
Поиск похожих действий и событий.
Навигация по связям.
Перечисленные виды семантического поиска реализованы в логико-аналитических системах "Криминал" и
"Аналитик".
Дополнительная литература.
---------------------------------------------
Система "Криминал" базируется на документах, поступающих из различных источников ОВД: сводки происшествий, объяснительные и служебные записки, записные книжки фигурантов, обвинительные заключения и др. По ним автоматически формируется База Знаний (БЗ), на основе которой (методами структурной обработки) осуществляется решение логико-аналитических задач:
- поиск похожих происшествий и фигурантов по информации в БЗ;
- поиск фигурантов по словесному портрету;
- поиск информации по запросам на ЕЯ (русском);
- объяснение результатов поиска;
- анализ и отображение связей между фигурантами;
- оценка степени причастности фигуранта к происшествию;
- упорядочение фигурантов по степени их криминальной и преступной активности;
- выявление организованных преступных формирований;
- статистическая обработка информации, выдача усредненных и оценочных данных, характеризующих динамику изменения криминогенных процессов во времени.
---------------------------------------------
Перед многими службами, имеющими дело с потоками текстовой информации, возникает проблема их формализации: необходимость представления в тех формах, которые приняты в этих службах и в рамках которых данная информация используется. Например, важная задача многих кадровых и рекрутинговых агентств связана с автоматической обработкой автобиографических данных, заявок на работу лиц (резюме, написанных в произвольной форме - на ЕЯ) с выделением всех необходимых данных этих лиц и формированием электроныых хранилищ (сайтов, БД, таблиц), обеспечивающих необходимые поиски.
---------------------------------------------
Разработана технология выявление новых свойств объектов, заданных в неявном виде. Предлагается методика такого выявления, основанная на анализе структур знаний. В качестве области приложения рассматривается задача выявления ролевых функций информационных объектов (лиц, организаций и др.)на базе их описаний. Эта задача в общем виде включает в себя всевозможные «оценки», «окраски». Например, оценка стабильности предприятия (по информации из Интернет), окраска политических деятелей (положительная или отрицательная в зависимости от высказываний о них в прессе), оценка качества изделия (по высказываниям пользователей) и т.д. Часто напрямую не говорится – это плохо, а это хорошо. Как правило, в текстах ЕЯ описываются события, ситуации, в которых участвовал тот или иной информационный объект. По ним и делается оценка, которая зачастую представляется в виде нового свойства объекта (ИО).
---------------------------------------------
Экспертные системы на основе анализа содержательных портретов соотносят документ к определенной категории (пункту классификатора). В наших системах реализовано два типа оболочек для экспертных систем. Первая основана на весовых коэффициентах слов, соответствующих определенной категории. Вторая - на наличии слов в информационных
объектах.
---------------------------------------------
6. Формирование аннотаций и отчетов
Осуществляется обратным лингвистическим процессором, который на основе содержательного портрета документа выделяет наиболее существенную часть. Это могут быть значимые информационные объекты и действия. Выделенная часть отображается на ЕЯ.